Clear Sky Science · es
Aplicación de redes neuronales profundas basadas en enjambres y modelos en ensamblaje para la reconstrucción de datos de conductancia específica
Por qué importa rellenar los huecos de datos
Las aguas costeras son la primera línea donde la actividad humana se encuentra con el océano. Los científicos monitorizan la salinidad de estas aguas mediante una medida llamada conductancia específica, que ayuda a detectar fugas de contaminación, cambios en el aporte de agua dulce y cambios ambientales a largo plazo. Pero los sensores fallan, las tormentas cortan la energía y los instrumentos tienen limitaciones. El resultado son frustrantes lagunas en registros clave, justo cuando los gestores e investigadores más necesitan datos continuos. Este estudio plantea una pregunta práctica: ¿puede la inteligencia artificial moderna “reparar” de forma fiable esos registros rotos para que las decisiones costeras se basen en información completa y de confianza?
Observando la respiración del Golfo
Los investigadores se centraron en el Golfo de México, uno de los mayores ecosistemas marinos del mundo y una región sometida a intensa presión industrial y agrícola. Utilizaron mediciones de cinco estaciones del Servicio Geológico de EE. UU. cercanas al río Pascagoula y al lago Mullet, cada una registrando la salinidad del agua (a través de la conductancia específica), la temperatura y el nivel del agua cada 15 minutos. Una estación, denominada E, tenía alrededor del 5% de sus datos de conductancia específica ausentes, exactamente el tipo de problema que afrontan las redes de monitoreo del mundo real. Los datos de las cuatro estaciones vecinas formaron una especie de red de seguridad ambiental: incluso cuando la estación E quedaba ciega, las demás seguían observando. La idea central fue enseñar a los modelos informáticos a aprender cómo “respiran” conjuntamente las cinco estaciones para que los huecos en un sitio puedan inferirse a partir de registros completos en las otras.
Poniendo a prueba algoritmos inteligentes
Para abordar esto, el equipo ensambló una alineación de diez enfoques de modelado diferentes. En un extremo estaban herramientas familiares como la regresión lineal múltiple, que intenta trazar relaciones en línea recta entre entradas y salidas. En el medio había modelos más flexibles como redes neuronales clásicas, sistemas de lógica difusa y una red de memoria a largo plazo (LSTM) especial, usada frecuentemente para series temporales. También emplearon un método autoorganizado llamado método de manejo de datos por grupos (GMDH) y una variante no lineal (NGMDH) que puede construir fórmulas multinivel por sí misma. Finalmente, incluyeron métodos basados en árboles: un único modelo de árbol de decisión (CART) y dos enfoques de “ensamblaje” —Random Forest y XGBoost— que combinan muchos árboles para tomar una decisión final, como un panel de expertos votando una respuesta.
Aprendizaje profundo impulsado por enjambres
Entrenar redes neuronales profundas es notoriamente complicado: sus numerosos controles y parámetros pueden quedar fácilmente atrapados en configuraciones pobres. Para mejorarlas, los autores emparejaron LSTM y NGMDH con un método de optimización reciente inspirado en el movimiento del agua, llamado optimización basada en flujo turbulento del agua (TFWO). En este esquema, cada posible conjunto de parámetros del modelo se imagina como una “partícula” que se mueve en un patrón tipo remolino a través del espacio de soluciones. A lo largo de muchos ciclos, las partículas son impulsadas hacia regiones que producen errores de predicción menores. Esta búsqueda de estilo enjambre hizo que ambos tipos de redes neuronales fuesen notablemente más precisos que sus versiones estándar, reduciendo sus errores medios en torno al 6–11%. Aun así, incluso estos modelos profundos mejorados acabaron siendo superados por los enfoques basados en árboles.
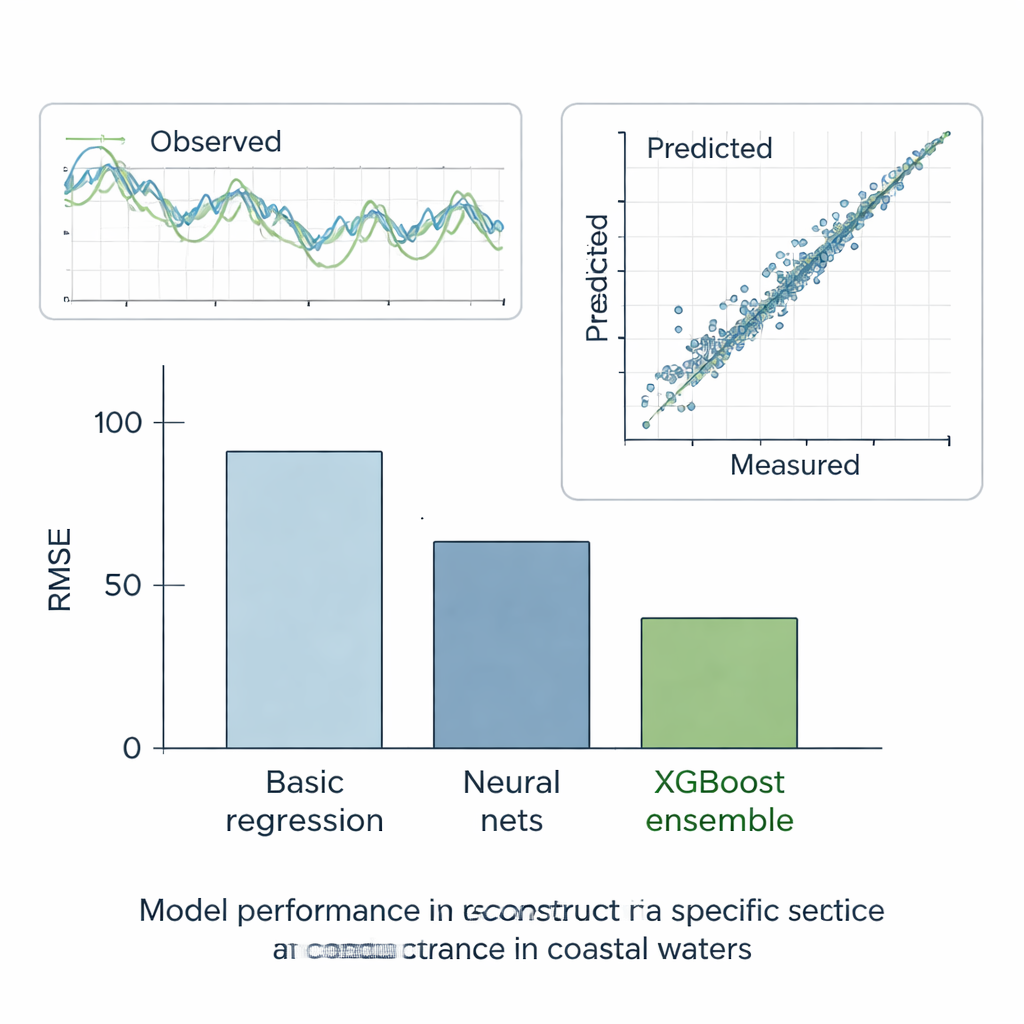
Los ensamblajes se imponen
Los autores probaron rigurosamente todos los métodos en seis escenarios. En cinco casos “qué pasaría si”, ocultaron fragmentos de registros por lo demás completos y comprobaron qué tan bien cada modelo podía reconstruir los valores faltantes. En el caso final, del mundo real, pidieron a los modelos que rellenaran los huecos reales en la estación E usando los datos de sus vecinas. A través de estas pruebas, el método más sencillo y lineal fue el que peor rendimiento ofreció, mientras que los modelos estándar de aprendizaje automático funcionaron mucho mejor, reduciendo el error aproximadamente a la mitad. Los árboles de decisión, que dividen automáticamente los datos en grupos más uniformes, mejoraron aún más. Pero el claro vencedor fue el ensamblaje XGBoost: al construir cientos de árboles que corrigen los errores de los anteriores, alcanzó un error extremadamente bajo y una concordancia casi perfecta entre la conductancia específica predicha y la medida. Sus reconstrucciones siguieron de cerca las series temporales observadas y reprodujeron el comportamiento estadístico general de los registros de calidad del agua.
Qué significa esto para las costas y más allá
Para no especialistas, la conclusión es sencilla: una IA cuidadosamente diseñada puede rellenar de forma fiable las piezas que faltan en los registros de calidad del agua costera, especialmente cuando hay estaciones cercanas que proporcionan contexto. Aunque las redes neuronales avanzadas son potentes, este estudio muestra que métodos en ensamblaje basados en árboles como XGBoost son aún más precisos y, en la práctica, pueden ser la mejor opción para reparar conjuntos de datos ambientales. Con herramientas robustas para rellenar huecos, los científicos pueden seguir mejor los cambios sutiles en la salinidad costera, identificar eventos de contaminación y apoyar decisiones de gestión sin verse descarrilados por las inevitables fallas de los sensores. Las mismas estrategias pueden adaptarse a muchos otros problemas de ingeniería y medioambientales donde los flujos de datos son abundantes, ruidosos y ocasionalmente incompletos.
Cita: Mahdavi-Meymand, A., Sulisz, W. & Nandan Bora, S. Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data. Sci Rep 16, 7292 (2026). https://doi.org/10.1038/s41598-026-38136-z
Palabras clave: calidad del agua costera, conductancia específica, aprendizaje automático, reconstrucción de datos faltantes, XGBoost