Clear Sky Science · es
Un nuevo modelo de ensamblado por apilamiento para predecir el coeficiente de descarga de compuertas radiales sumergidas múltiples en paralelo
Por qué importan compuertas de agua más inteligentes
En las zonas agrícolas irrigadas, las compuertas metálicas de los canales determinan discretamente quién recibe agua y cuándo. Si estas compuertas están aunque sea ligeramente mal calibradas, algunos campos se riegan en exceso mientras que otros quedan secos, desperdiciando un recurso escaso y perjudicando los cultivos. Este estudio aborda ese problema oculto empleando aprendizaje avanzado por ordenador para facilitar y mejorar considerablemente la predicción del flujo a través de esas compuertas, sin necesidad de ecuaciones complejas ni de prueba y error en el campo.
Un desafío oculto dentro de las compuertas de canal
Las redes modernas de riego dependen en gran medida de las llamadas compuertas radiales, puertas de acero curvadas que se pueden subir o bajar para regular la cantidad de agua que pasa aguas abajo. En muchas condiciones reales, estas compuertas funcionan estando “sumergidas”, es decir, con niveles de agua elevados tanto en el lado aguas arriba como en el aguas abajo. En esta situación, una magnitud clave llamada coeficiente de descarga determina cuánta agua pasa realmente por debajo de una compuerta parcialmente abierta. Los métodos tradicionales para calcular este coeficiente son complicados, dependen de muchas suposiciones y pueden fallar por decenas de puntos porcentuales cuando la compuerta está sumergida. Para ingenieros y gestores del agua, estas inexactitudes se traducen directamente en un control deficiente de las entregas a las fincas.
Enseñando a un modelo con datos reales de ríos
Los investigadores recurrieron al aprendizaje automático, permitiendo que los ordenadores aprendan patrones directamente de las mediciones en lugar de depender sólo de fórmulas elaboradas a mano. Reunieron 782 puntos de datos de tres grandes reguladores en el delta del Nilo, cada uno con múltiples compuertas curvas que sirven a centenares de miles de hectáreas. Para cada condición de operación registraron los niveles de agua aguas arriba y aguas abajo, la apertura y la geometría de la compuerta, y el caudal resultante. Luego convirtieron estos datos en razones sencillas —por ejemplo, qué tan profunda es el agua río abajo en comparación con río arriba— para que el modelo pudiera centrarse en los aspectos más influyentes del comportamiento de la compuerta. Trabajos anteriores ya habían mostrado que la razón entre la profundidad aguas abajo y aguas arriba es especialmente importante, y este nuevo análisis confirmó que es el predictor individual más potente del rendimiento de la descarga.
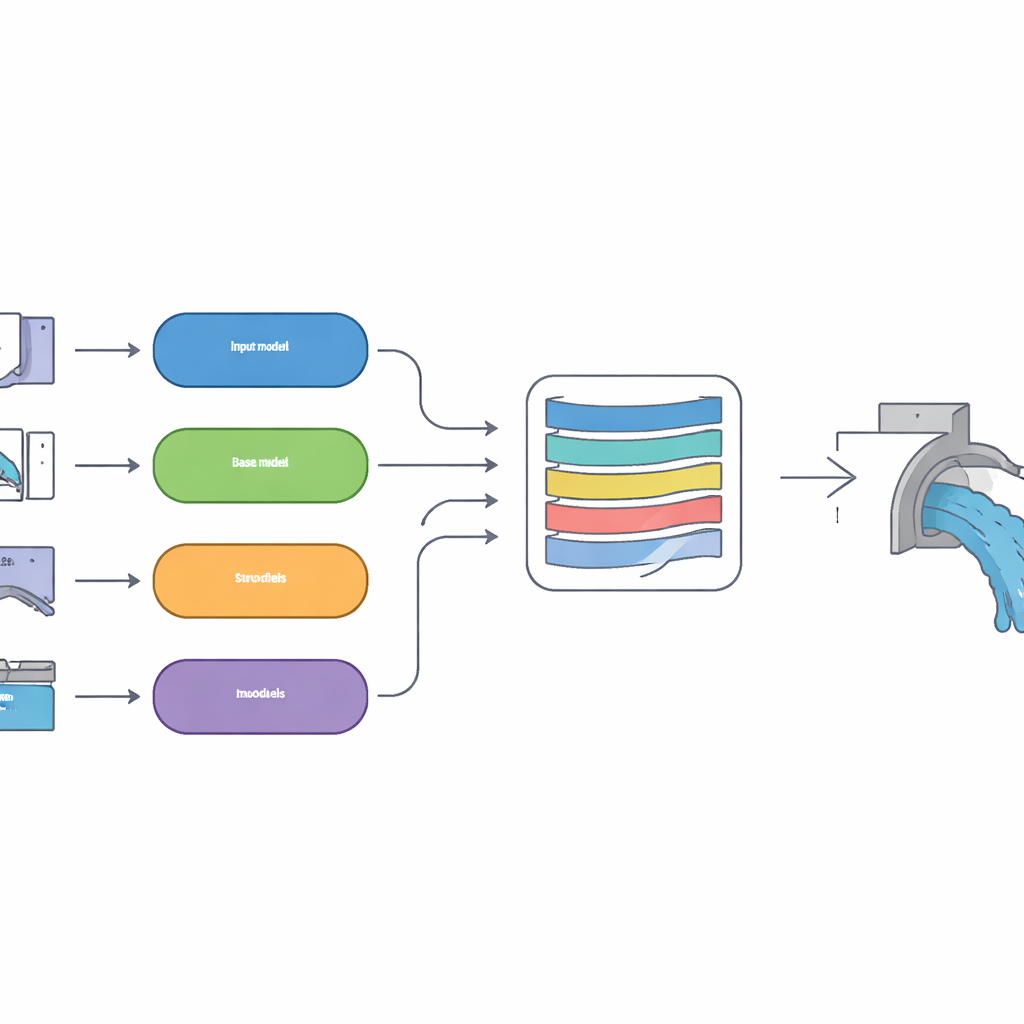
Muchas mentes, una respuesta final
En lugar de apostar por un único método de aprendizaje, el equipo construyó un enfoque de “apilamiento” que combina varias herramientas de predicción diferentes. Cuatro modelos base, cada uno usando un estilo distinto de reconocimiento de patrones, generan primero sus propias estimaciones del coeficiente de descarga. Estos incluyen métodos buenos expresando incertidumbre, métodos que funcionan bien con curvas complejas y métodos que destacan en captar relaciones sutiles. Sus salidas se introducen luego en un modelo de aprendizaje profundo de nivel superior conocido como red de memoria a largo plazo (LSTM), equipada con un mecanismo de atención. Esta capa superior aprende cuánto confiar en cada modelo base bajo distintas condiciones de flujo, de forma parecida a un ingeniero experimentado que pondera múltiples opiniones de expertos antes de decidir un valor final.
¿Qué tan bien funciona?
El sistema combinado fue entrenado y probado usando una validación cruzada cuidadosa, donde los datos se dividen repetidamente en grupos separados de aprendizaje y comprobación para evitar el sobreajuste. En estas pruebas, el modelo ensamblado produjo de forma constante coeficientes de descarga que coincidieron extremadamente bien con las mediciones de campo. Su error típico fue de sólo unos pocos puntos porcentuales, y superó a cada modelo base individual así como a varias técnicas tradicionales de regresión ampliamente usadas. Las comparaciones visuales mostraron que las predicciones del modelo caían casi exactamente sobre la línea ideal uno a uno con los valores observados, lo que indica que mantuvo la precisión en todo el rango de condiciones operativas observadas en los canales.
Qué significa esto para los canales reales
Para los no especialistas, la conclusión práctica es sencilla: al permitir que varios métodos de aprendizaje “voten” y luego enseñar a un árbitro final inteligente a ponderar esos votos, los ingenieros pueden predecir con alta fiabilidad cuánta agua pasará por compuertas radiales sumergidas. Dado que las entradas necesarias son sólo niveles de agua, aperturas de compuerta y dimensiones fijas de la compuerta —valores ya medidos en la mayoría de los sistemas automatizados de canales—, el método puede integrarse en el software de control existente como una herramienta de apoyo a la decisión. Usado con prudencia dentro del rango de condiciones en el que fue entrenado, este tipo de modelo ensamblado inteligente puede ayudar a las agencias de riego a distribuir el agua con más equidad, reducir el desperdicio y responder con mayor seguridad a la demanda cambiante y a las presiones sobre los ríos inducidas por el clima.
Cita: Abdelazim, N.M., Hosny, M., Abdelhaleem, F.S. et al. A novel stacking ensemble model for predicting discharge coefficient of submerged multi parallel radial gates. Sci Rep 16, 7953 (2026). https://doi.org/10.1038/s41598-026-38117-2
Palabras clave: canales de riego, compuertas radiales, aprendizaje automático, gestión del agua, predicción de caudal