Clear Sky Science · es
UncerTrans: transformador temporal consciente de la incertidumbre para la predicción temprana de acciones
Por qué ver las acciones temprano puede mantenernos a salvo
Imagínese un robot doméstico que, con solo el primer movimiento de muñeca, pueda decir si alguien está a punto de verter agua caliente de forma segura en una taza o de volcar accidentalmente la tetera. En fábricas, hospitales y hogares inteligentes, las máquinas cada vez comparten más espacio con las personas, y reaccionar solo después de que empieza un accidente llega demasiado tarde. Este artículo presenta UncerTrans, un nuevo sistema de IA que no solo predice qué es lo que probablemente hará una persona basándose en el inicio de una acción, sino que además nos dice cuán seguro está de su propia suposición—una capacidad vital cuando la seguridad humana está en juego.
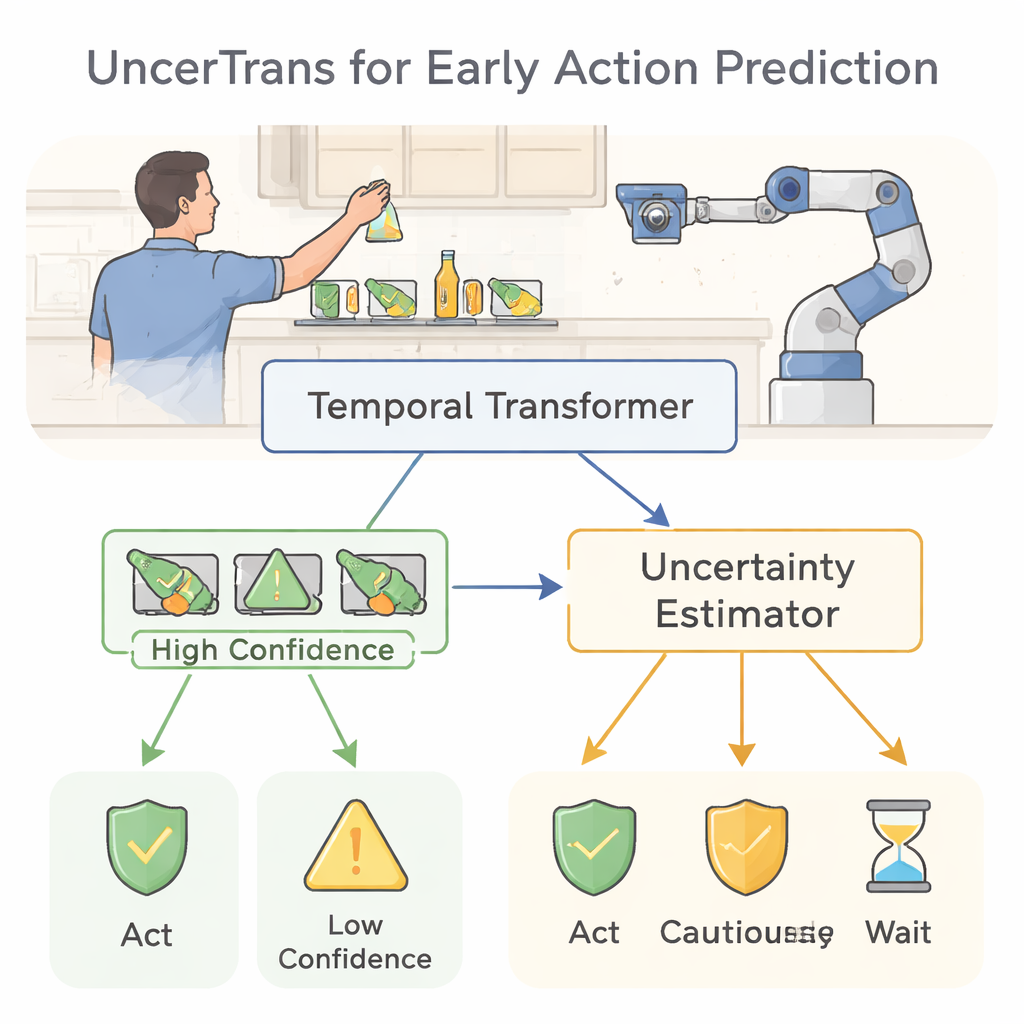
De observar a prever acciones humanas
La mayoría de los sistemas actuales de visión por ordenador reconocen lo que alguien está haciendo solo cuando la acción está casi terminada: clasifican un clip de vídeo completo como “cortando verduras” o “recogiendo una taza”. Eso sirve para análisis posteriores, pero no para prevenir quemaduras, colisiones o caídas. La predicción temprana de acciones aborda un problema más difícil: decidir qué acción completa vendrá después de ver solo el 10–20% de ella. El desafío es que muchas acciones se parecen al principio—alcanzar una tetera podría significar verter una bebida o volcarla—por lo que un sistema debe operar con poca información y aun así evitar errores peligrosos.
Enseñar a la máquina a fijarse en los momentos adecuados
UncerTrans aborda esto usando un transformador temporal, una arquitectura neuronal moderna desarrollada originalmente para el lenguaje. En lugar de leer palabras en una frase, mira pequeños fragmentos de vídeo a lo largo del tiempo. El modelo divide una secuencia de acción temprana en unos pocos segmentos y utiliza un mecanismo de atención para decidir qué momentos importan más. Los fotogramas recientes reciben un peso adicional, lo que refleja nuestra intuición de que el movimiento más reciente suele revelar la intención más clara. Este diseño permite al sistema captar tanto detalles finos, como el movimiento de los dedos, como patrones más amplios, como la trayectoria de un brazo, incluso cuando solo ve una fracción de la acción completa.
Conseguir que una máquina admita cuando no está segura
Una innovación clave de UncerTrans es que no se queda en una única respuesta tajante. En su lugar, procesa la misma entrada varias veces, ligeramente distinta, usando una técnica llamada Monte Carlo dropout. Cada pasada elimina al azar diferentes conexiones internas, produciendo una predicción algo distinta. Al observar cuánto difieren esas predicciones, el sistema puede estimar su propia incertidumbre: predicciones estrechamente agrupadas señalan alta confianza, mientras que las dispersas indican duda. UncerTrans además separa la incertidumbre causada por una experiencia de entrenamiento limitada del ruido presente en el propio vídeo, y ajusta sobre la marcha cuántas ejecuciones de prueba realiza—usando más cuando las primeras muestras parecen ambiguas y menos cuando ya coinciden.
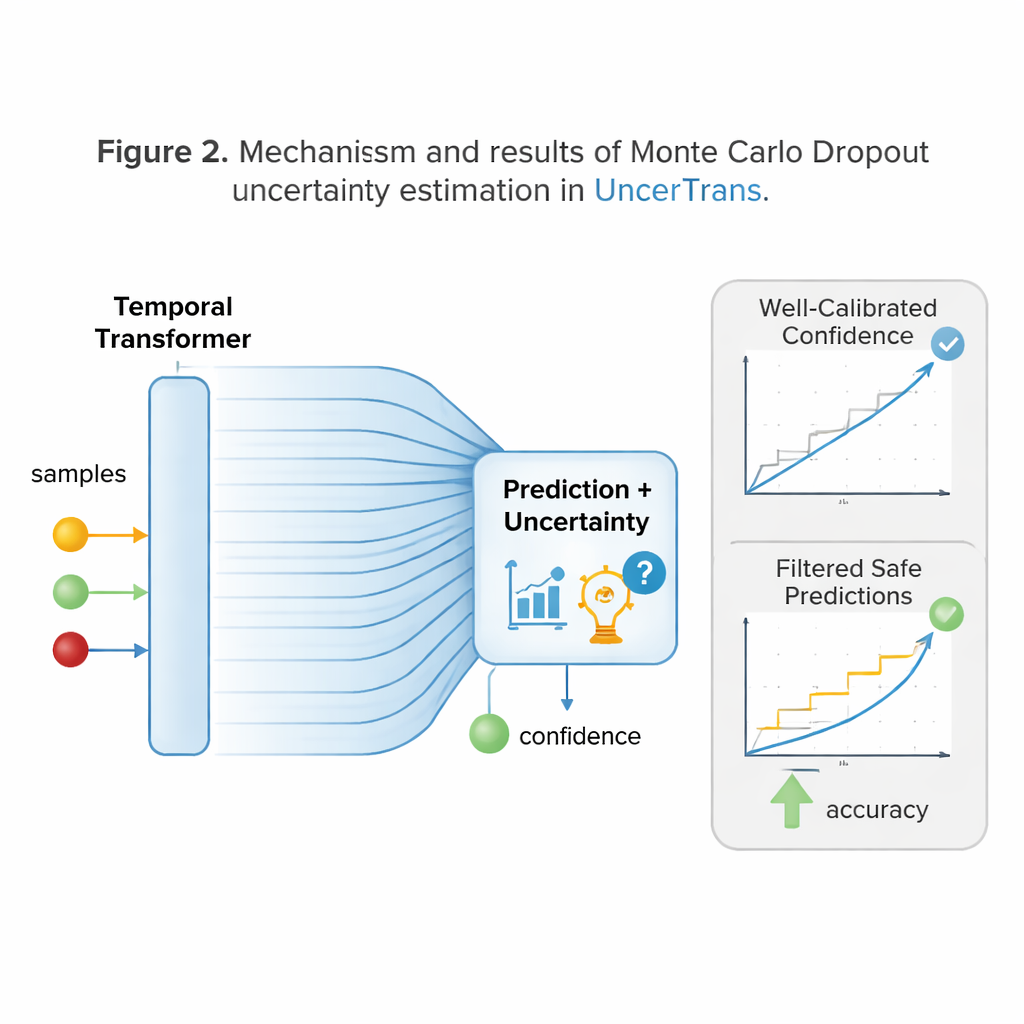
Convertir la confianza en decisiones más seguras
Saber cuándo puedes estar equivocado solo es útil si cambia tu conducta. UncerTrans convierte sus estimaciones de confianza en elecciones prácticas. Para predicciones con baja incertidumbre, el sistema puede actuar con decisión—por ejemplo, activando una alarma o moviendo un brazo robótico fuera de una zona de peligro. Cuando la incertidumbre es moderada, puede optar por comportamientos conservadores y más seguros, como desacelerar un robot o pedir más información. Si la incertidumbre es muy alta, puede negarse a decidir y simplemente seguir observando. Pruebas en un gran conjunto de vídeos en primera persona en cocina muestran que UncerTrans predice acciones próximas con mayor precisión que varias alternativas sólidas, especialmente cuando solo es visible el primer 10% de la acción. Notablemente, cuando descarta solo el 30% de los casos más inciertos, la precisión en las predicciones restantes sube hasta aproximadamente un 84%, lo que demuestra el valor real del filtrado consciente de la incertidumbre.
Qué significa esto para el trabajo cotidiano entre humanos y robots
Para un público no especializado, el mensaje es sencillo: UncerTrans es un paso hacia máquinas que no solo adivinan nuestro siguiente movimiento a partir de pistas limitadas, sino que además saben cuándo esas conjeturas son fiables. Al combinar un modelo visual sensible al tiempo con un “medidor de confianza” interno, el sistema puede reaccionar más rápido y con mayor seguridad en entornos reales y desordenados como cocinas, fábricas y centros de atención. Aunque el método aún conlleva costes computacionales y requerirá más refinamiento, ofrece un plano prometedor para futuros robots y sistemas de vigilancia que anticipen peligros de forma temprana, respondan con cautela cuando haya dudas y, en última instancia, se integren de forma más segura en los espacios humanos.
Cita: Zhai, X., Liu, Y. UncerTrans: uncertainty-aware temporal transformer for early action prediction. Sci Rep 16, 7068 (2026). https://doi.org/10.1038/s41598-026-38107-4
Palabras clave: predicción temprana de acciones, colaboración humano-robot, incertidumbre en IA, modelos transformadores para visión, sistemas inteligentes seguros