Clear Sky Science · es
Generación de muestras límite para analizadores de aleatoriedad mediante optimización inteligente y algoritmos evolutivos
Por qué lo casi aleatorio importa para la seguridad cotidiana
Cada vez que compras en línea, desbloqueas tu teléfono o envías un mensaje privado, se lanzan dados matemáticos invisibles para mantener tus datos a salvo. Esos dados toman la forma de largas cadenas de bits supuestamente aleatorios que se usan como claves criptográficas. Si esos bits son incluso un poco menos aleatorios de lo que deberían, atacantes persistentes pueden a veces encontrar patrones explotables. Este artículo explora una nueva forma de fabricar secuencias de prueba “casi aleatorias”: datos que parecen extremadamente aleatorios pero ocultan pequeños fallos, de modo que los ingenieros puedan someter a prueba con rigor los dispositivos que protegen nuestra vida digital.
Cuando los números aleatorios no son lo bastante aleatorios
Los sistemas de seguridad modernos dependen de dos tipos de generadores de números aleatorios. Los generadores verdaderamente aleatorios aprovechan efectos físicos impredecibles, como el ruido electrónico o las fluctuaciones cuánticas, mientras que los generadores pseudoaleatorios usan algoritmos que convierten semillas cortas y aleatorias en secuencias largas. En la práctica, la calidad de ambos depende en última instancia de la fuente física de imprevisibilidad, llamada fuente de entropía. Lamentablemente, las fuentes de entropía del mundo real son frágiles: cambios de temperatura, envejecimiento del hardware o errores de diseño pueden reducir silenciosamente su aleatoriedad. Para detectar esos problemas, organismos de normalización como NIST definen baterías de pruebas estadísticas que comprueban si los bits de salida parecen lo bastante aleatorios. Cada vez más, los dispositivos incorporan “probadores de aleatoriedad en tiempo real” que monitorizan su propia salida mientras funcionan. Sin embargo, no ha habido una buena manera de generar casos de fallo realistas y difíciles de detectar para comprobar si esos comprobadores integrados realmente funcionan.
Diseñar secuencias que apenas suspenden las pruebas de aleatoriedad
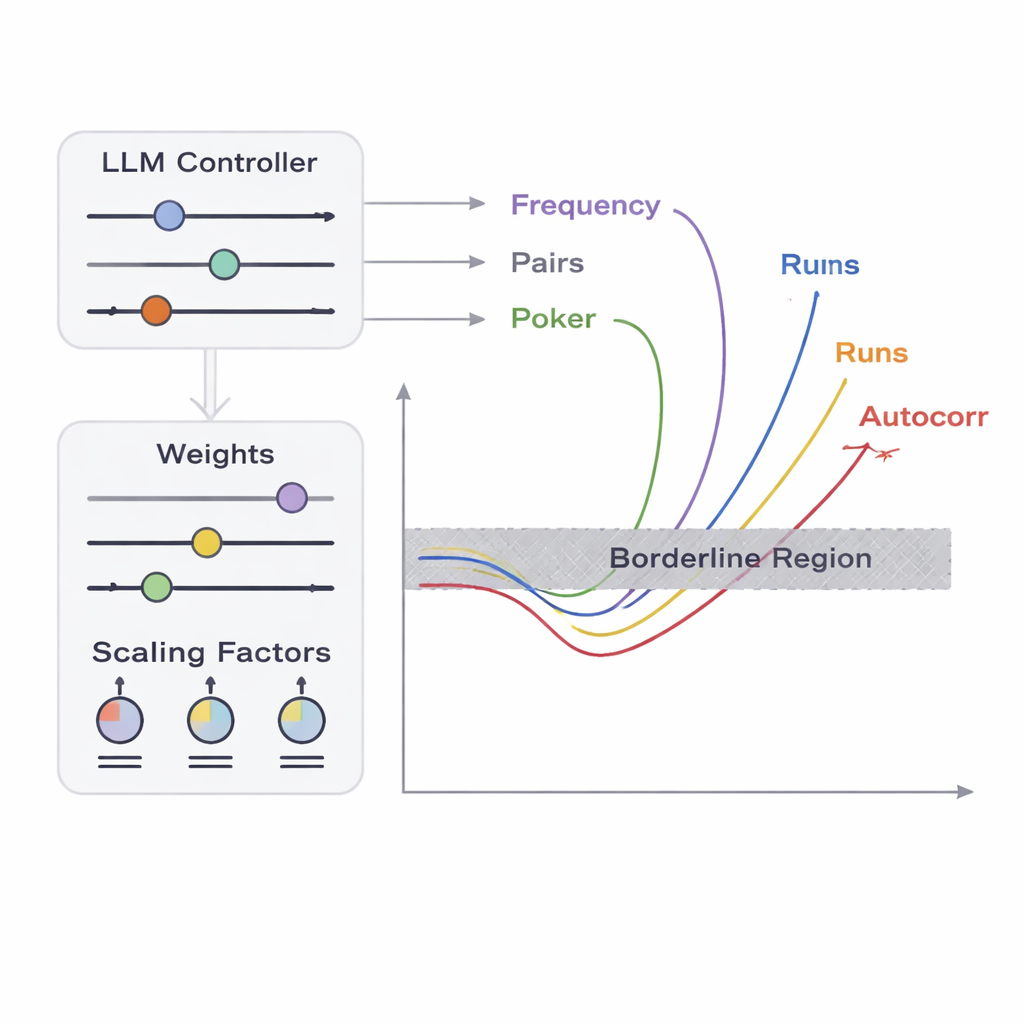
Desde el punto de vista de un probador, los fallos triviales —como salidas que son todo ceros— son fáciles de detectar. El verdadero desafío es identificar casos límite: secuencias que son casi indistinguibles de la aleatoriedad ideal pero que fallan apenas una o más comprobaciones estadísticas. Los autores se centran en cinco pruebas clásicas que examinan distintos aspectos de los patrones de bits, incluyendo la frecuencia de ceros y unos, el comportamiento de pares de bits, la distribución de ciertos patrones cortos, cómo se correlacionan los bits con copias desplazadas de sí mismos y la distribución de longitudes de rachas de bits idénticos. Definen una “zona límite” para cada prueba: una banda estrecha donde los datos solo violan ligeramente los umbrales habituales de aceptación. Producir una secuencia larga que caiga simultáneamente dentro de todas estas bandas estrechas es extremadamente improbable por azar, porque las pruebas interactúan de formas complicadas y no lineales. Aquí es donde entran la optimización y la IA.
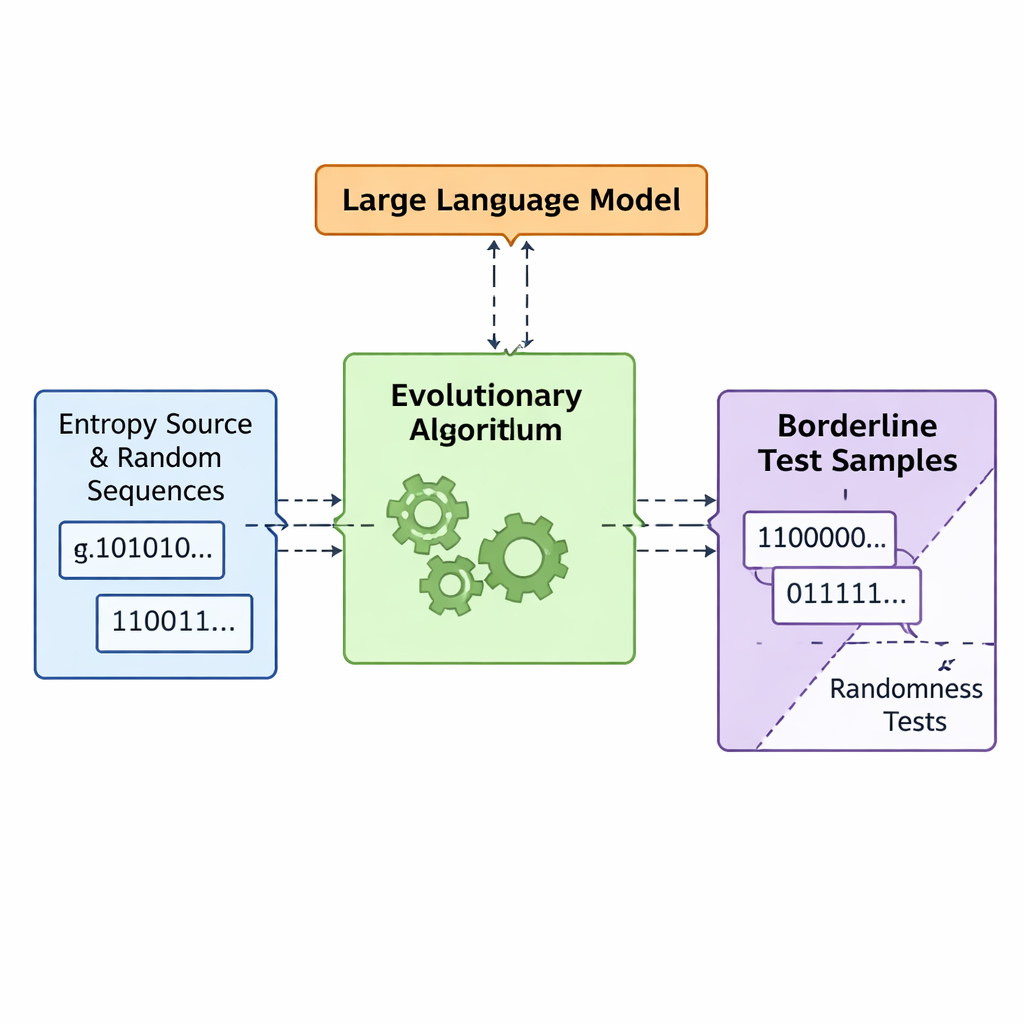
Dejar que la evolución y los modelos de lenguaje codiseñen una mala aleatoriedad
El equipo presenta un marco llamado APAM‑IGLLM que trata la generación de secuencias como un problema de optimización en alta dimensión. Cada secuencia candidata es una cadena de bits, y su “aptitud” mide qué tan cerca está de las zonas límite de las cinco pruebas. Un algoritmo genético muta y recombina repetidamente estas secuencias, conservando las que se acercan más a la región objetivo. Encima de esto, un modelo de lenguaje a gran escala (LLM) actúa como una especie de entrenador estratégico. En cada generación examina estadísticas resumidas de la población y el historial a corto plazo, y sugiere cómo ajustar perillas internas —pesos y factores de escala que deciden con qué fuerza cada prueba influye en la aptitud. Esto crea un bucle de retroalimentación: el algoritmo genético explora el espacio de secuencias posibles, mientras el LLM guía la búsqueda para que las cinco puntuaciones de las pruebas converjan hacia la pequeña intersección donde las secuencias son apenas no aleatorias.
¿Qué tan parecidas a la aleatoriedad perfecta pueden parecer los datos defectuosos?
Para comprobar si sus fallos artificiales parecen realistas, los autores comparan sus secuencias generadas con puntos de referencia ampliamente usados. Calculan tanto la entropía de Shannon como la min‑entropía, medidas de cuán impredecible parece cada byte, y encuentran valores alrededor de 7,6–8 bits por byte —muy cerca del máximo teórico de 8 y similares a fuentes de aleatoriedad por hardware comerciales y al propio beacon público de aleatoriedad de NIST. También ejecutan la suite completa de pruebas estadísticas NIST SP 800‑22 y observan que sus secuencias límite pasan y fallan en un patrón casi idéntico al de datos aleatorios genuinamente de alta calidad. En otras palabras, para las herramientas estándar estas muestras parecen esencialmente normales, aunque fueron diseñadas deliberadamente para situarse cerca de múltiples umbrales de fallo. Esto las convierte en entradas “adversarias” ideales para comprobar cuán robustos son realmente los probadores de aleatoriedad integrados.
Qué implica esto para la seguridad del mundo real
Desde la perspectiva de un público general, este trabajo ofrece una nueva forma de verificar la seguridad de la maquinaria de números aleatorios que sustenta la criptografía. En lugar de probar los dispositivos solo con aleatoriedad claramente rota o claramente sana, los ingenieros pueden ahora bombardearlos con secuencias cuidadosamente elaboradas y casi buenas que imitan fallos sutiles de hardware o deriva ambiental. Si un probador de aleatoriedad en tiempo real pasa por alto estos casos límite, eso señala un posible punto ciego que debería corregirse antes de desplegar el dispositivo en banca, comunicaciones seguras o sistemas de blockchain. Al usar búsqueda evolutiva guiada por un modelo de lenguaje, los autores proporcionan una herramienta práctica para generar datos de prueba tan exigentes, ayudando a impulsar los cimientos ocultos de la seguridad digital hacia mayores niveles de fiabilidad.
Cita: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
Palabras clave: generadores de números aleatorios, fuentes de entropía, algoritmos evolutivos, modelos de lenguaje a gran escala, pruebas criptográficas