Clear Sky Science · es
Corrección de etiquetas ruidosas mediante destilación comparativa: un enfoque de adaptación de dominio
Por qué los datos desordenados son un problema creciente
La inteligencia artificial moderna prospera gracias a los datos, pero esos datos con frecuencia están equivocados, incompletos o etiquetados de forma inconsistente. Cuando las etiquetas son ruidosas —por ejemplo, una foto de un gato etiquetada como perro— los sistemas de aprendizaje pueden verse engañados, volviéndose menos precisos y menos fiables. Este artículo aborda ese problema del mundo real: cómo entrenar sistemas de reconocimiento de imágenes que sigan funcionando bien incluso cuando las etiquetas de entrenamiento son defectuosas y las imágenes proceden de entornos distintos, como tiendas en línea frente a fotografías del mundo real.
Aprender entre mundos diferentes
En la práctica, los modelos de IA suelen aprender en un «mundo fuente» donde las etiquetas están cuidadosamente verificadas y luego deben rendir en un «mundo objetivo» donde las etiquetas escasean y son propensas al error. Por ejemplo, objetos de oficina fotografiados en estudio son ordenados y correctamente etiquetados, mientras que fotos con webcam o cotidianas de los mismos objetos son desordenadas y etiquetadas de forma inconsistente. Los métodos tradicionales de adaptación de dominio intentan salvar esta brecha alineando las estadísticas generales de ambos mundos. Sin embargo, normalmente asumen que las etiquetas del dominio objetivo, cuando están disponibles, son correctas —una suposición arriesgada que falla en aplicaciones reales con etiquetas crowdsourced, sensores de baja calidad o herramientas de anotación automática.
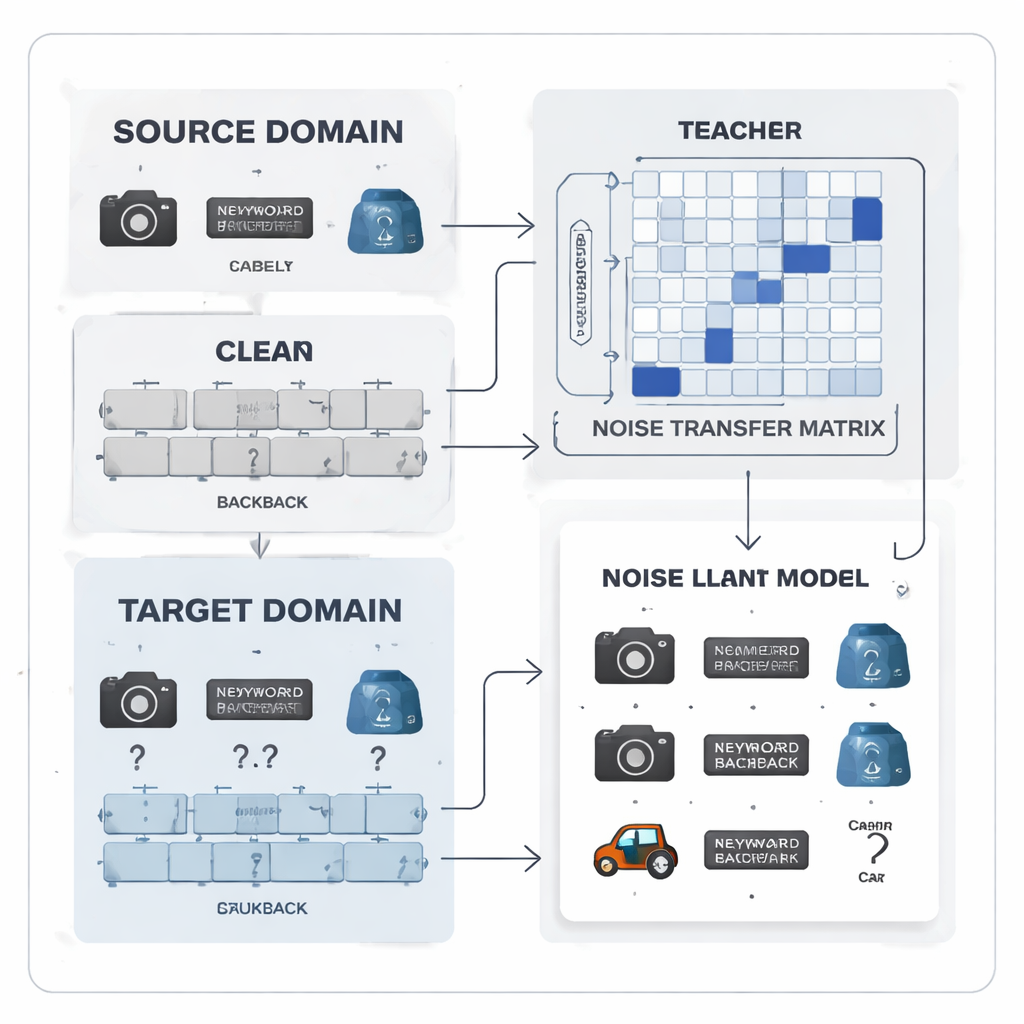
Convertir los errores de etiqueta en un patrón aprendible
Los autores proponen tratar el ruido de las etiquetas no como un caos aleatorio sino como un patrón que puede aprenderse. Introducen una «matriz de transferencia de ruido», una tabla que captura cuán probable es que cada clase verdadera sea mal etiquetada como otra. En lugar de estimar esta tabla a partir de unos pocos ejemplos perfectos «ancla» —lo que resulta poco realista cuando las etiquetas son ruidosas y las clases están desequilibradas—, la matriz se aprende directamente durante el entrenamiento. Para arrancar el aprendizaje, el método construye «prototipos» de categoría, huellas medias de características para cada clase extraídas por un modelo preentrenado potente. La similitud entre estos prototipos se usa para inicializar la matriz de modo que las categorías fácilmente confundibles, como herramientas de oficina similares, estén más fuertemente vinculadas desde el principio, proporcionando al sistema una capacidad temprana para corregir etiquetas.
Trabajo en equipo profesor‑estudiante para señales más limpias
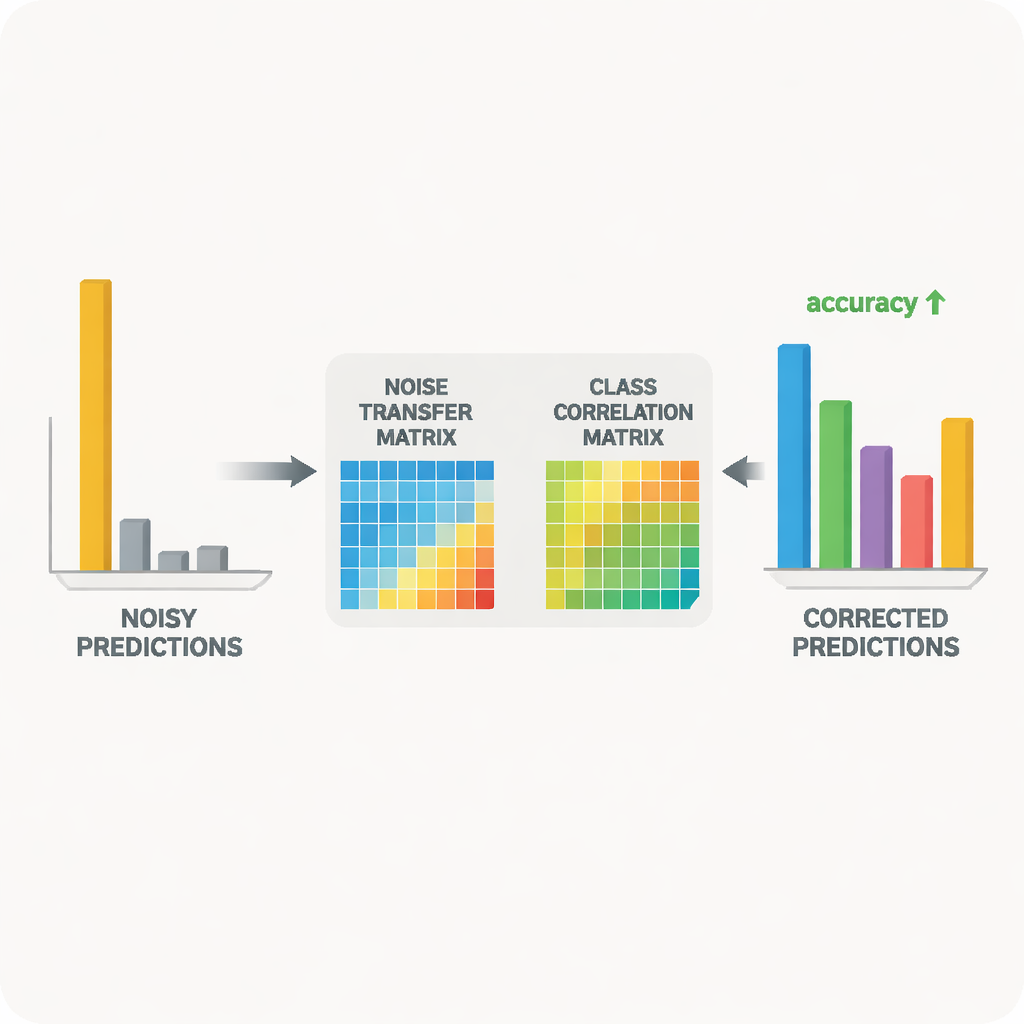
En el corazón del sistema hay un par profesor‑estudiante de redes neuronales. El profesor se basa en un gran modelo visual auto‑supervisado que ha aprendido ricas características visuales a partir de enormes cantidades de datos no etiquetados. El estudiante es una red más ligera que debe rendir bien en los datos objetivo ruidosos. El profesor produce puntuaciones de predicción suaves que revelan qué tan relacionadas están las distintas clases; a partir de estas puntuaciones, el método construye una matriz de correlación de clases que resume qué etiquetas tienden a coocurrir. Esta matriz actúa como guía, empujando la matriz de transferencia de ruido hacia correcciones más realistas. Al mismo tiempo, el estudiante se entrena para imitar el comportamiento del profesor mediante un proceso conocido como destilación, mientras que el aprendizaje contrastivo anima a ambas redes a dar representaciones internas similares para distintas vistas aumentadas de la misma imagen y representaciones distintas para objetos diferentes.
Mantener las correcciones estables y evitar la sobreconfianza
Permitir simplemente que la matriz de transferencia de ruido cambie libremente podría hacerla inestable o excesivamente sensible a valores atípicos. Para evitarlo, los autores usan un truco matemático basado en la descomposición en valores singulares, que descompone la matriz en direcciones básicas de estiramiento. Al penalizar el «volumen» global implicado por estas direcciones, el método desalienta distorsiones extremas que amplificarían el ruido. Otro problema surge cuando el modelo se vuelve demasiado seguro, asignando casi toda la probabilidad a una única clase; con predicciones tan agudas, resulta difícil corregir etiquetas erróneas. Para ello, el método añade una forma de regularización de la entropía, basada en la entropía de Tsallis, que mantiene las probabilidades de predicción más suaves. Esto facilita que la matriz de transferencia de ruido reasigne parcialmente masa de probabilidad desde una clase incorrecta hacia alternativas más plausibles.
Demostrar la idea en colecciones reales de imágenes
Los investigadores probaron su enfoque en dos benchmarks ampliamente usados para el reconocimiento de objetos entre dominios: Office‑31 y Office‑Home, que incluyen imágenes de objetos de oficina cotidianos en múltiples estilos como fotos de producto, clip art y instantáneas del mundo real. En una variedad de tareas de «entrenar en un estilo, evaluar en otro», su método igualó o superó a los algoritmos líderes, especialmente en los casos más difíciles donde el cambio entre dominios es mayor. Estudios detallados mostraron que cada componente —el control de volumen para la matriz de ruido, la guía de correlación de clases y el suavizado por entropía— aportó ganancias medibles. Visualizaciones de la matriz aprendida y del espacio de características confirmaron que, a lo largo del entrenamiento, los ejemplos mal etiquetados se fueron acercando gradualmente a sus categorías correctas y que las distribuciones de imágenes fuente y objetivo quedaron mejor alineadas.
Qué significa esto para los sistemas de IA cotidianos
Para un no especialista, la conclusión clave es que este trabajo hace a los modelos de IA más indulgentes frente a errores humanos y de máquinas en la etiquetación de datos, en particular cuando esos modelos deben pasar de condiciones limpias de laboratorio a entornos reales más desordenados. Al aprender explícitamente cómo tienden a fallar las etiquetas y usando un modelo profesor potente para guiar las correcciones, el método puede limpiar las señales ruidosas de entrenamiento y producir clasificadores más precisos y robustos. Aunque el enfoque requiere computación adicional, apunta hacia un futuro en el que grandes conjuntos de datos imperfectos recolectados «en libertad» puedan aprovecharse de forma más segura y eficaz, reduciendo nuestra dependencia de la anotación manual meticulosa.
Cita: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
Palabras clave: etiquetas ruidosas, adaptación de dominio, destilación de conocimiento, clasificación de imágenes, aprendizaje semi‑supervisado