Clear Sky Science · es
Críticos distribucionales gemelos sensibles al riesgo con una cota inferior de confianza lambda para aprendizaje por refuerzo en control continuo
Enseñar a los robots a ser cautelosos
Muchos de los robots y programas de juego más impresionantes de hoy en día dependen del aprendizaje por refuerzo, un proceso de entrenamiento por prueba y error en el que agentes de software aprenden recogiendo recompensas. Pero estos agentes con frecuencia persiguen la puntuación más alta posible sin tener en cuenta cuán arriesgadas son sus decisiones, lo que conduce a un aprendizaje inestable y a choques ocasionales. Este artículo presenta un método llamado TDC-λ (Críticos Distribucionales Gemelos con una Cota Inferior de Confianza Lambda) que enseña a esos agentes no solo a apuntar alto, sino también a mantenerse razonablemente seguros mientras aprenden.
Por qué la estabilidad importa en las máquinas que aprenden
Los algoritmos estándar de control continuo, como los ampliamente utilizados TD3 y Soft Actor–Critic (SAC), han permitido que robots corran, salten y mantengan el equilibrio en simuladores complejos. Sin embargo, estos métodos suelen juzgar cada acción usando un solo número: una estimación de la recompensa que aportará a largo plazo. Esa puntuación simple puede ser engañosa cuando el proceso de aprendizaje es ruidoso, haciendo que el sistema sobrestime lo buenos que son ciertos comportamientos. El resultado es una curva de aprendizaje que puede parecer buena en promedio pero que varía bruscamente entre ejecuciones, lo cual es problemático si el mismo algoritmo debe controlar máquinas físicas o sistemas críticos para la seguridad.
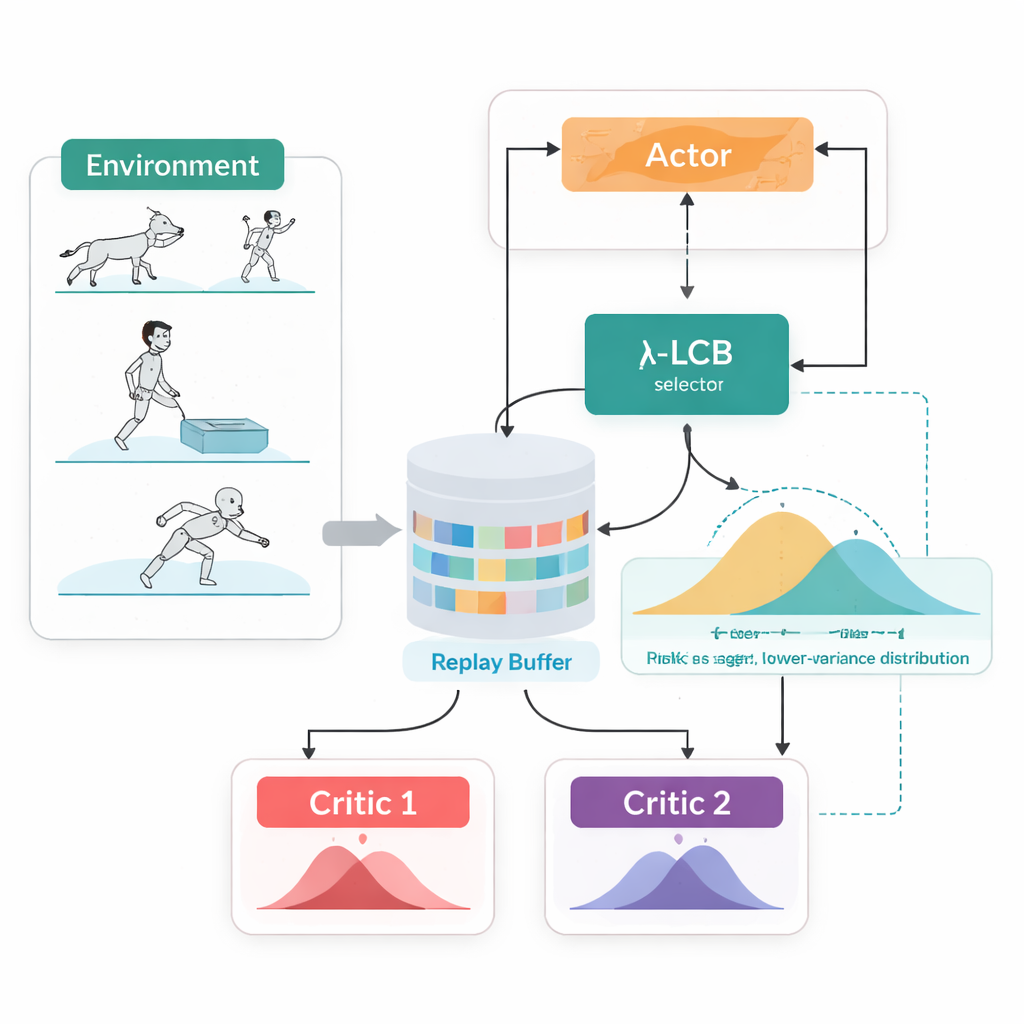
Mirar futuros completos, no números aislados
TDC-λ aborda este problema cambiando la forma en que el agente evalúa su futuro. En lugar de predecir una única recompensa esperada por cada acción, aprende dos “críticos” separados que cada uno proporciona una distribución completa sobre los posibles retornos futuros. A partir de estas distribuciones, el algoritmo calcula no solo el resultado medio sino también qué tan dispersas están las posibilidades. Esa dispersión refleja incertidumbre o riesgo. Usando una regla simple, resumida como una cota inferior de confianza, TDC-λ prefiere el crítico que predice un resultado más seguro: uno que puede ser algo menos optimista pero que está respaldado por evidencia más consistente. Un único ajuste, el parámetro de riesgo λ, regula de forma continua cuánta cautela se aplica: desde comportarse como un método convencional estilo TD3 cuando λ es cero hasta volverse más conservador a medida que λ aumenta.
Un bucle de entrenamiento, dos formas de actuar
Otra característica práctica de TDC-λ es que admite tanto formas deterministas como estocásticas de elegir acciones dentro de un marco unificado. Durante el entrenamiento, los usuarios pueden optar por una política determinista clásica o por una política gaussiana con tanh que muestrea acciones para favorecer la exploración. Independientemente de esta elección, los críticos distribucionales gemelos se entrenan de la misma manera y la evaluación siempre usa la acción media determinista. Este diseño aprovecha hallazgos previos que muestran que el comportamiento determinista en fase de prueba suele rendir igual o mejor que el muestreo, al tiempo que permite políticas ricas y favorables a la exploración durante el aprendizaje.
Poner el método a prueba
Los autores evaluaron TDC-λ en cinco tareas populares de referencia de MuJoCo donde robots simulados como HalfCheetah, Hopper, Ant, Walker2d y Humanoid deben aprender a moverse eficientemente. En estas tareas, el nuevo método igualó o mejoró el rendimiento final de bases sólidas como TD3, DDPG, SAC y un enfoque avanzado basado en flujos llamado MEOW, mostrando de forma consistente menor variabilidad entre ejecuciones repetidas. En tareas más difíciles y de mayor dimensión como Humanoid, valores ligeramente más altos de λ —lo que implica estimaciones objetivo más cautelosas— condujeron a los mejores retornos a largo plazo y a las bandas de rendimiento más ajustadas. Experimentos adicionales en otros simuladores (PyBullet y NVIDIA Isaac) y diagnósticos que siguen la variabilidad de la señal de aprendizaje reforzaron la conclusión de que TDC-λ hace el aprendizaje más estable sin ralentizarlo.
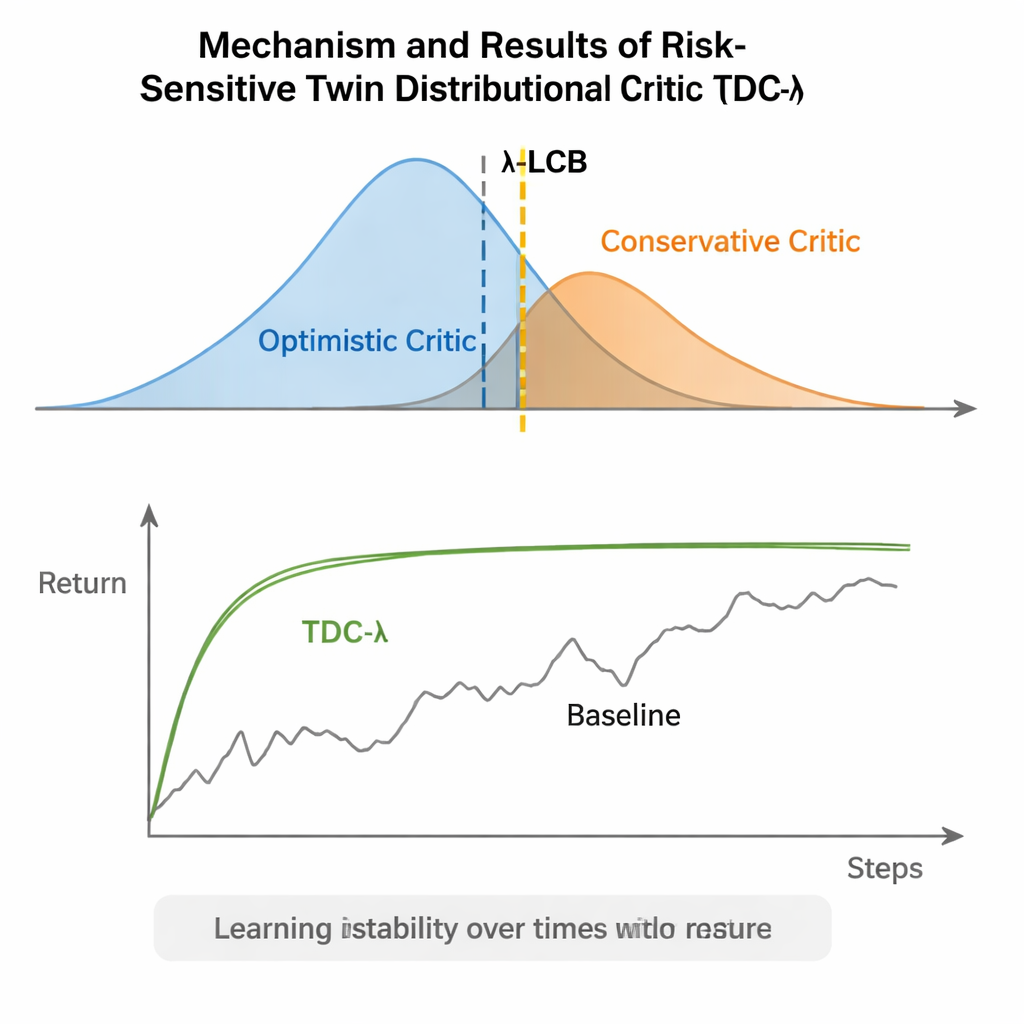
Una perilla simple para un aprendizaje más seguro
En términos cotidianos, TDC-λ ofrece a los sistemas de aprendizaje por refuerzo un “margen de seguridad” al decidir cuánto confiar en su propio optimismo. Al aprender distribuciones completas de resultados posibles y luego inclinarse hacia el crítico más seguro mediante la perilla λ, el algoritmo reduce las oscilaciones bruscas en el entrenamiento preservando un alto rendimiento final. Para los practicantes, esto ofrece una forma práctica de construir controladores más fiables para robots y otros sistemas de control continuo: empezar con un λ moderadamente conservador y ajustarlo según la volatilidad que presente el proceso de aprendizaje. El mensaje más amplio es que modelar con cuidado de qué aprende el agente —sus objetivos de entrenamiento— puede aportar gran parte de la robustez que a menudo se atribuye a arquitecturas más complejas, haciendo el aprendizaje por refuerzo avanzado más estable y accesible.
Cita: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
Palabras clave: aprendizaje por refuerzo, control continuo, aprendizaje sensible al riesgo, críticos distribucionales, robótica