Clear Sky Science · es
Modelo de predicción de la calidad del aire basado en un marco híbrido de aprendizaje profundo
Por qué importan para usted pronósticos de aire más limpios
Cuando el smog cubre una ciudad, las personas deben tomar decisiones prácticas de inmediato: ¿es seguro correr al aire libre, enviar a los niños al colegio o mantener las fábricas en funcionamiento? Esas decisiones dependen de lo bien que podamos predecir las diminutas partículas contaminantes llamadas PM2.5, lo suficientemente pequeñas como para alojarse en lo profundo de los pulmones. Este estudio presenta un nuevo modelo informático que utiliza avances recientes en inteligencia artificial para predecir los niveles de PM2.5 en ciudades chinas con mayor precisión y rapidez que muchas herramientas existentes, potencialmente proporcionando advertencias más tempranas y fiables al público y a los responsables de política.
De cielos ahumados a datos inteligentes
La contaminación del aire se ha convertido en una amenaza persistente para la salud en muchas áreas urbanas, especialmente en el norte de China, donde los altos niveles de PM2.5 se vinculan a enfermedades respiratorias y cardiovasculares. Las ciudades ahora operan densas redes de estaciones de monitoreo que registran cada hora el PM2.5, otros contaminantes y el tiempo local. Los métodos tradicionales de predicción se apoyan en matemáticas simplificadas o en modelos físicos hechos a mano, que tienen dificultades con la realidad desordenada y no lineal de vientos giratorios, cambios de temperatura y actividad humana. En contraste, el nuevo enfoque, llamado CBLA, permite que los datos “hablen por sí mismos” al entrenar redes neuronales modernas con varios años de observaciones de Pekín y Cantón.
Cómo funciona el nuevo motor de predicción
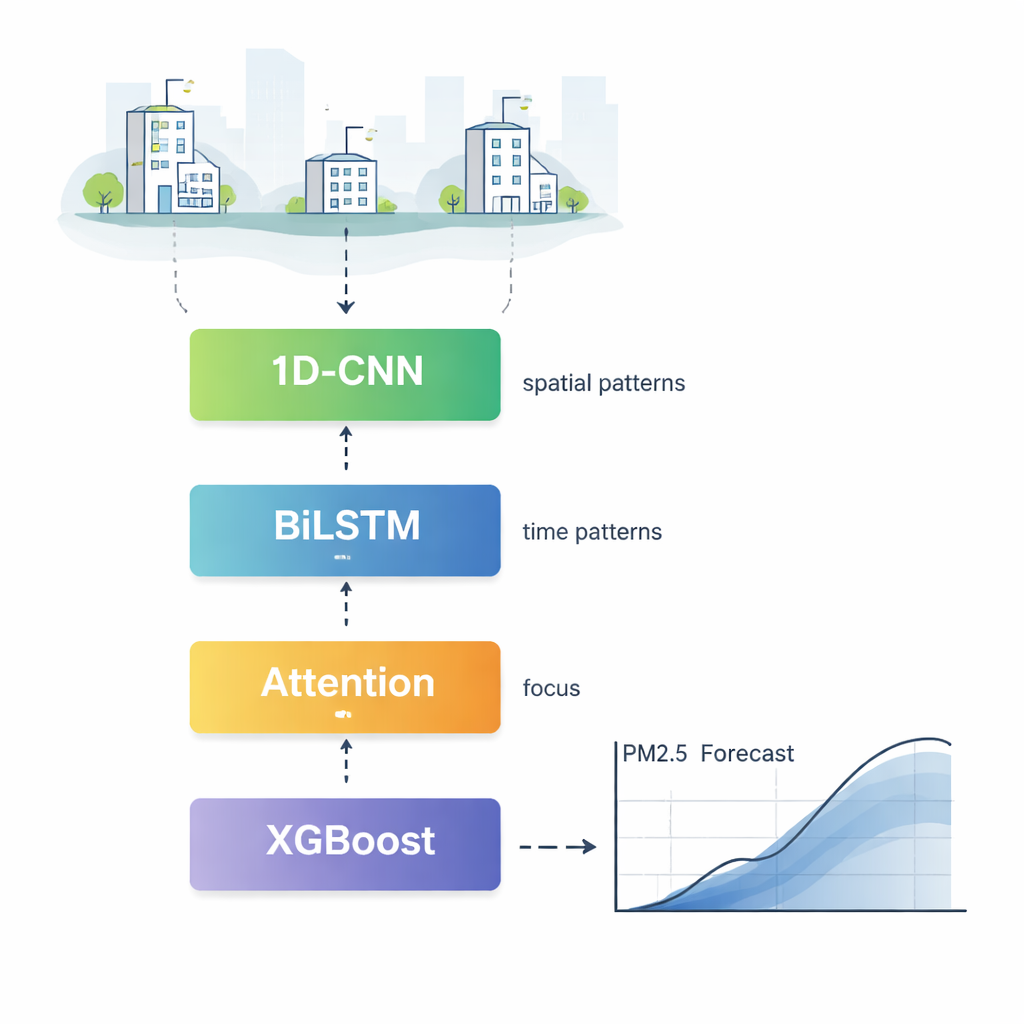
CBLA actúa como un equipo por capas de especialistas que estudian los datos de contaminación desde distintos ángulos antes de votar una predicción final. Primero, un componente conocido como una red convolucional unidimensional escanea las mediciones de muchas estaciones de monitoreo para detectar patrones que se repiten en el espacio, por ejemplo, cómo el humo tiende a propagarse de un barrio a otro. A continuación, una red de memoria bidireccional lee las series históricas de contaminación hacia adelante y hacia atrás en el tiempo, aprendiendo cómo los niveles de hoy dependen tanto de condiciones recientes como de otras algo más antiguas. Un mecanismo de atención destaca entonces las horas y características más influyentes, permitiendo que el modelo se centre más en, por ejemplo, el fuerte pico y los vientos intensos de ayer en lugar de lecturas lejanas y menos relevantes.
Incorporar la meteorología para afinar la imagen
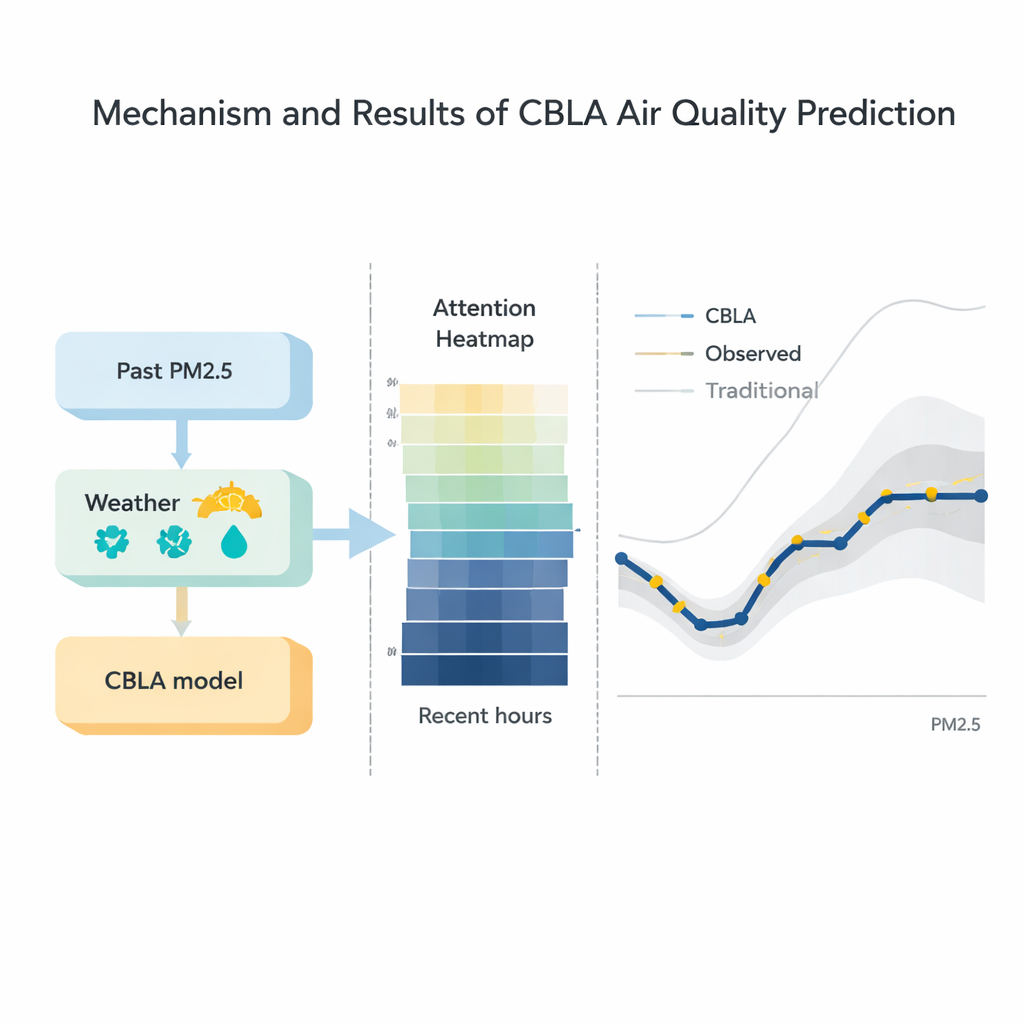
La contaminación no se mueve de forma aislada; viaja con el tiempo atmosférico. Para integrar esta información de forma ordenada, los autores añaden una segunda etapa que alimenta tanto la predicción preliminar de la red neuronal como los datos meteorológicos detallados —como la velocidad del viento, la humedad y la temperatura— en un potente algoritmo basado en árboles llamado XGBoost. Esta etapa actúa como un meteorólogo experimentado que comprueba la estimación inicial frente al tiempo actual, ajustando la predicción al alza o a la baja. Las pruebas muestran que esta combinación reduce los errores típicos de predicción y mejora el encaje entre la salida del modelo y las mediciones reales, especialmente durante acumulaciones repentinas de contaminación y eventos de limpieza.
Pruebas frente a modelos rivales
Los investigadores compararon CBLA con una amplia gama de alternativas, desde técnicas clásicas como la regresión y modelos de series temporales ARIMA hasta híbridos de aprendizaje profundo sofisticados que combinan redes gráficas y transformers. En tres conjuntos de datos reales, CBLA produjo de forma consistente el error medio más bajo y el ajuste más estrecho a los niveles observados de PM2.5. De forma importante, alcanzó una precisión comparable a algunos de los modelos modernos más avanzados mientras requería solo alrededor de un tercio de su tiempo de entrenamiento en hardware estándar. Las visualizaciones del mecanismo de atención revelaron que el modelo concede naturalmente mayor peso a las pocas horas más recientes de datos y a factores físicamente significativos como la velocidad del viento y los niveles pasados de PM2.5, ofreciendo una ventana sobre cómo sus decisiones se alinean con la intuición meteorológica.
Qué significa esto para la vida cotidiana
En términos prácticos, el estudio demuestra que combinar con cuidado varias técnicas de IA puede generar una herramienta de predicción de la contaminación que no solo es más precisa sino también más rápida y más fácil de interpretar. Los gestores urbanos podrían usar un modelo así para activar avisos sanitarios, ajustar las restricciones de tráfico o reducir preventivamente la actividad industrial horas antes de los picos de smog peligrosos. Para los residentes, mejores pronósticos significan orientaciones más claras sobre cuándo usar mascarillas, poner purificadores de aire o mantener a los niños en interiores. Aunque el trabajo se centra en ciudades chinas y en PM2.5, el mismo marco podría adaptarse a otras regiones y contaminantes, apuntando hacia un futuro en el que los pronósticos basados en datos ayuden a millones a respirar un poco mejor.
Cita: Yin, C., Li, W., Li, T. et al. Air quality prediction model based on deep learning hybrid framework. Sci Rep 16, 7084 (2026). https://doi.org/10.1038/s41598-026-37896-y
Palabras clave: predicción de la calidad del aire, PM2.5, aprendizaje profundo, contaminación urbana, meteorología