Clear Sky Science · es
Detección eficiente de intrusiones en el conjunto de datos TON-IoT mediante un enfoque híbrido de selección de características
Por qué importa proteger los dispositivos inteligentes
Miles de millones de aparatos cotidianos —desde cámaras domésticas hasta sensores industriales— ahora se comunican entre sí a través de Internet, formando lo que llamamos el Internet de las Cosas (IoT). Aunque esta conectividad aporta comodidad y eficiencia, también abre nuevas puertas a los atacantes. El artículo resumido aquí aborda una pregunta simple pero crucial: ¿cómo podemos detectar con fiabilidad los ataques en estas redes extensas de dispositivos sin recurrir a software de seguridad pesado y consumidor de energía?
El reto de detectar intrusiones digitales
Para estudiar ataques en sistemas IoT, los investigadores a menudo recurren a grandes conjuntos de datos públicos que registran cómo se comporta el tráfico de red durante el funcionamiento normal y durante ciberataques. Uno de los más utilizados es el conjunto ToN-IoT, que captura tráfico real de un banco de pruebas industrial realista, incluyendo muchos tipos de ataques como denegación de servicio, ransomware, cracking de contraseñas y espionaje man-in-the-middle. Sin embargo, los autores muestran que este conjunto de datos tiene una trampa oculta: muchos ataques se lanzaron desde rangos fijos de direcciones IP y números de puerto. Eso significa que un modelo puede “hacer trampa” aprendiendo quién es el atacante en lugar de cómo es el comportamiento malicioso. Tales modelos pueden obtener puntuaciones muy altas en el laboratorio pero fallar estrepitosamente cuando un atacante procede de una dirección nueva.
De datos voluminosos a una visión reducida del comportamiento
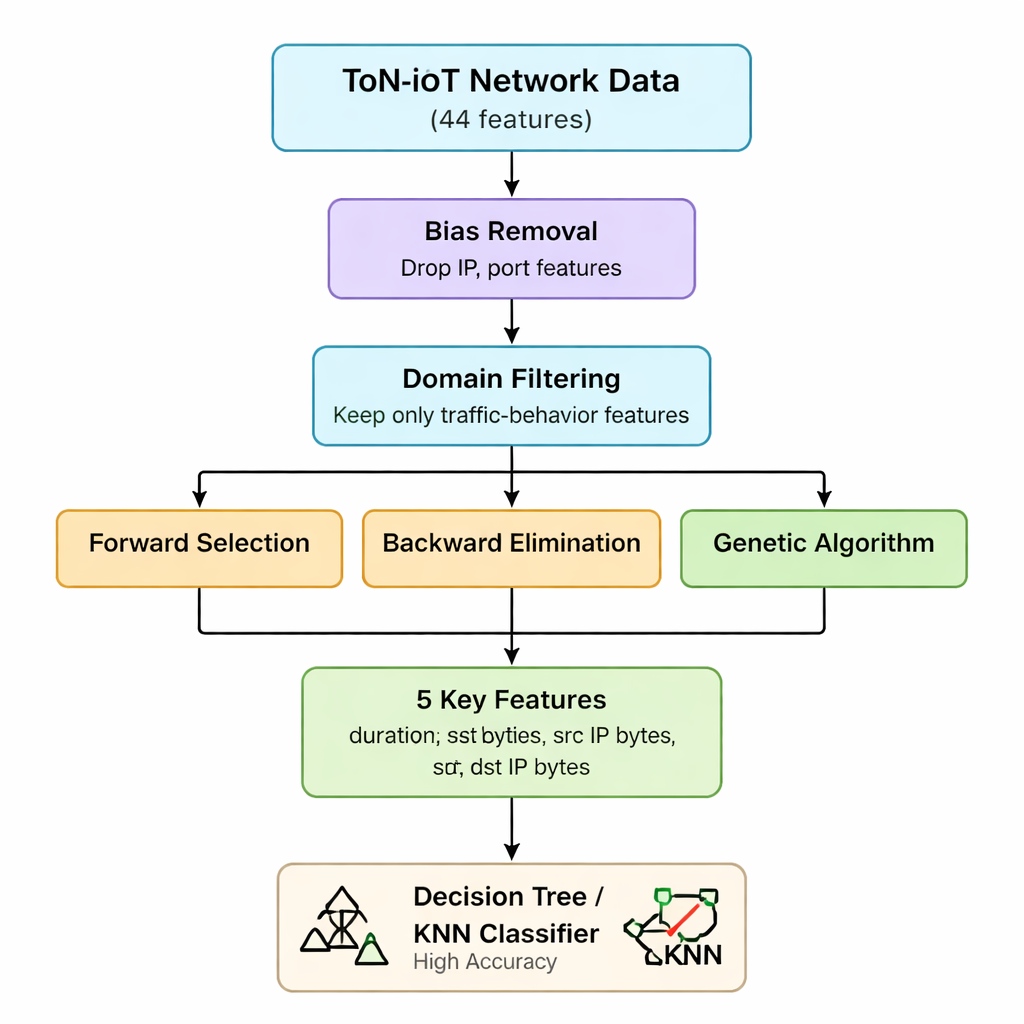
Los datos originales de red de ToN-IoT incluyen 44 mediciones distintas por cada conexión, que abarcan desde información IP hasta detalles de tráfico web y cifrado. Manejar todas ellas incrementa el tiempo de cómputo y la memoria necesaria, lo que es un problema para pasarelas IoT y dispositivos de borde con recursos limitados. Los autores usan primero su conocimiento de cómo funcionan los ataques para eliminar características que están sesgadas (como direcciones IP y números de puerto) o que no son especialmente útiles para distinguir ataques. Argumentan que la mayoría de las amenazas en IoT acaban manifestándose como patrones anómalos en cuántos paquetes y bytes se envían y reciben y en la duración de las conexiones, independientemente de quién se comunique con quién. Esta primera etapa reduce el conjunto de características de 44 a siete estadísticas fundamentales del tráfico relacionadas con volumen y duración.
Selección híbrida de características: tres enfoques sobre los mismos datos
A continuación, el equipo aplica tres métodos de tipo “wrapper” que entrenan repetidamente un modelo mientras añaden, eliminan o recombinan características para ver qué subconjunto importa realmente. La selección hacia adelante parte de un conjunto vacío, conservando una característica solo si mejora la precisión. La eliminación hacia atrás comienza con las siete y suprime las que no dañan la precisión al descartarlas. Un algoritmo genético explora muchas combinaciones en paralelo, evolucionando subconjuntos mejores a lo largo de generaciones. Los tres se prueban usando un clasificador simple de árbol de decisión, con la precisión como criterio. Al intersectar los resultados, los autores llegan a un núcleo estable de cinco características: duración de la conexión, bytes enviados, bytes recibidos y sus correspondientes cuentas de bytes a nivel IP. Estas cinco variables capturan eficazmente picos o desequilibrios anómalos en el tráfico que señalan muchos tipos de ataque.
Modelos ligeros que mantienen buen rendimiento
Con este conjunto de datos reducido y centrado en el comportamiento, los investigadores evalúan qué tan bien modelos de aprendizaje automático sencillos pueden distinguir tráfico seguro de ataques. Usando solo las cinco características seleccionadas, un árbol de decisión alcanza un 98,6 % de precisión en la clasificación básica «ataque vs normal» y un 97,2 % al distinguir entre múltiples categorías de ataque. Un modelo k-NN ofrece un rendimiento similar, y métodos de ensamblado más complejos como bosques aleatorios o gradient boosting solo aportan pequeñas mejoras a costa de mayor cómputo y memoria. De forma crucial, los autores confirman mediante pruebas estadísticas que sus características elegidas son realmente informativas y no artefactos de la forma en que se recogieron los datos. Señalan, no obstante, que los ataques sutiles tipo man-in-the-middle —diseñados para mezclarse con los flujos normales— siguen siendo más difíciles de detectar, lo que sugiere que trabajos futuros podrían necesitar señuelos de protocolo o indicadores temporales más ricos para estos casos.
Qué implica esto para la seguridad en el mundo real
Para el público general, la conclusión clave es que no siempre es necesario recurrir a modelos masivos o a docenas de mediciones técnicas para proteger sistemas IoT. Al eliminar pistas que solo funcionan en una configuración de laboratorio y centrarse en un puñado de comportamientos del tráfico, los autores demuestran que algoritmos simples y rápidos aún pueden detectar la mayoría de los ataques con alta fiabilidad. Su versión de ToN-IoT con cinco características es más fácil de procesar en dispositivos con recursos limitados en el borde de la red, lo que la hace práctica para routers, pasarelas y hubs pequeños que deben reaccionar ante amenazas en tiempo real. En resumen, el estudio sugiere un camino hacia una detección de intrusiones más fiable y desplegable para los dispositivos inteligentes cotidianos que cada vez nos rodean más.
Cita: Dharini, N., Janani, V.S. & Katiravan, J. Efficient detection of intrusions in TON-IoT dataset using hybrid feature selection approach. Sci Rep 16, 7763 (2026). https://doi.org/10.1038/s41598-026-37834-y
Palabras clave: seguridad IoT, detección de intrusiones, aprendizaje automático, selección de características, tráfico de red