Clear Sky Science · es
Modelado y aplicación de la predicción de rasgos complejos de la enfermedad de Alzheimer basada en aprendizaje multitarea
Por qué esta investigación importa para familias y pacientes
La enfermedad de Alzheimer es uno de los diagnósticos que más terror provoca en nuestra época, y aun así los médicos siguen teniendo dificultades para predecir quién empeorará rápidamente, quién se mantendrá estable durante años y cuáles signos tempranos son realmente relevantes. Este estudio plantea una pregunta simple pero poderosa: si observamos varios resultados de pruebas relacionadas con el Alzheimer y exploraciones cerebrales de forma conjunta, y los combinamos con la información genética de una persona, ¿puede la inteligencia artificial moderna aprender patrones que nos ayuden a pronosticar el curso de la enfermedad con mayor precisión?
Muchas caras de la misma enfermedad
El Alzheimer no es solo pérdida de memoria. Los pacientes difieren en su rendimiento en pruebas cognitivas, en cómo gestionan las tareas diarias y en cómo se ven sus exploraciones cerebrales. Estas distintas mediciones —como escalas comunes de memoria y función cognitiva, cuestionarios sobre el funcionamiento diario y PET para el metabolismo cerebral o la acumulación de amiloide— se sabe que están parcialmente influenciadas por la genética. Lo importante es que también comparten algunas raíces genéticas. Los métodos tradicionales de predicción suelen centrarse en una medida a la vez, desechando el hecho útil de que estos rasgos están relacionados. Los autores sostienen que, al igual que un médico que ve el panorama completo en lugar de una sola prueba, los modelos deberían aprender de varios rasgos simultáneamente.
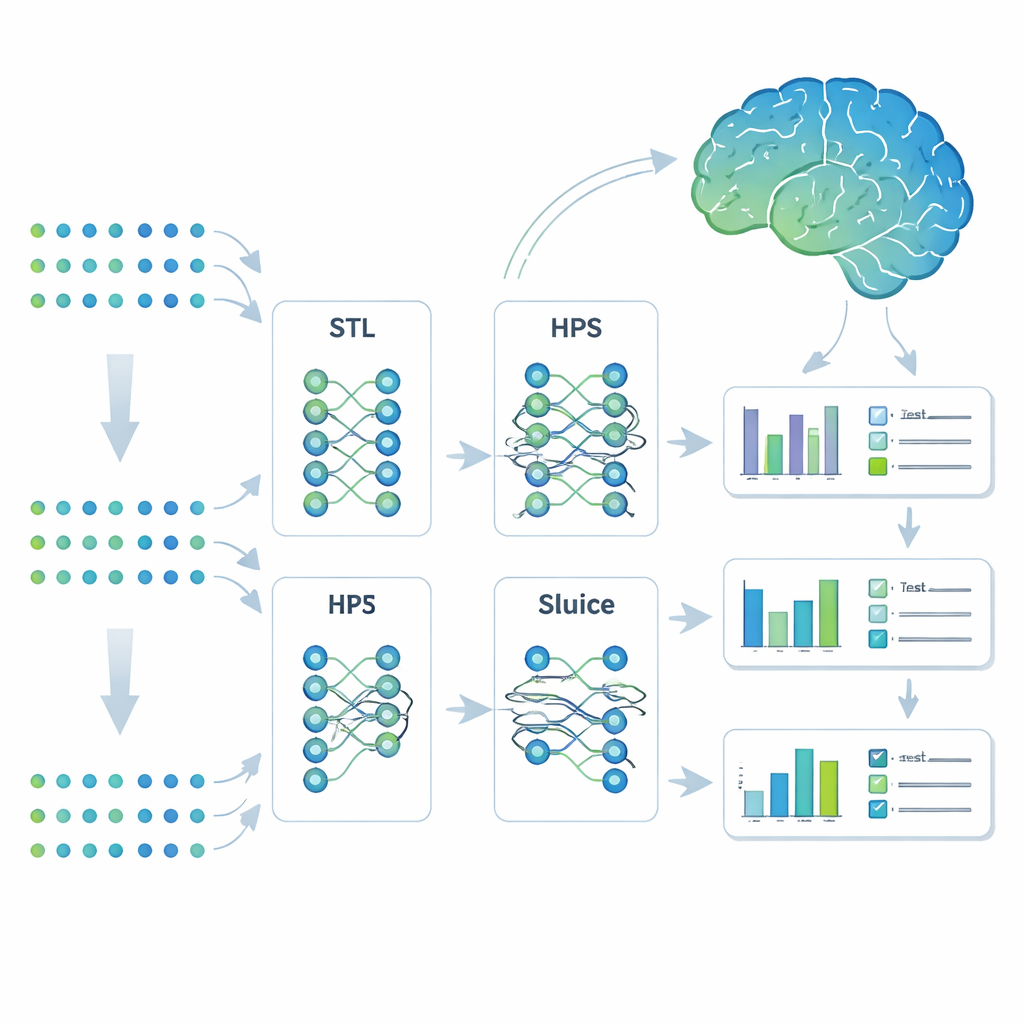
Enseñar a un modelo a aprender muchas tareas relacionadas
Los investigadores recurrieron a una estrategia de aprendizaje automático llamada aprendizaje multitarea. En lugar de construir modelos separados para cada resultado, entrenaron un único sistema para predecir siete rasgos relacionados con el Alzheimer a la vez. Compararon cuatro enfoques: modelos completamente independientes (aprendizaje de tarea única), un modelo compartido simple que solo se divide al final (compartición rígida de parámetros), un diseño ramificado más flexible que puede dividir las tareas en subgrupos, y un diseño altamente adaptable llamado Sluice Network que puede ajustar fino cuánto se comparte en cada capa de la red. Los cuatro modelos recibieron las mismas entradas genéticas; la diferencia residía en cómo compartían lo aprendido entre los rasgos.
Probar ideas en genomas simulados
Antes de confiar en cualquier modelo con pacientes reales, el equipo construyó simulaciones detalladas usando patrones genéticos reales tomados de la Iniciativa de Neuroimagen de la Enfermedad de Alzheimer (ADNI) pero con resultados que podían controlar por completo. Crearon escenarios en los que todos los rasgos compartían las mismas causas genéticas, en los que los rasgos formaban grupos solapados y en los que cada rasgo tenía causas distintas. También variaron la intensidad de las señales genéticas y la cantidad de ruido añadido, imitando la realidad desordenada de los datos humanos. En casi todas las condiciones, la Sluice Network ofreció las predicciones más precisas y se mantuvo estable incluso cuando los rasgos estaban solo débilmente relacionados. Los modelos compartidos más simples funcionaron bien cuando los rasgos tenían muchos factores genéticos en común, pero flaquearon cuando ese grado de compartición era bajo, mientras que los modelos completamente independientes fueron consistentes pero menos precisos en general.
Datos del mundo real y el poder de agrupar genes
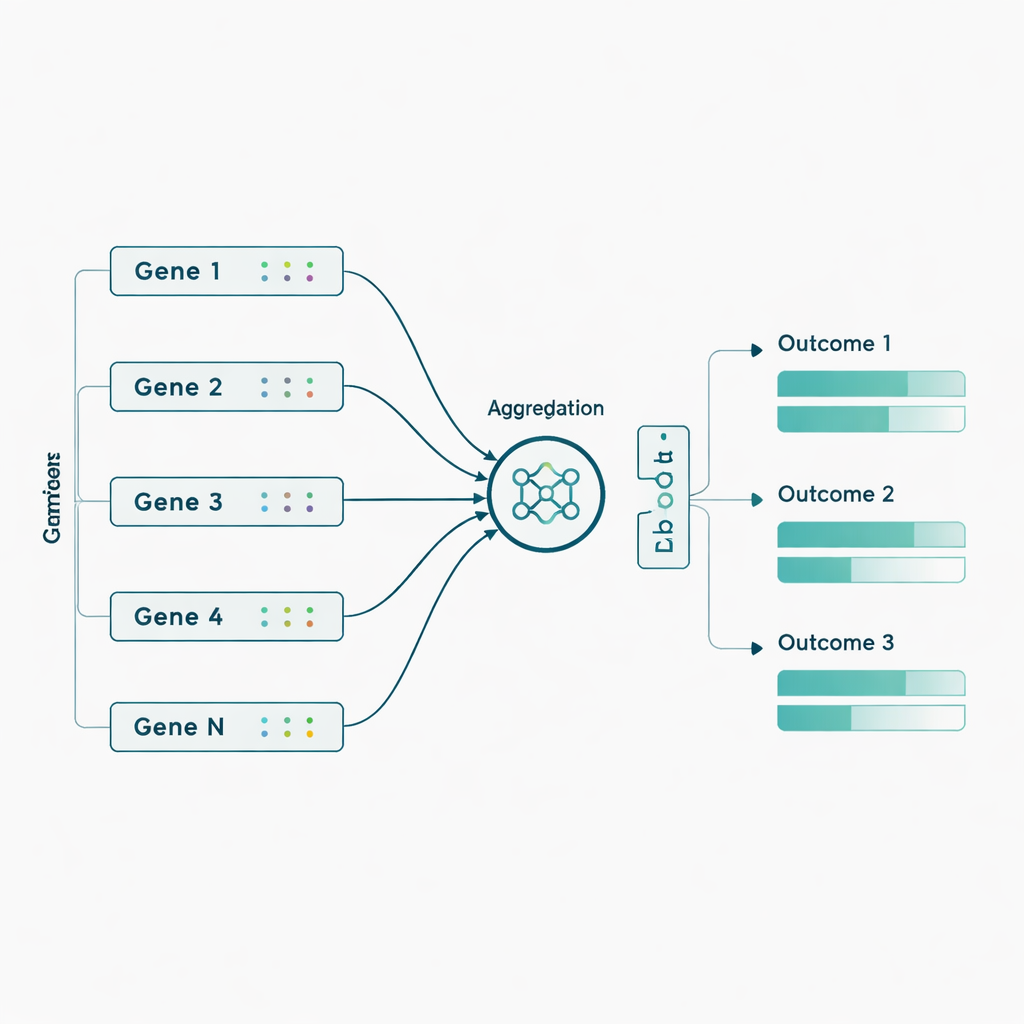
Los autores aplicaron luego estos modelos a datos reales de ADNI procedentes de 463 individuos, usando casi 3.800 marcadores genéticos extraídos de 56 genes previamente vinculados al Alzheimer. Aquí añadieron un giro inspirado biológicamente: en lugar de introducir miles de marcadores genéticos individuales, agruparon primero los marcadores por gen y permitieron que la red aprendiera una señal «resumen» compacta para cada gen antes de predecir los siete resultados. Esta agregación a nivel de gen mejoró el rendimiento de la mayoría de los modelos y especialmente de la Sluice Network, que aproximadamente duplicó su correlación media con los resultados reales. Las ganancias fueron más claras para medidas de imagen por PET y ciertas puntuaciones cognitivas y de funcionamiento, lo que sugiere que los efectos genéticos sutiles se vuelven más detectables cuando se combinan a nivel de gen en lugar de tratarse como marcadores aislados.
Qué implica esto para la predicción y el cuidado futuros
Para un no especialista, el mensaje es que modelos de IA más inteligentes y flexibles pueden extraer más información de los mismos datos genéticos y clínicos aprendiendo de varios resultados relacionados a la vez y respetando cómo la biología está organizada en genes. Aunque las mejoras actuales son modestas y están lejos de constituir una prueba clínica, el enfoque apunta hacia herramientas más fiables para estimar el perfil de riesgo de una persona, seguir la progresión probable y quizá adaptar la monitorización o las intervenciones. En enfermedades complejas como el Alzheimer, donde muchos efectos genéticos pequeños interactúan, los métodos que comparten información entre rasgos y agregan señales débiles pueden ofrecer una imagen más clara e informativa que las puntuaciones tradicionales que abordan un rasgo a la vez.
Cita: Zhou, W., Xue, Z., Liang, J. et al. Modeling and application of alzheimer’s disease complex trait prediction based on multi-task learning. Sci Rep 16, 7749 (2026). https://doi.org/10.1038/s41598-026-37820-4
Palabras clave: Genética de la enfermedad de Alzheimer, aprendizaje multitarea, predicción con aprendizaje profundo, biomarcadores de neuroimagen, agregación a nivel de genes