Clear Sky Science · es
Análisis comparativo del rendimiento de grandes modelos de lenguaje en el examen de la especialidad en odontología
Por qué importan los chatbots inteligentes para los futuros dentistas
La inteligencia artificial está cambiando rápidamente la forma en que médicos y dentistas aprenden y trabajan. Una de las herramientas más visibles es el chatbot conversacional impulsado por grandes modelos de lenguaje, la misma tecnología detrás de muchos asistentes de IA populares. Este estudio planteó una pregunta simple pero importante: si los estudiantes de odontología utilizaran estas herramientas para prepararse para un examen de especialidad altamente competitivo en radiología oral y maxilofacial, ¿qué tan bien se desempeñarían realmente las máquinas?
Probar la IA con un examen real
Para averiguarlo, los investigadores recurrieron al Examen de Ingreso a la Especialización en Odontología (DUS) en Turquía, que ayuda a determinar quién puede acceder a programas de formación avanzada. A partir de ediciones anteriores de esta prueba nacional, seleccionaron 208 preguntas de opción múltiple que cubren temas que los especialistas en radiología deben dominar, desde física de la radiación y técnicas de imagen hasta tumores mandibulares y enfermedades de los senos paranasales. La mayoría de las preguntas eran solo de texto, pero un conjunto menor requería la interpretación de imágenes radiográficas, reflejando el trabajo diagnóstico en la práctica real.
Siete chatbots enfrentan el mismo reto
El equipo planteó entonces cada pregunta, en turco, a siete chatbots de IA de uso general basados en distintos grandes modelos de lenguaje: dos versiones de ChatGPT, además de Gemini, Copilot, DeepSeek, Claude y Grok. Cada pregunta se introdujo con cuidado y por separado para evitar cualquier influencia entre conversaciones. Un segundo investigador comparó cada respuesta de la IA con la clave oficial y marcó cada una como correcta o incorrecta. Finalmente, los autores emplearon pruebas estadísticas estándar para comparar los modelos en conjunto y en áreas temáticas específicas.
Quién obtuvo la puntuación más alta —y dónde fallaron
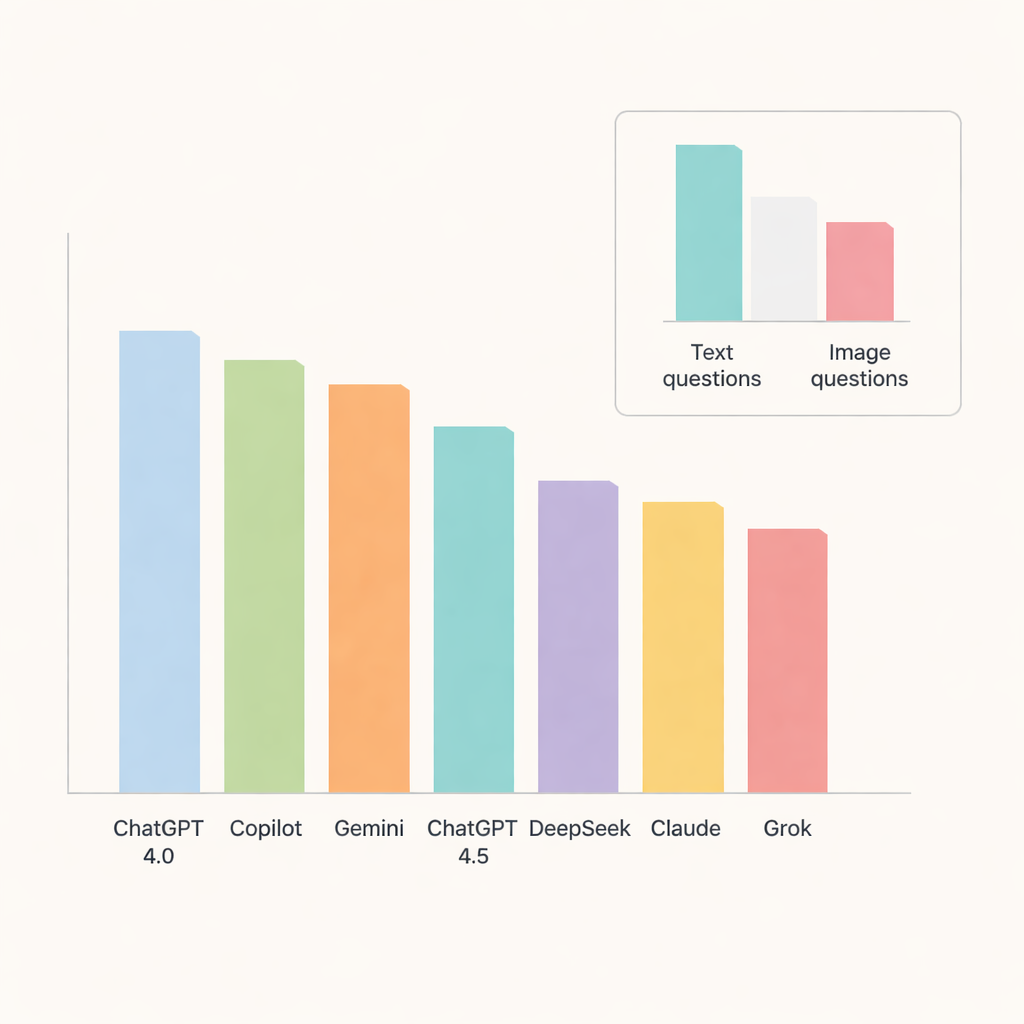
Entre todos los chatbots, ChatGPT 4.0 destacó, respondiendo correctamente alrededor del 91 por ciento de las preguntas. Copilot y Gemini le siguieron de cerca con una precisión en la franja alta o media de los 80, mientras que ChatGPT 4.5, DeepSeek, Claude y Grok quedaron algo rezagados. Al analizar por temas, los modelos se desempeñaron especialmente bien en patología oral y enfermedades de las glándulas salivales, donde la precisión se acercó o superó el 90 por ciento. En contraste, la anatomía radiográfica y las calcificaciones de tejidos blandos resultaron notablemente más difíciles, bajando las puntuaciones en varios apartados y señalando áreas donde la IA todavía tiene problemas con detalles finos.
Las imágenes siguen siendo más difíciles que las palabras
Una prueba clave fue si los chatbots podían manejar imágenes tan bien como el texto. Aquí quedaron claras sus limitaciones. La precisión cayó bruscamente en las preguntas basadas en imágenes, incluso para los modelos de mejor desempeño. ChatGPT 4.0, Gemini y Copilot lideraron en esta categoría pero aun así respondieron correctamente solo alrededor de dos tercios de las preguntas visuales. DeepSeek obtuvo el peor resultado en imágenes, con poco más de un tercio correctas. Para la mayoría de los modelos, la diferencia entre el rendimiento en texto e imagen fue lo bastante grande como para ser estadísticamente significativa, lo que subraya que la interpretación de imágenes médicas sigue siendo una tarea difícil para la IA de uso general actual.
Qué significa esto para estudiantes y pacientes
La conclusión del estudio es que los chatbots modernos pueden ser ayudantes potentes en la educación dental, especialmente para repasar hechos y practicar preguntas tipo examen en radiología. Sin embargo, incluso los sistemas más fuertes cometen suficientes errores—particularmente en temas con alta carga visual o muy específicos—como para no poder reemplazar con seguridad el juicio experto. Para estudiantes y clínicos, estas herramientas son mejor vistas como compañeros inteligentes de estudio o ayudas para la toma de decisiones, no como autoridades independientes. Usadas con la debida precaución y supervisión, pueden acelerar el aprendizaje y ampliar el acceso a explicaciones de alta calidad, mientras que la responsabilidad final del diagnóstico y el tratamiento sigue recayendo firmemente en los profesionales capacitados.
Cita: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
Palabras clave: educación dental, inteligencia artificial, grandes modelos de lenguaje, radiología oral y maxilofacial, exámenes médicos