Clear Sky Science · es
Detección multilingüe de spam en SMS usando aumento con GAN para conjuntos de datos desbalanceados
Por qué tus mensajes de texto siguen necesitando protección
La mayoría confiamos en que los mensajes no deseados acabarán en una carpeta de spam, pero detrás de eso hay un problema difícil. El spam real es raro en comparación con los mensajes cotidianos y, cada vez más, aparece en varios idiomas a la vez. Este artículo presenta una nueva forma de detectar SMS peligrosos mezclando modelos de lenguaje potentes con un generador de “datos falsos” inteligente, de modo que los filtros puedan aprender a partir de muchos más ejemplos de mensajes maliciosos sin poner en riesgo tu privacidad.
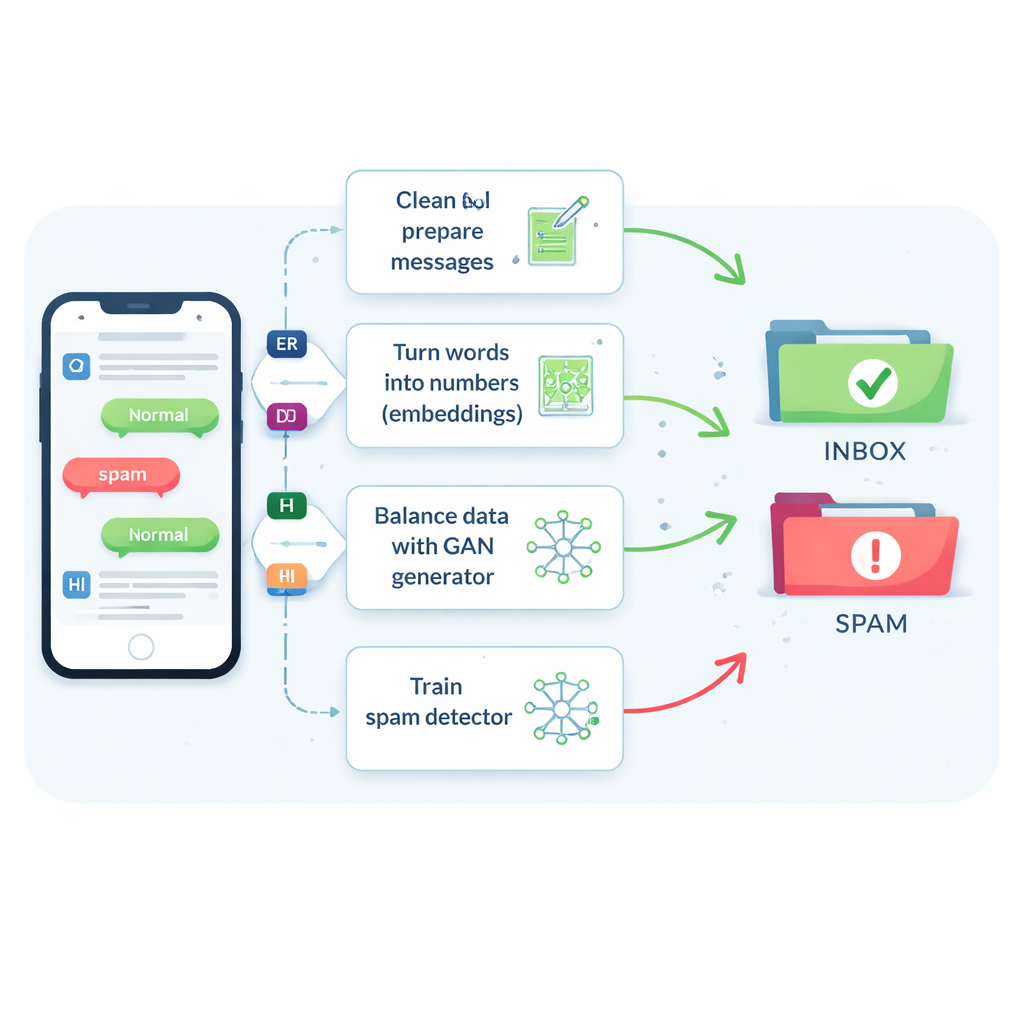
El problema del spam raro y cambiante
Los mensajes de spam representan solo aproximadamente uno de cada siete mensajes, sin embargo perder incluso una pequeña fracción de ellos puede exponer a las personas a estafas, malware y robo de identidad. Los filtros tradicionales tienen dificultades porque los SMS son cortos, están llenos de jerga y abreviaturas, y llegan en tiempo real con poco contexto adicional. Como resultado, muchos sistemas tienden a marcar los mensajes como seguros, lo que mantiene contentos a los usuarios pero deja pasar más textos dañinos. Los trucos antiguos que simplemente duplican mensajes de spam o inventan otros mediante pequeñas modificaciones pueden ayudar algo, pero a menudo confunden al filtro o generan ejemplos poco realistas que no coinciden con lo que realmente envían los delincuentes.
Enseñar a las máquinas a entender el significado del mensaje
Los autores comienzan comparando ocho algoritmos de aprendizaje distintos, desde herramientas conocidas como máquinas de vectores de soporte y árboles de decisión hasta redes neuronales más avanzadas que leen texto como secuencia, como las redes de memoria a largo plazo (LSTM). También prueban cinco formas de convertir palabras en números que el ordenador pueda usar. Los recuentos simples de la frecuencia de cada palabra (conocidos como bolsa de palabras o TF–IDF) son rápidos pero ciegos al significado. Los «embeddings» más recientes como Word2Vec y GloVe sitúan palabras con significados similares cerca unas de otras en un espacio numérico. Los más avanzados son los modelos basados en transformadores como BERT, que ajustan la representación de una palabra según la oración que la rodea, ayudando al sistema a distinguir, por ejemplo, un recordatorio amistoso de una estafa convincente.
Usar spam “falso” inteligente para corregir un conjunto de datos desequilibrado
La innovación central es cómo el estudio aborda la escasez de ejemplos de spam. En lugar de generar oraciones completas falsas, el equipo entrena un tipo de red neuronal llamada Red Generativa Antagónica (GAN) directamente sobre los embeddings numéricos de los mensajes de spam. Una parte de la GAN, el generador, aprende a crear puntos sintéticos parecidos al spam en este espacio de alta dimensión, mientras que otra parte, el discriminador, aprende a distinguirlos de los reales. Gracias a esta rivalidad, el generador produce nuevos embeddings de spam realistas que amplían el conjunto de entrenamiento. Una verificación de calidad basada en la similitud asegura que solo se conserven ejemplos sintéticos que se parezcan mucho al spam genuino, reduciendo el riesgo de datos sin sentido que podrían engañar al clasificador.
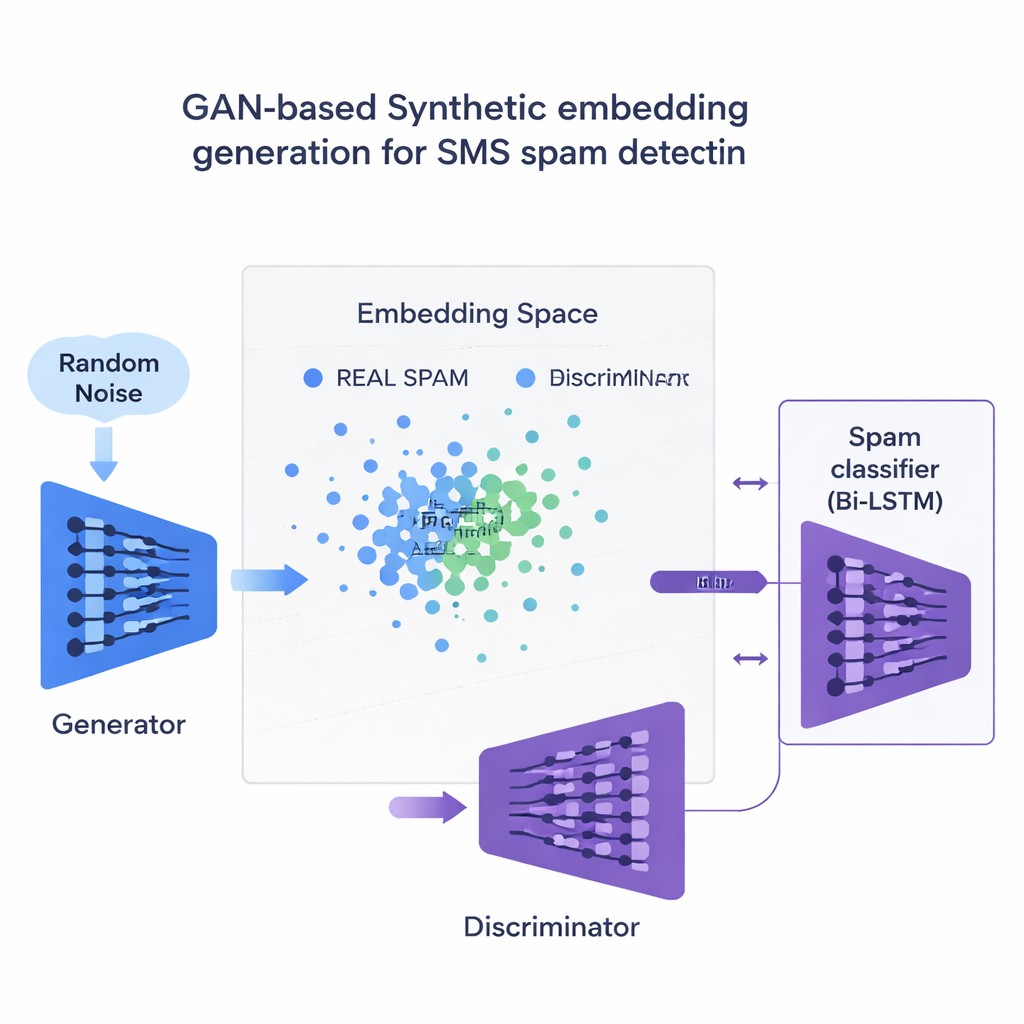
Resultados a través de idiomas y dispositivos
Los investigadores prueban 120 combinaciones diferentes de modelos, embeddings y métodos de balanceo de datos, tanto en un conjunto de SMS en inglés como en una versión multilingüe traducida al francés, alemán e hindi. En general, los embeddings contextuales como BERT superan a los enfoques más antiguos basados en el conteo de palabras. La mejor configuración —una LSTM bidireccional alimentada con embeddings BERT y entrenada con ejemplos de spam generados por GAN— alcanza una puntuación F1 alrededor del 97,6 % en mensajes en inglés y del 94,4 % en el conjunto multilingüe, superando ligeramente a los sistemas actuales de última generación. Crucialmente, lo consigue manteniendo las falsas alarmas muy bajas, un requisito importante para que las contraseñas de un solo uso y las alertas bancarias no se oculten por error. El estudio también compara esta estrategia de GAN con herramientas de balanceo más comunes como SMOTE y ADASYN, y encuentra que la GAN produce datos de entrenamiento más limpios y realistas y un rendimiento global ligeramente mejor.
Qué significa esto para los usuarios cotidianos
Para los no especialistas, la conclusión es que los filtros de spam empiezan a entender el significado y el contexto de tus mensajes, no solo palabras aisladas, y pueden ser «enseñados» con datos sintéticos cuidadosamente elaborados en lugar de necesitar más de tus textos reales. Al trabajar directamente en el espacio donde se codifica el significado del mensaje, el método propuesto ofrece a los sistemas de seguridad una visión más rica de cómo se ve el spam en muchos idiomas, sin inundarlos con réplicas torpes. Esto aumenta la probabilidad de que los mensajes peligrosos se detecten y los genuinos se entreguen, ofreciendo una protección más sólida y adaptable para los usuarios móviles a medida que los estafadores siguen cambiando de táctica.
Cita: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
Palabras clave: Detección de spam en SMS, Aumento de datos con GAN, Embeddings de texto BERT, Ciberseguridad multilingüe, phishing móvil