Clear Sky Science · es
Una arquitectura de red neuronal convolucional ligera para la detección de violencia en secuencias de vídeo
Vigilar a las multitudes para que no tengan que hacerlo los humanos
Desde conciertos y recintos deportivos hasta estaciones de metro y centros comerciales, las cámaras ahora observan casi todos los espacios concurridos. Sin embargo, la mayoría de esas transmisiones de vídeo siguen siendo supervisadas por ojos humanos cansados que pueden pasar por alto los primeros indicios de una pelea o una estampida. Este artículo explora cómo una forma delgada y rápida de inteligencia artificial puede analizar vídeo en directo en busca de comportamientos violentos en tiempo real, incluso en hardware económico, ayudando al personal de seguridad a reaccionar con rapidez antes de que la situación se descontrole.
Por qué resulta tan difícil detectar violencia en vídeo
A primera vista, pedir a un ordenador que diga “pelea” o “no pelea” suena sencillo: basta con detectar personas golpeándose. En la práctica, el problema es complejo. La iluminación puede ser deficiente o cambiar de forma repentina, las multitudes pueden bloquear la vista y las cámaras están colocadas en ángulos muy distintos. Un concierto lleno de gente parece caótico aunque no ocurra nada peligroso, mientras que un combate de boxeo aparenta violencia pero es perfectamente normal dentro del ring. Los sistemas tradicionales de visión analizaban patrones de movimiento y bordes diseñados a mano cuadro a cuadro y, aunque funcionaban en laboratorio, a menudo eran demasiado lentos o inexactos para redes de vigilancia concurridas en el mundo real.
Un cerebro más esbelto para las cámaras
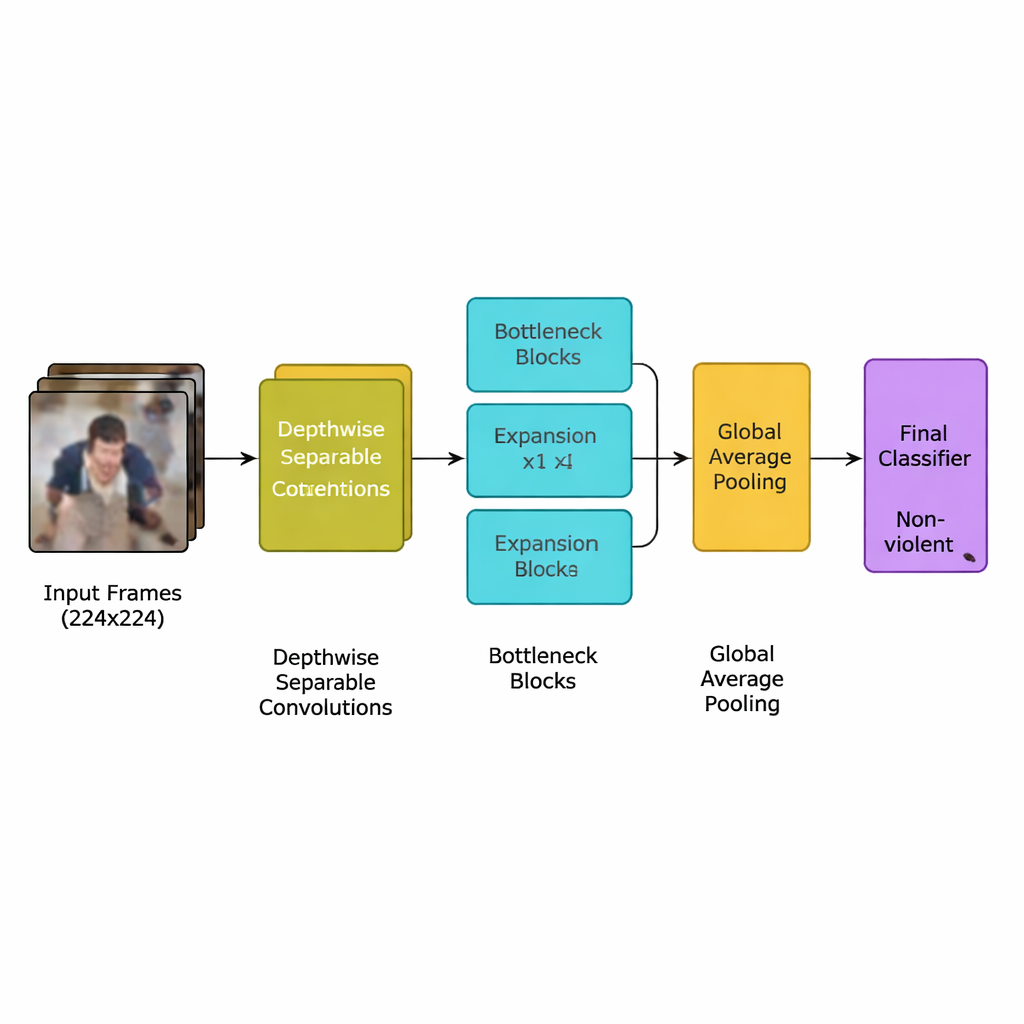
Los autores presentan un nuevo modelo de aprendizaje profundo diseñado específicamente para esta tarea: una red neuronal convolucional (CNN) ligera derivada de una familia eficiente de modelos conocida como MobileNetV2. En lugar de usar muchas capas pesadas que exigen potentes procesadores gráficos, la red se apoya en convoluciones separables en profundidad—cálculos pequeños y focalizados que reducen drásticamente el número de operaciones. También utiliza bloques de “cuello de botella invertido”, que expanden y luego comprimen la información brevemente para conservar las señales de movimiento importantes mientras eliminan redundancias. Además, el equipo añade un mecanismo de atención llamado squeeze-and-excitation, que ayuda a la red a centrarse en los patrones de movimiento en el espacio y el tiempo más típicos de incidentes violentos, ignorando detalles de fondo que distraen.
Del vídeo crudo a las alertas de violencia
El sistema completo sigue una canalización clara. Primero, las transmisiones de vídeo se descomponen en fotogramas y solo se conserva cada quinto fotograma para eliminar casi duplicados a la vez que se preservan movimientos bruscos que suelen indicar una pelea. Los fotogramas se redimensionan a un estándar de 224×224 píxeles, se desenfocan ligeramente para reducir el ruido de fondo y luego se voltean o giran aleatoriamente durante el entrenamiento para que el modelo aprenda a lidiar con diferentes puntos de vista de la cámara. Estas imágenes preparadas alimentan la CNN ligera, que convierte gradualmente los píxeles crudos en patrones de comportamiento de multitudes de mayor nivel. Tras un paso final de pooling que resume cada fotograma, un clasificador pequeño emite una decisión sencilla: violento o no violento. Dado que el modelo utiliza solo alrededor de 1,94 millones de parámetros—menos que sus antecesores MobileNet y MobileNetV2—puede ejecutarse en tiempo real en dispositivos modestos situados cerca de las cámaras en lugar de en un centro de datos lejano.
Poniendo el sistema a prueba
Para saber si este diseño compacto podía competir con redes más voluminosas, los investigadores lo entrenaron y evaluaron en dos conjuntos de referencia ampliamente usados. El Real-Life Violence Situations Dataset contiene 2.000 clips cortos extraídos de YouTube que muestran tanto escenas cotidianas como peleas reales en ubicaciones variadas. El Hockey Fight Dataset ofrece 1.000 clips de partidos profesionales de hockey, divididos entre juego ordinario y peleas sobre el hielo. En estos conjuntos, el modelo propuesto etiquetó correctamente alrededor del 97 por ciento de los clips en escenarios de la vida real y el 94 por ciento en las grabaciones de hockey, igualando o superando a CNN más grandes como InceptionV3 y VGG-19 mientras empleaba muchas menos operaciones. Las pruebas cruzadas entre los dos conjuntos—entrenar con uno y evaluar con el otro—mostraron que el sistema aún funcionaba razonablemente bien, lo que sugiere que captura patrones de movimiento generales en lugar de memorizar un único entorno.
Lo que esto significa para la seguridad cotidiana
Para los no expertos, la lección clave es que ahora es posible construir sistemas de cámaras que marquen automáticamente la probabilidad de violencia de forma rápida y económica, sin necesitar servidores gigantes o vigilancia humana constante. El estudio demuestra que una red neuronal cuidadosamente recortada y ajustada puede vigilar muchas transmisiones a la vez, enviar alertas cuando detecta comportamientos peligrosos y seguir funcionando en hardware de bajo consumo adecuado para nudos de transporte público, escuelas, hospitales y calles de la ciudad. Aunque persisten desafíos—como manejar escenas muy oscuras, una gran densidad de gente o la incorporación de señales de audio—el trabajo apunta hacia un futuro en el que cámaras inteligentes actúan como sensores de alerta temprana incansables, ayudando a los equipos de seguridad a proteger a las personas con mayor eficacia y reduciendo la carga sobre los vigilantes humanos.
Cita: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
Palabras clave: detección de violencia, vigilancia de vídeo, CNN ligera, MobileNetV2, seguridad pública