Clear Sky Science · es
Huella DNS basada en la actividad del usuario
Por qué tus visitas web dejan un rastro oculto
Cada vez que navegas por la web, tu equipo consulta discretamente una especie de agenda de direcciones, llamada Sistema de Nombres de Dominio (DNS), para saber cómo alcanzar cada sitio. Esas consultas no desaparecen. A lo largo de días y semanas forman un patrón de qué tipos de sitios visitas, cuándo y con qué frecuencia. Este artículo muestra que esos patrones son lo suficientemente distintivos como para comportarse como una huella conductual, permitiendo que algoritmos potentes distingan a los usuarios, incluso si cambia su dirección IP visible, lo que abre oportunidades para la seguridad y plantea serias dudas sobre la privacidad.
La guía telefónica de Internet y tus hábitos
El DNS existe para traducir direcciones web legibles por humanos, como www.google.com, en las direcciones IP numéricas que usan los ordenadores para comunicarse. La mayoría de la gente no lo piensa, pero cada búsqueda, reproducción de vídeo, comprobación de correo o actualización de una app desencadena una o más consultas DNS. Estas consultas suelen ser atendidas por servidores DNS locales o públicos y registradas como registros sencillos: qué dirección IP preguntó por qué dominio y cuándo. Si se acumulan suficientes de estos registros, se obtiene una imagen detallada de los tipos de servicios en línea de los que depende un usuario, desde herramientas empresariales y almacenamiento en la nube hasta redes sociales y plataformas de streaming. Mientras que investigaciones anteriores usaron estas trazas para detectar malware o identificar tipos de dispositivos, este estudio plantea una pregunta más directa: ¿pueden identificar a usuarios o máquinas únicamente a partir de su comportamiento DNS recurrente?
Convertir los clics diarios en una huella conductual
Los autores se basan en un gran conjunto de datos DNS de acceso público recopilado por un proveedor de Internet local durante tres meses. Cada día agregan la actividad DNS de cada dirección IP activa en un resumen compacto: conteos de consultas totales, cuántos dominios diferentes se consultaron y, crucialmente, cómo esos dominios se distribuyen en 75 categorías de contenido como «Negocios generales», «Software / Hardware» o «Redes sociales». Mantienen solo las direcciones IP que aparecen al menos en el 80 por ciento de los días, asegurando suficiente historial por usuario, y eliminan con cuidado características redundantes o casi vacías. También aplican herramientas estadísticas para detectar campos altamente correlacionados, filtran valores extremos en el volumen de consultas y luego comprimen los datos con análisis de componentes principales para que la mayor parte de la variación útil se conserve en muchas menos dimensiones. Visualizando los datos limpios con una técnica llamada t‑SNE, encuentran que muchas direcciones IP forman grupos compactos y bien separados: un indicio temprano de que la clasificación automática puede ser factible.
Poner a prueba modelos de aprendizaje automático
Con este conjunto de datos procesado, el equipo trata la identificación de usuarios como un problema masivo de clasificación: dada un día de estadísticas DNS, decidir a cuál de 1.727 direcciones IP pertenece. Comparan una batería de modelos, desde métodos clásicos como Naive Bayes y Random Forests hasta herramientas más avanzadas como XGBoost y redes neuronales profundas. Cada modelo se entrena y valida en diferentes versiones de los datos (crudos, reescalados, estandarizados o con reducción de dimensión) y se evalúa por la frecuencia con la que asigna correctamente la clase correcta, junto con medidas de precisión y recall. Los modelos tradicionales rinden razonablemente bien: Random Forests alcanza alrededor del 73 por ciento de exactitud, y XGBoost supera el 81 por ciento mientras distingue correctamente más del 99 por ciento de todas las clases. Pero los mejores resultados los obtienen las redes neuronales, especialmente una red neuronal convolucional (CNN) personalizada que trata el vector de características como una imagen unidimensional del comportamiento diario.
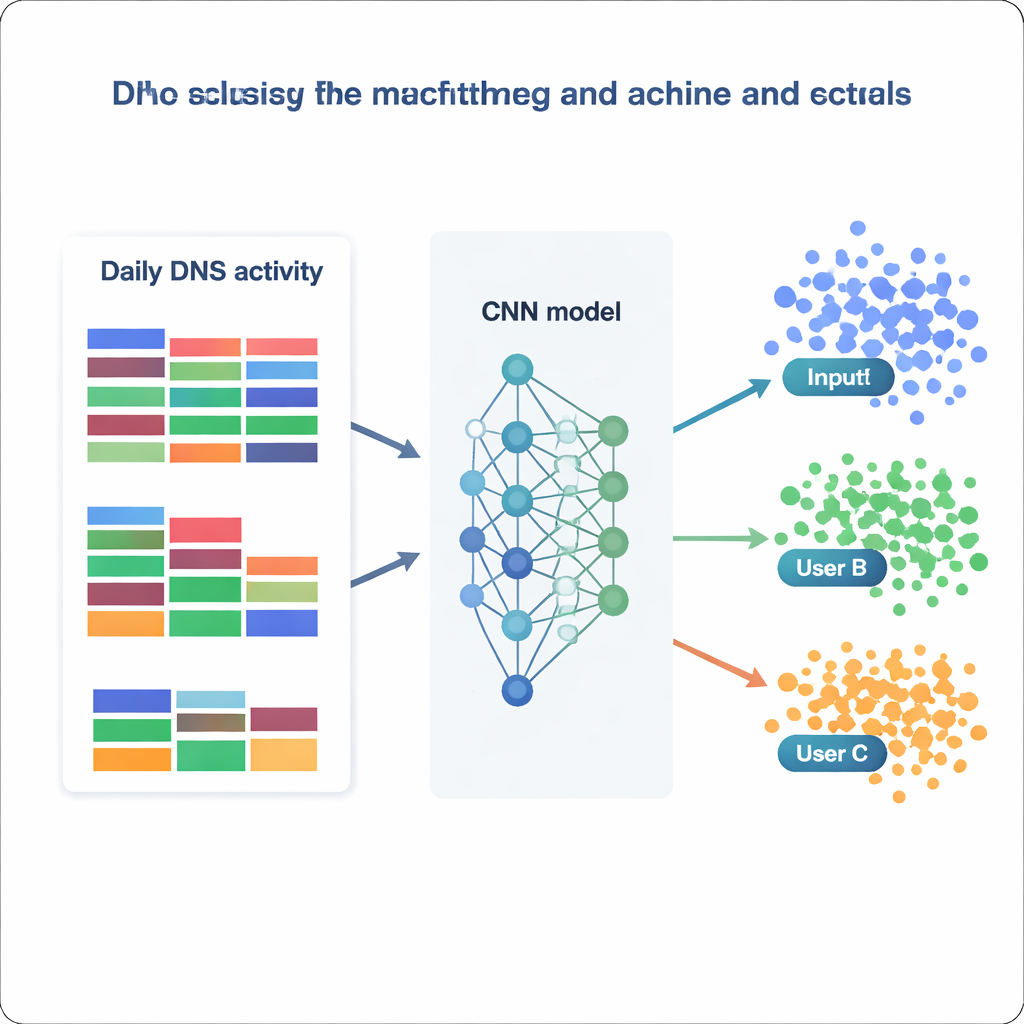
¿Hasta qué punto puede un modelo saber “quién” eres?
La mejor CNN, entrenada con datos normalizados, identifica correctamente la IP de origen en casi el 87 por ciento de los días reservados para prueba y predice con éxito 1.694 de las 1.727 direcciones IP distintas. En términos prácticos, esto significa que la mayoría de los usuarios—o pequeños grupos que comparten una IP—muestran patrones DNS estables y reconocibles a lo largo del tiempo. Al examinar en qué características se apoyan más los modelos, los autores encuentran dos estrategias complementarias. Algunos modelos se apoyan en categorías muy comunes, como servicios empresariales generales o de software, que capturan hábitos amplios. Otros, como XGBoost, ganan potencia adicional con categorías raras pero reveladoras asociadas a seguridad, política o intereses de nicho. En conjunto, estos resultados muestran que incluso estadísticas agregadas y simples—sin analizar la lista completa de nombres de dominio—pueden codificar suficiente estructura para volver a identificar usuarios con una fiabilidad sorprendente.
Promesas, límites y apuestas por la privacidad
Para las fuerzas del orden y los defensores de la red, las huellas DNS podrían convertirse en una herramienta valiosa para rastrear reincidentes, detectar máquinas comprometidas o identificar botnets que usan direcciones IP cambiantes para eludir bloqueos. Al mismo tiempo, el estudio destaca límites claros: las huellas DNS son más estables cuando una IP pública está vinculada a un único usuario, lo cual es más realista en redes IPv6 modernas que en el mundo IPv4 actual, donde muchos usuarios comparten una dirección mediante NAT. El cambio frecuente de servidores DNS o el uso de redes Wi‑Fi públicas también debilita la señal. Lo más importante es que el trabajo subraya un riesgo para la privacidad difícil de ver para los usuarios comunes. Dado que el registro de DNS es en gran medida invisible y pasivo, el seguimiento conductual puede suceder sin instalar cookies ni scripts intrusivos. Los autores publican abiertamente su conjunto de datos y modelos, argumentando que la investigación transparente es necesaria para que la sociedad valore los beneficios de seguridad de la huella DNS frente a su potencial para la vigilancia silenciosa y decida qué protecciones y políticas deben regular esta nueva y potente forma de identificación en línea.
Cita: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
Palabras clave: Huella DNS, seguimiento de usuarios, privacidad en Internet, seguridad de la red, aprendizaje automático