Clear Sky Science · es
Superresolución de rostros del mundo real basada en redes generativas adversarias y de alineamiento facial
Rostros más nítidos a partir de fotos borrosas
Cualquiera que haya intentado ampliar un rostro en un vídeo de seguridad antiguo o en una pequeña foto de redes sociales conoce la frustración: cuanto más se aumenta, más el rostro se convierte en un borrón en bloques. Este trabajo presenta un nuevo enfoque de inteligencia artificial que puede convertir imágenes faciales de baja calidad del mundo real en otras mucho más claras, conservando mejor la identidad y la expresión de la persona. Eso tiene implicaciones evidentes para cámaras de seguridad, pericia fotográfica e incluso aplicaciones cotidianas de mejora de imágenes.
Por qué es tan difícil arreglar rostros borrosos
Hacer que una imagen facial pequeña y difusa parezca nítida no es solo una cuestión de “añadir píxeles”. Los métodos tradicionales se basaban en reglas diseñadas a mano o en patrones simples, y las técnicas de aprendizaje profundo más recientes a menudo aprendieron a partir de imágenes degradadas de forma artificial: tomar un rostro limpio y de alta resolución, difuminarlo y reducirlo, y luego enseñar a una red a invertir ese proceso. El problema es que las imágenes del mundo real —como las de cámaras de vigilancia o vídeos comprimidos— se degradan de maneras desordenadas e impredecibles. El desenfoque, el ruido y los artefactos de compresión rara vez coinciden con los ejemplos sintéticos ordenados usados en el entrenamiento, por lo que los modelos que funcionan bien en el laboratorio suelen fallar con material real. Peor aún, pueden generar rostros que parecen plausibles pero que ya no se parecen a la persona original.
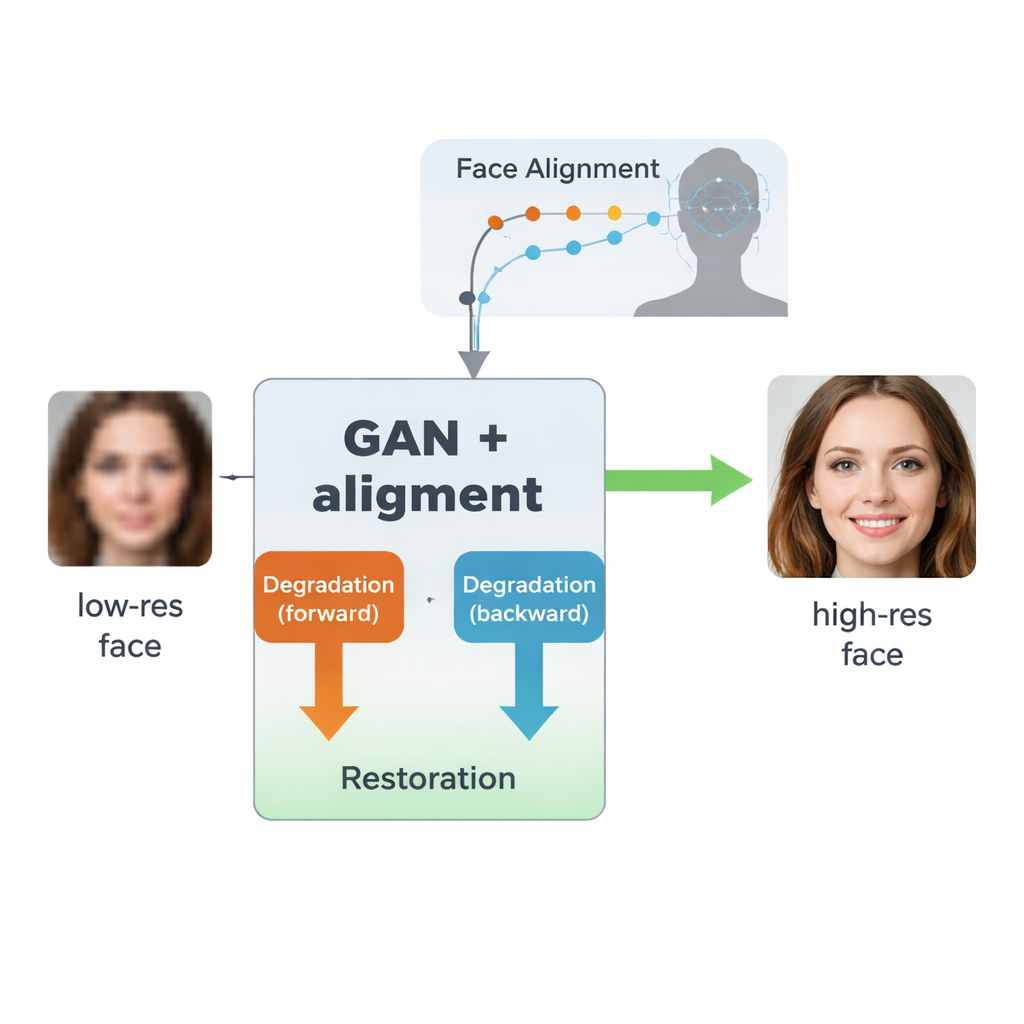
Un bucle de aprendizaje bidireccional para imágenes del mundo real
Los autores se apoyan en un tipo de IA llamado red generativa adversaria (GAN), que aprende a crear imágenes realistas enfrentando a dos redes neuronales entre sí: una genera imágenes y la otra juzga cuán reales parecen. Su diseño, inspirado en un modelo anterior llamado SCGAN, utiliza una estructura de “semi-ciclo” con dos bucles complementarios. En el bucle hacia adelante, rostros reales de alta resolución se degradan intencionadamente mediante una rama para producir versiones sintéticas de baja resolución, que luego son restauradas por una rama compartida de restauración. En el bucle hacia atrás, rostros realmente de baja calidad del mundo real se mejoran con esa misma rama de restauración y luego se degradan de nuevo por otra rama para asemejarse a imágenes reales de baja resolución. Al forzar la consistencia en ambas direcciones —degradar y luego restaurar, o restaurar y luego degradar—, el sistema aprende un modelo realista de cómo se estropean los rostros en la práctica y cómo revertir ese proceso sin necesidad de parejas perfectamente emparejadas de imágenes reales en baja y alta calidad.
Enseñar a la red cómo debe ser realmente un rostro
Una innovación clave de este trabajo es enseñar al sistema no solo a hacer que las imágenes parezcan más nítidas, sino a respetar la estructura subyacente del rostro humano. Para ello, los autores integran una red de alineamiento facial separada, diseñada originalmente para localizar puntos de referencia como las comisuras de los ojos, la punta de la nariz y el contorno de la boca. Esta red de alineamiento predice “mapas de calor” que destacan dónde debería estar cada punto de referencia. Durante el entrenamiento, el modelo compara los mapas de calor de la imagen restaurada con los de un rostro real de alta resolución de la misma persona y penaliza las discrepancias. Crucialmente, esto utiliza un modelo de alineamiento preentrenado y no requiere etiquetas manuales de puntos de referencia para cada imagen de entrenamiento. El resultado es una especie de guía geométrica: la red de mejora se ve impulsada a situar los ojos, la nariz y la boca en las posiciones y formas correctas, en lugar de limitarse a pintar sobre el desenfoque con texturas genéricas de rostro.
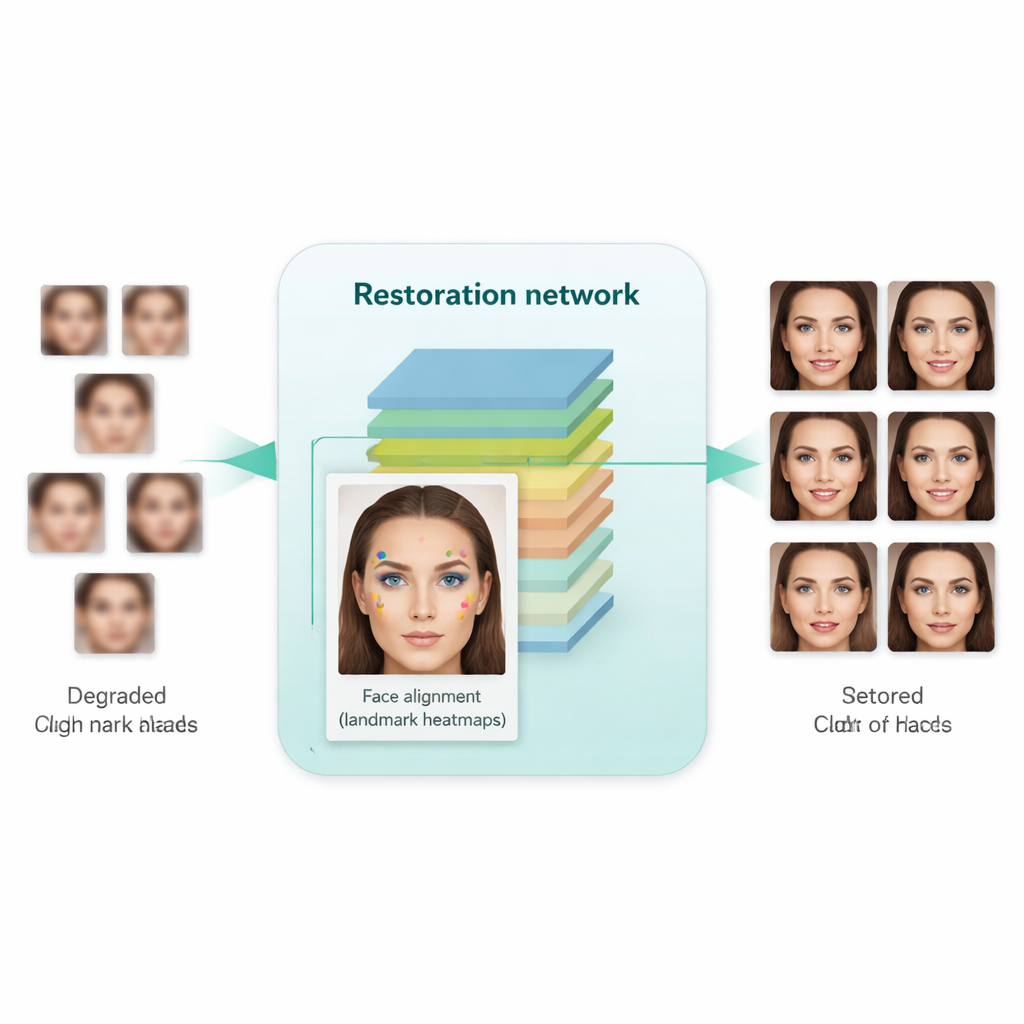
¿Qué tan bien funciona en la práctica?
Los investigadores entrenaron su sistema con una gran colección de rostros de alta calidad y un conjunto separado de rostros genuinamente de baja calidad procedentes de conjuntos de datos del mundo real. Luego lo evaluaron tanto en bancos de prueba sintéticos (donde hay imágenes claras de referencia) como en imágenes reales (donde solo pueden emplearse medidas de realismo visual y métricas estadísticas). En comparación con métodos anteriores —incluyendo herramientas conocidas como Real-ESRGAN, GFPGAN y el SCGAN original—, el nuevo enfoque generó imágenes que no solo parecían más naturales y menos distorsionadas, sino que también mejoraron el rendimiento en tareas prácticas. Cuando las imágenes mejoradas se introdujeron en detectores faciales estándar y en un modelo popular de reconocimiento facial (FaceNet), la precisión de detección y verificación mejoró notablemente, lo que indica que los detalles relacionados con la identidad se preservaron mejor. Al mismo tiempo, las métricas automáticas de calidad sugirieron que los rostros generados estaban más próximos en distribución a las fotos reales de alta resolución.
Qué significa esto para el uso cotidiano
En términos sencillos, este trabajo muestra que se pueden obtener rostros más nítidos y de mayor confianza a partir de imágenes de mala calidad combinando dos ideas: aprender un modelo realista de cómo se estropean las imágenes en el mundo real y usar información de puntos faciales para mantener la estructura del rostro intacta. En lugar de simplemente “adivinar” un rostro de mejor aspecto, el sistema se guía para reconstruir a la persona correcta con ojos, boca y forma general más claros. Esto hace que el método sea especialmente prometedor para aplicaciones como seguridad, pericia forense y restauración de archivos, donde tanto la claridad visual como la identidad correcta son críticas y donde rara vez están disponibles versiones originales de alta calidad de las imágenes.
Cita: Fathy, H., Faheem, M.T. & Elbasiony, R. Real-world face super-resolution based on generative adversarial and face alignment networks. Sci Rep 16, 7492 (2026). https://doi.org/10.1038/s41598-026-37573-0
Palabras clave: superresolución de rostros, redes generativas adversarias, alineamiento facial, reconocimiento facial, restauración de imágenes