Clear Sky Science · es
Investigación sobre módulos plug-and-play de mejora de correlación en aprendizaje profundo multietiqueta
Enseñar a las máquinas a manejar demasiadas etiquetas
Tiendas en línea, archivos jurídicos y bases de datos médicas dependen de software que pueda etiquetar rápidamente cada nuevo documento con las etiquetas adecuadas. Pero los sistemas modernos a menudo se enfrentan a decenas de miles, o incluso millones, de etiquetas posibles —desde categorías de producto hasta temas médicos— mientras que cada texto necesita solo un puñado. Este artículo presenta un nuevo complemento, llamado Red de Mejora de Correlación de Etiquetas (LCENet), que ayuda a los modelos de aprendizaje profundo existentes a aprovechar mejor cómo las etiquetas tienden a aparecer juntas en datos reales, lo que conduce a un etiquetado de texto más preciso y rápido.
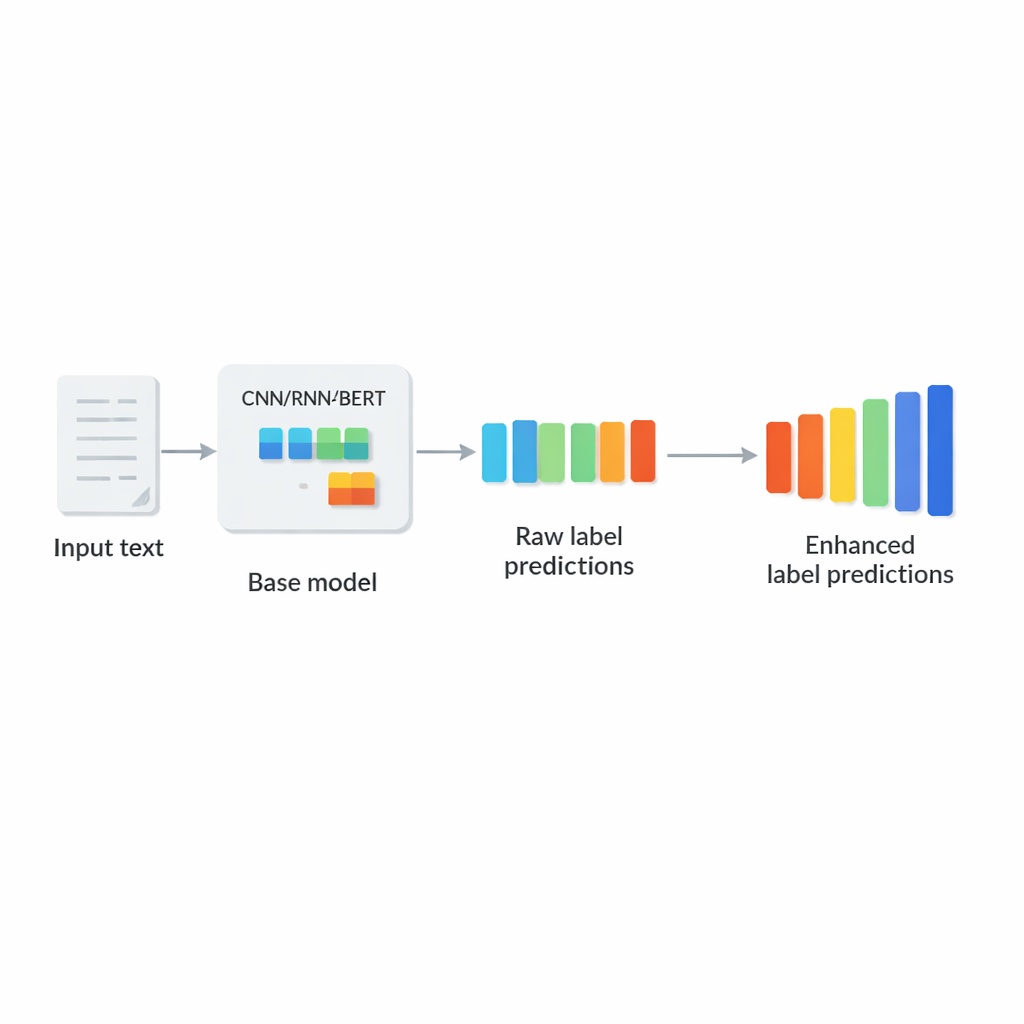
Por qué etiquetar a escala web es tan difícil
Muchas aplicaciones del mundo real se encuadran en lo que los investigadores llaman clasificación extrema de texto multilabel: dado un breve resumen o un documento extenso, el sistema debe seleccionar un pequeño subconjunto de etiquetas relevantes de un catálogo enorme. Ejemplos incluyen asignar categorías a productos en un sitio de comercio electrónico, indexar artículos biomédicos con términos MeSH, emparejar anuncios con páginas web o mapear textos legales a códigos jurídicos detallados. Estos entornos comparten tres desafíos: la lista de etiquetas es extremadamente grande, la mayoría de las etiquetas son raras y cada texto usa solo unas pocas etiquetas. Las técnicas tradicionales o bien dividen el problema en muchos clasificadores pequeños o comprimen las etiquetas en vectores de dimensión reducida, pero a menudo se basan en recuentos simples de palabras y no pueden capturar plenamente el significado ni las relaciones entre etiquetas.
Qué siguen pasando por alto los modelos profundos estándar
Los enfoques modernos de aprendizaje profundo, como redes convolucionales, redes recurrentes y modelos basados en Transformers como BERT, han mejorado mucho la comprensión del texto al aprender representaciones semánticas ricas. Sin embargo, casi todos ellos realizan una simplificación crucial en el paso final: una vez que el texto se codifica en un vector, predicen cada etiqueta de forma independiente. En la práctica, sin embargo, las etiquetas interactúan con fuerza. Un artículo médico etiquetado con “diabetes” es más probable que también trate “resistencia a la insulina”, y un dispositivo etiquetado como “smartphone” suele estar relacionado con “electrónica” y “dispositivos de comunicación”. Ignorar estos patrones impide que los modelos utilicen etiquetas de alta confianza para apoyar a otras menos seguras, e incluso pueden producir combinaciones que no tienen sentido juntas.
Un complemento que aprende relaciones entre etiquetas
Los autores proponen LCENet como un módulo ligero y plug-and-play que se coloca después de cualquier clasificador profundo de texto existente. En lugar de cambiar cómo el modelo base procesa el texto, LCENet toma las puntuaciones crudas de las etiquetas que este produce y las pasa por un “cuello de botella” compacto que fuerza al sistema a descubrir una representación de baja dimensión donde las etiquetas relacionadas se agrupan. Funciones de activación no lineales permiten al módulo captar asociaciones complejas de orden superior, no solo vínculos pareados simples. Una conexión residual, o de salto, alimenta las puntuaciones originales directamente a la salida junto con las puntuaciones corregidas, lo que estabiliza el entrenamiento y asegura que el complemento no pueda empeorar fácilmente los resultados. De forma crucial, LCENet reduce el número de parámetros adicionales de algo que crecería con el cuadrado del número de etiquetas a un crecimiento mucho más manejable y lineal, por lo que sigue siendo factible incluso con cientos de miles de etiquetas.
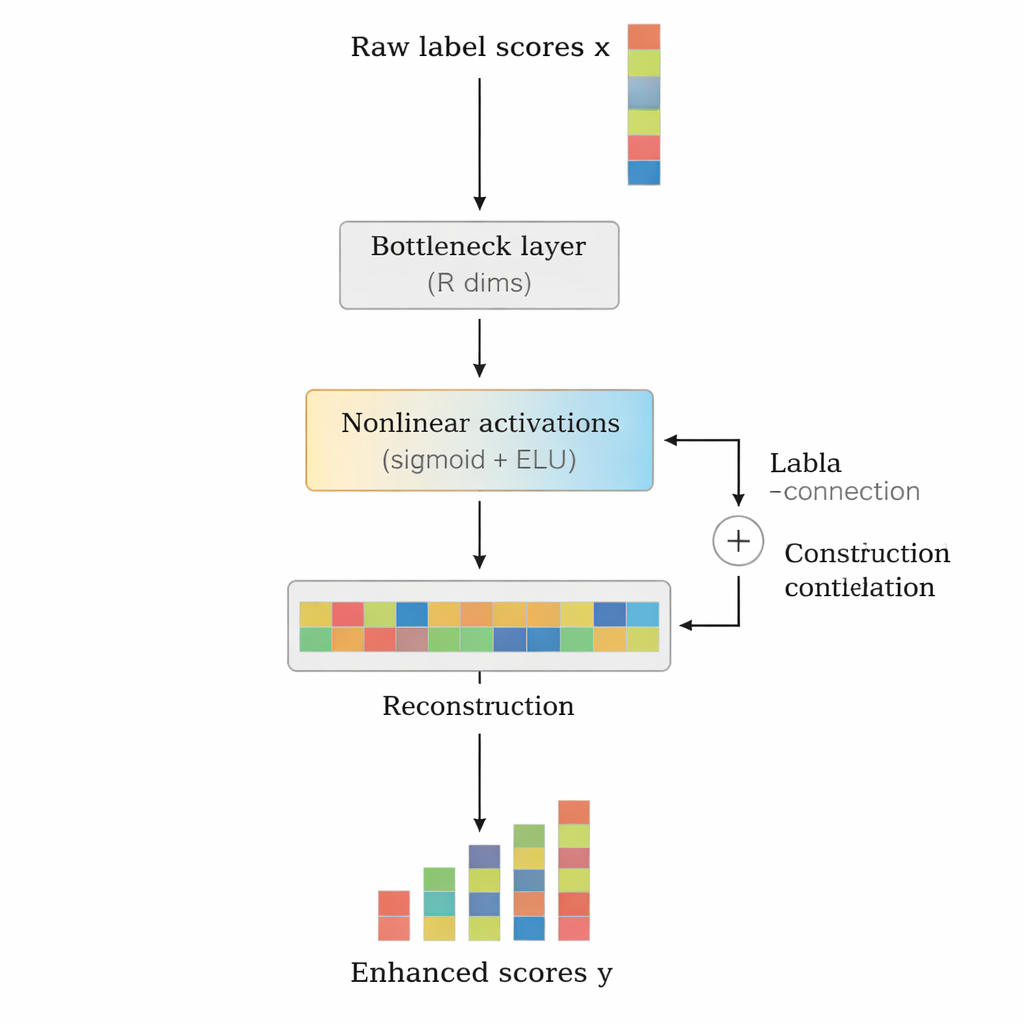
Demostrando los beneficios a través de modelos y conjuntos de datos
Para comprobar si LCENet es realmente general, los autores lo acoplaron a cuatro modelos profundos muy diferentes, incluidas arquitecturas basadas en CNN y en BERT, así como sistemas diseñados específicamente para entornos biomédicos y de etiquetas extremas. Evaluaron estas combinaciones en tres conjuntos de referencia públicos: un corpus jurídico europeo (EUR-Lex), un conjunto de productos de Amazon (AmazonCat-13K) y una enorme colección de Wikipedia con más de medio millón de etiquetas (Wiki-500K). En todos los modelos, conjuntos de datos y seis métricas centradas en el ranking, LCENet mejoró el rendimiento de forma consistente, a veces elevando la precisión top-1 en más de cinco puntos porcentuales en el conjunto de datos más grande. Las curvas de entrenamiento mostraron además que LCENet suele reducir casi a la mitad el número de pasos de entrenamiento necesarios para alcanzar una determinada precisión, porque la estructura de correlación entre etiquetas añadida proporciona señales de aprendizaje más claras desde el inicio.
Por qué esto importa para sistemas cotidianos
Para los profesionales que ya confían en modelos profundos para etiquetar texto, LCENet ofrece una forma práctica de mejorar la precisión y la velocidad de entrenamiento sin rediseñar sus sistemas ni recopilar nuevos tipos de anotaciones. Trata el espacio de etiquetas en sí como una fuente de conocimiento, aprendiendo qué etiquetas tienden a aparecer juntas o se excluyen mutuamente, y ajustando las predicciones en consecuencia. Aunque se desarrolló para texto, la misma idea de mejorar predicciones usando relaciones aprendidas entre salidas podría aplicarse a imágenes, datos multimodales y otras tareas de predicción estructurada. En términos sencillos, LCENet ayuda a las máquinas a “recordar” cómo se relacionan las etiquetas, de modo que adivinen menos como casillas aisladas y más como un humano informado que entiende cómo encajan los conceptos.
Cita: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
Palabras clave: clasificación extrema de texto multilabel, correlación de etiquetas, aprendizaje profundo, clasificación de texto, redes neuronales