Clear Sky Science · es
DMSCA: atención dinámica multiescala canal-espacial para una representación de características mejorada en redes neuronales convolucionales
Enseñar a los ordenadores a prestar mejor atención
Los sistemas modernos de reconocimiento de imágenes pueden identificar gatos, señales de tráfico y tumores en exploraciones, pero no siempre saben en qué centrarse dentro de una imagen. Este artículo presenta una nueva forma de ayudar a esos sistemas a concentrarse en las partes más importantes de una imagen, mejorando la precisión y haciéndolos más fiables en las condiciones desordenadas de la vida real. El método, llamado Atención Dinámica Multiescala Canal-Espacial (DMSCA), se integra en redes neuronales convolucionales existentes y les ayuda a percibir tanto el “qué” como el “dónde” en una imagen de forma más inteligente.
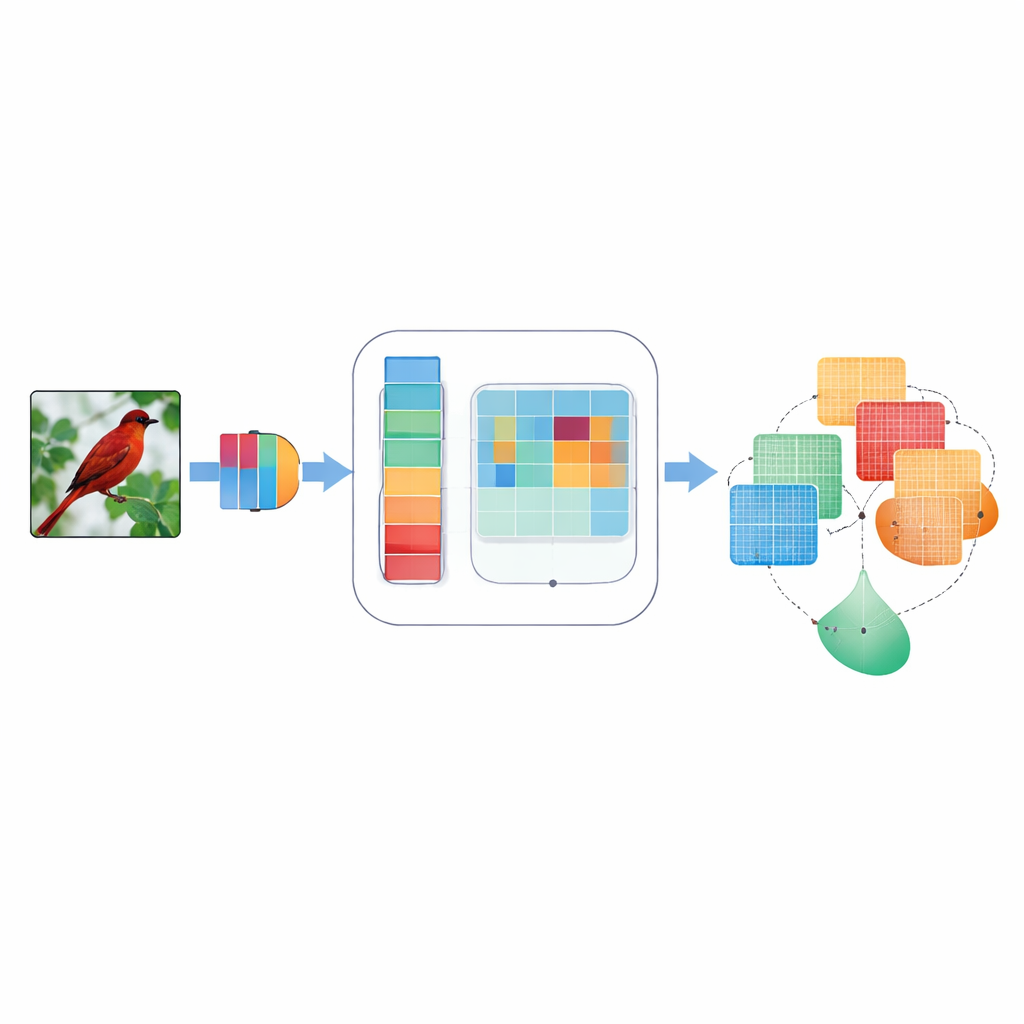
Por qué importa el foco en la visión por máquina
Las redes neuronales convolucionales, los pilares de muchas aplicaciones de visión, suelen tratar cada señal interna como igualmente importante. Eso significa que el borde tenue del ala de un pájaro y un parche de cielo pueden recibir una atención similar, aunque solo uno ayude a identificar la especie. Métodos previos de “atención” intentaron corregir esto ponderando algunas señales internas más que otras, ya sea a lo largo de canales similares a colores o a lo largo de la disposición bidimensional de una imagen. Pero esos métodos a menudo empleaban reglas fijas y diseñadas a mano, observaban sólo una escala de detalle a la vez o combinaban la información de forma rígida que no podía adaptarse a imágenes distintas. Como resultado, a veces pasaban por alto detalles finos, ignoraban direcciones como “horizontal frente a vertical” o tenían dificultades cuando las imágenes estaban ruidosas o borrosas.
Un complemento de atención más inteligente
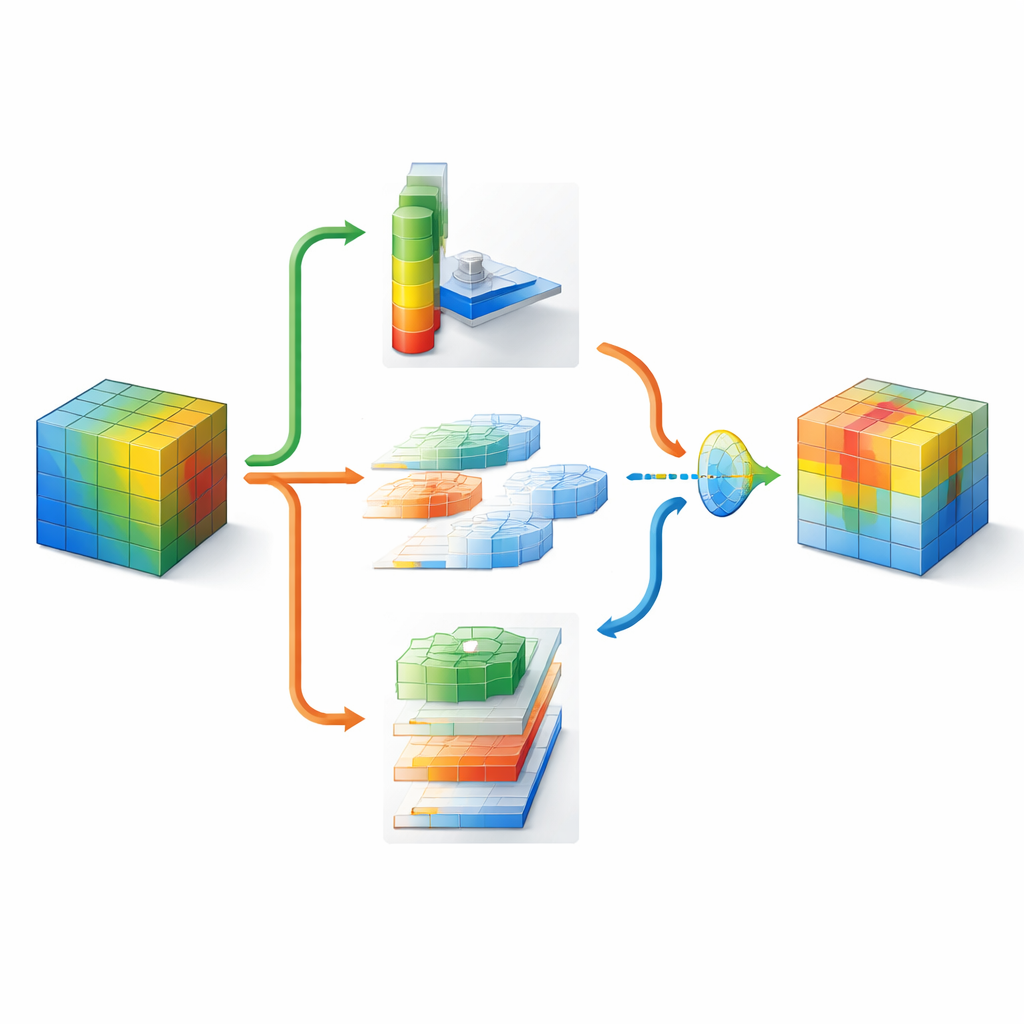
DMSCA está diseñado como un pequeño módulo acoplable que puede insertarse en redes conocidas como ResNet sin cambiar su estructura general. En su interior coordina seis partes estrechamente vinculadas que trabajan en conjunto en lugar de hacerlo de forma aislada. Una parte resume la imagen completa para capturar lo que ocurre a escala global, mientras que otra aprende cuánto debe importar cada canal interno, usando una “temperatura” controlable que puede hacer las decisiones más nítidas o más suaves según sea necesario. En el lado espacial, DMSCA utiliza varios tamaños de ventana a la vez para capturar tanto texturas diminutas como formas más grandes, y presta atención explícita a direcciones horizontales y verticales para que los bordes largos o las franjas no se diluyan. Finalmente, en lugar de simplemente sumar estas señales, el módulo aprende, píxel a píxel, cuánto confiar en la información del “qué” procedente de los canales frente a la información del “dónde” procedente del espacio.
Observar imágenes a muchas escalas y direcciones
Para decidir dónde mirar en una imagen, DMSCA primero comprime los muchos canales internos en un mapa compacto de dos capas que resalta tanto las tendencias de fondo como las características destacadas. A continuación, pasa este mapa por varios filtros paralelos de diferentes tamaños. Los filtros pequeños captan detalles finos como el pelaje o las plumas, mientras que los mayores capturan formas como cabezas o cuerpos completos. En paralelo, una unidad direccional explora filas y columnas por separado, preservando la posición exacta de las estructuras importantes. Estas vistas horizontales y verticales pueden luego interactuar entre sí, de modo que, por ejemplo, una señal vertical fuerte puede reforzar las ubicaciones horizontales adecuadas. El resultado es un mapa de atención rico que le dice a la red no sólo que algo es importante, sino dónde está y a qué escala.
Dejar que la red decida qué importa más
Dado que distintas partes de una imagen pueden requerir estrategias diferentes, DMSCA no impone una receta fija para combinar la información de canal y espacial. En su lugar, construye una pequeña “puerta” que examina ambas y decide, de forma independiente para cada píxel, cuánto peso dar a cada tipo. En un fondo desordenado, el sistema puede fiarse más de qué canales destacan, mientras que alrededor de bordes nítidos de objetos puede enfatizar las señales espaciales. Una etapa final de activación adaptativa actúa como un regulador aprendido, amplificando las regiones verdaderamente informativas y atenuando el ruido residual. Este proceso en varias etapas ayuda a orientar la atención de la red hacia regiones coherentes relacionadas con objetos, como confirman mapas de calor visuales y medidas cuantitativas de cuánto coinciden las áreas resaltadas con los objetos de referencia.
Visión más nítida con un esfuerzo adicional moderado
Los autores evaluaron DMSCA en varios puntos de referencia standard, desde colecciones pequeñas de imágenes diminutas hasta el conjunto a gran escala ImageNet. Al añadirse a modelos ResNet populares, DMSCA mejoró de forma consistente la precisión de clasificación: hasta alrededor de 2 puntos porcentuales en conjuntos pequeños y 1,5 puntos porcentuales en ImageNet, superando a varios métodos de atención existentes. También hizo que los modelos fuesen más robustos frente a degradaciones comunes de la imagen como ruido, desenfoque y compresión intensa, y mejoró el rendimiento en tareas relacionadas como detección de objetos y etiquetado de escenas. Estas mejoras se lograron con sólo un aumento moderado del cómputo y la memoria. En términos simples, DMSCA ofrece a las redes convolucionales una forma más flexible y consciente del contexto para decidir qué mirar y qué ignorar, acercando la visión por máquina al enfoque selectivo de la visión humana.
Cita: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
Palabras clave: mecanismos de atención, reconocimiento de imágenes, redes neuronales convolucionales, representación de características, visión por ordenador robusta