Clear Sky Science · es
Mejorando la recuperación cruzada modal mediante la optimización de grafos de etiquetas y funciones de pérdida híbridas
Buscar con más inteligencia entre imágenes y palabras
Cada día navegamos por océanos de fotos, vídeos y texto. Encontrar exactamente lo que queremos —por ejemplo, todas las imágenes que coinciden con una breve leyenda— depende de lo bien que los ordenadores puedan conectar imágenes con lenguaje. Este artículo explora una nueva forma de hacer esa conexión más precisa, especialmente en escenas del mundo real, desordenadas, donde aparecen muchas ideas y objetos a la vez. El resultado son herramientas de búsqueda más inteligentes que «entienden» mejor lo que queremos, no solo lo que escribimos.
Por qué importa que una imagen tenga muchos significados
Una sola imagen rara vez muestra solo una cosa. Una foto de una ballena saltando en el mar puede implicar el océano, el cielo, las olas, el viento y la fauna a la vez. Cuando etiquetamos una imagen así, a menudo asignamos varias etiquetas que están relacionadas de formas sutiles. Los sistemas de búsqueda existentes suelen tratar esas etiquetas como si fueran casillas independientes. Esa simplificación desecha pistas útiles: si “ballena” aparece a menudo con “mar”, ver una debería aumentar la probabilidad de la otra. Este trabajo se centra en capturar esos lazos ocultos entre etiquetas para que una búsqueda de una idea pueda encontrar imágenes y textos que expresen ideas estrechamente relacionadas.

Construyendo una red de etiquetas conectadas
Los autores introducen una técnica llamada Red Convolucional de Grafos de Dos Capas, o L2-GCN, para modelar cómo se relacionan las etiquetas entre sí. En términos sencillos, cada etiqueta (como “cielo” o “ballena”) se trata como un nodo en una red, y las aristas entre nodos reflejan con qué frecuencia esas etiquetas aparecen juntas. El método permite repetidamente que cada etiqueta «escuche» a sus vecinas, mezclando información de etiquetas relacionadas sin perder su propia identidad. Tras este proceso, el sistema obtiene descripciones de etiquetas más ricas que capturan mejor cómo se estructuran las escenas reales, desde ideas paralelas (“mar” y “playa”) hasta relaciones más jerárquicas (“animal” y “ballena”).
Enseñar a imágenes y textos a compartir un espacio común
Por supuesto, las etiquetas son solo la mitad de la historia; el sistema también necesita aprender de las propias imágenes y textos. El marco utiliza herramientas consolidadas para convertir píxeles y palabras en características numéricas, y luego proyecta ambos tipos de datos en un espacio compartido donde sus significados pueden compararse directamente. Un módulo adversarial —ligeramente inspirado en la dinámica de empujar y tirar de las redes generativas adversarias— desalienta que el modelo se aferre a peculiaridades propias solo de las imágenes o del texto. Esto ayuda a que el espacio compartido se centre en el contenido más que en el formato, de modo que una foto de una calle concurrida y una breve leyenda que la describe queden cerca en este mapa común del significado.
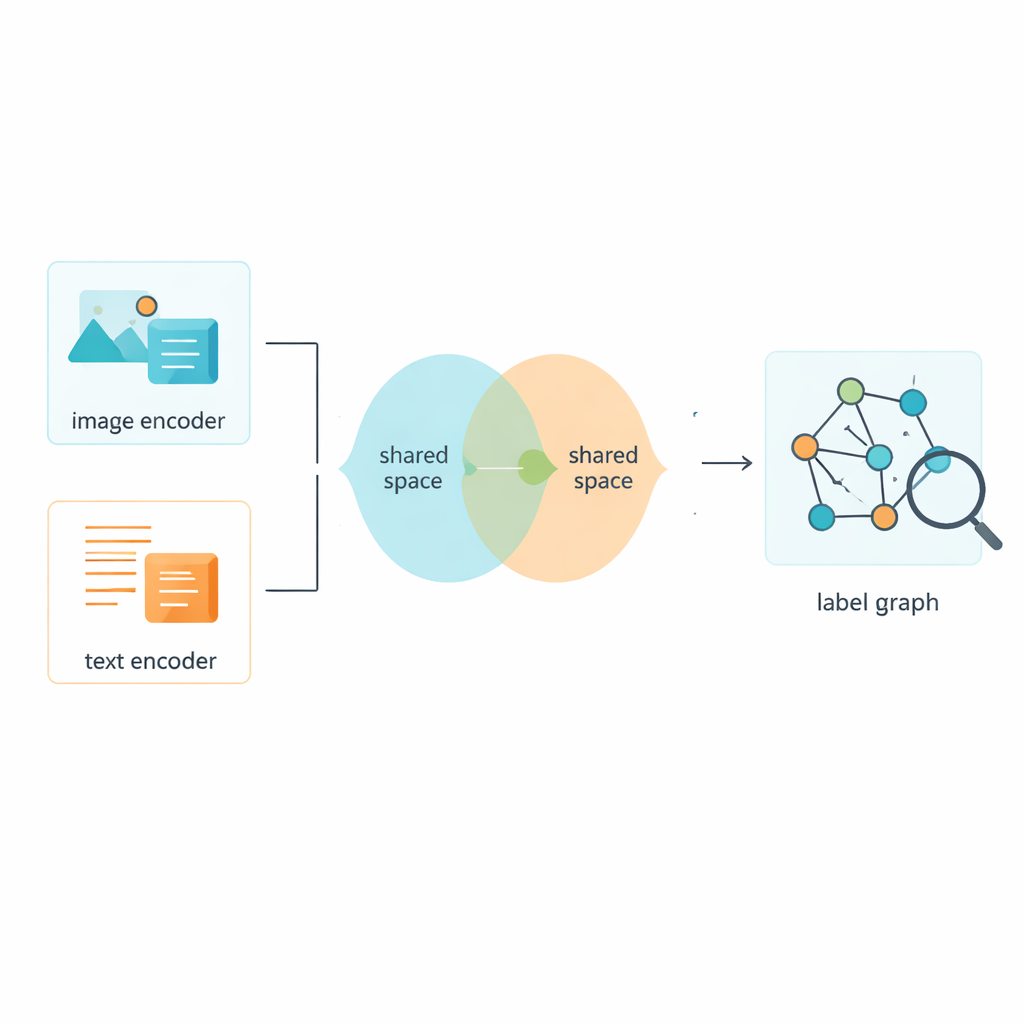
Una estrategia de entrenamiento híbrida para distinciones más nítidas
Entrenar un sistema así requiere más de una regla de aprendizaje. Los autores diseñan una función de pérdida combinada, denominada Circle-Soft, que mezcla dos ideas complementarias. Una parte fomenta que ejemplos de la misma categoría se agrupen estrechamente mientras empuja a las categorías diferentes a separarse de forma flexible y adaptativa. La otra parte se centra en qué tan bien se alinean imágenes y textos que describen la misma escena a través de formatos. Un peso ajustable equilibra estos dos objetivos para que el modelo no sobreajuste ni a límites categóricos rígidos ni únicamente a la alineación cruzada modal. Pérdidas adicionales de clasificación y adversariales fomentan además la coherencia entre las etiquetas refinadas y las características compartidas de imagen y texto.
¿Cuánto mejora esto la búsqueda?
Para comprobar si estas ideas se traducen en mejor búsqueda, los autores evaluaron su método en tres colecciones populares de pares imagen–texto del mundo real: MIRFlickr, NUS-WIDE y MS-COCO. Estos conjuntos de datos contienen desde miles hasta cientos de miles de fotos con etiquetas o leyendas asociadas, cubriendo escenas cotidianas desde calles de la ciudad hasta fauna. En los tres benchmarks, el nuevo enfoque superó de forma consistente a una amplia gama de métodos competidores, incluidos otros sistemas avanzados que ya usan modelado de etiquetas basado en grafos. Las ganancias —alrededor de medio punto porcentual hasta un punto porcentual en una métrica estricta de recuperación— pueden parecer modestas, pero en benchmarks maduros incluso pequeñas mejoras señalan una comprensión más precisa del contenido. En términos prácticos, esto significa que cuando un usuario introduce una consulta de texto corta o envía una imagen, el sistema tiene más probabilidades de mostrar las coincidencias cruzadas más relevantes en la parte superior de los resultados.
Qué significa esto para los usuarios cotidianos
Para los no especialistas, el mensaje clave es que un manejo más inteligente de las etiquetas y las reglas de entrenamiento puede mejorar notablemente cómo las máquinas conectan imágenes y palabras. Al tratar las etiquetas como una red interconectada en lugar de etiquetas aisladas, y al modelar con cuidado cómo se encuentran la información visual y textual en un espacio compartido, este marco hace que la búsqueda cruzada modal sea más fiable en escenas complejas y multi-temáticas. Con el tiempo, técnicas como esta podrían impulsar bibliotecas de fotos más intuitivas, plataformas de medios y asistentes inteligentes que encuentran lo que queremos —incluso cuando nuestras palabras no coinciden exactamente con las imágenes que tenemos en mente.
Cita: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
Palabras clave: recuperación imagen-texto, búsqueda multimodal, redes neuronales de grafos, etiquetas semánticas, aprendizaje automático