Clear Sky Science · es
Un marco de aprendizaje profundo explicable para la detección de enfermedades en cultivos con pocos ejemplos en arroz y caña de azúcar mediante extracción de características basada en CNN
Por qué importa detectar hojas enfermas
El arroz y la caña de azúcar alimentan a miles de millones de personas y sostienen a numerosas comunidades agrícolas. Cuando sus hojas sucumben a enfermedades, las cosechas pueden reducirse considerablemente, los precios de los alimentos pueden aumentar y los agricultores pueden perder su sustento. Sin embargo, el diagnóstico temprano es difícil: los problemas suelen empezar como pequeñas manchas o cambios de color que los agricultores ocupados pueden pasar por alto, y los expertos no siempre están cerca. Este estudio presenta un sistema informático que puede aprender a partir de solo unas pocas fotos de hojas, señalar automáticamente las enfermedades e incluso mostrar exactamente qué elementos de la imagen llevaron a su diagnóstico, ayudando a los agricultores a actuar antes y con mayor confianza.
Ojos inteligentes para el campo
Los investigadores se centran en dos cultivos básicos: arroz y caña de azúcar. Se apoyan en dos colecciones públicas de imágenes de hojas, una capturada en campos reales de caña de azúcar con muchos modelos distintos de teléfonos inteligentes, y un conjunto más pequeño y controlado de fotos de hojas de arroz. Cada imagen muestra una hoja sana o una con una enfermedad concreta, como manchas marrones, pústulas de tono rojizo o franjas amarillas. Al basarse en estos conjuntos de datos compartidos en lugar de colecciones privadas, el equipo persigue métodos que otros grupos puedan probar, reutilizar y, eventualmente, integrar en herramientas agrícolas reales, desde aplicaciones móviles hasta sensores conectados en campos inteligentes.

Enseñar a las máquinas con muy pocos ejemplos
La inteligencia artificial moderna puede ser extraordinariamente buena reconociendo enfermedades de las plantas, pero por lo general exige miles de imágenes etiquetadas por cada condición—una exigencia alta en agricultura, especialmente para brotes nuevos o raros. Para sortear este obstáculo, los autores usan el aprendizaje de "pocos ejemplos" (few-shot), una familia de técnicas diseñadas para aprender a partir de solo unas cuantas muestras. Su marco comienza con pasos estándar de procesamiento de imágenes: limpieza, cambio de tamaño y normalización de cada foto para que el ordenador vea una vista consistente. Un tipo de modelo de aprendizaje profundo llamado red neuronal convolucional convierte entonces cada imagen de hoja en un conjunto compacto de características numéricas que capturan formas, colores y texturas relevantes para la enfermedad.
Hacer comprensible el diagnóstico
Sobre estas características, el equipo entrena dos métodos avanzados de few-shot llamados Prototypical Networks y Model-Agnostic Meta-Learning. Uno aprende una especie de "centro" para cada enfermedad en el espacio de características y asigna las hojas nuevas al centro más cercano; el otro aprende a adaptarse con rapidez a nuevas tareas con solo unos pocos pasos de entrenamiento. De forma crucial, los autores combinan estos métodos con herramientas de IA explicable. Usando técnicas tipo mapa de calor, el sistema puede resaltar qué partes de la imagen de la hoja influyeron más en su decisión—un grupo de manchas oscuras, una franja amarilla a lo largo del nervio central, o la ausencia de lesiones evidentes en una planta sana. Esto hace visible el razonamiento del modelo, permitiendo a los agrónomos comprobar si el ordenador se está centrando en signos médicamente relevantes en lugar de en elementos de fondo irrelevantes.
Cómo rinde el sistema
Para evaluar si su enfoque es realmente útil, los investigadores lo comparan con varios modelos de aprendizaje profundo bien conocidos que se han utilizado en la detección de enfermedades vegetales. Dividen cada conjunto de datos en porciones de entrenamiento y prueba y miden con qué frecuencia cada método identifica correctamente el tipo de enfermedad. En hojas de caña de azúcar tomadas en el campo, el nuevo marco alcanza alrededor del 92 por ciento de clasificación correcta, superando arquitecturas estándar como VGG, ResNet, Xception y EfficientNet. En el conjunto de datos de arroz, rinde aún mejor, identificando correctamente alrededor del 98 por ciento de las imágenes de prueba. Herramientas estadísticas que analizan el equilibrio entre falsas alarmas y casos perdidos muestran que el nuevo método se comporta como un excelente cribador médico en lugar de un adivinador aleatorio.
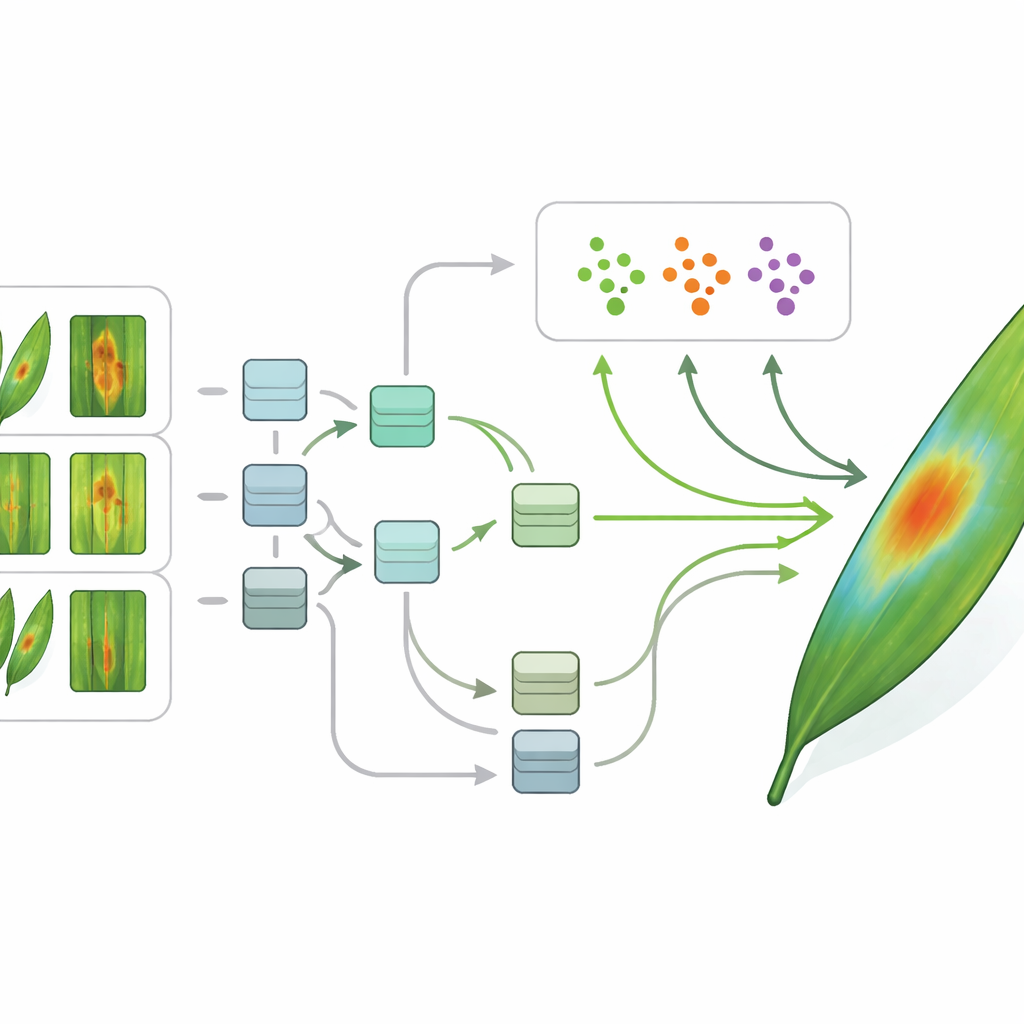
Qué significa esto para los agricultores
En términos sencillos, el estudio demuestra que un ordenador puede aprender a detectar con precisión múltiples enfermedades del arroz y la caña de azúcar a partir de solo un pequeño número de imágenes de ejemplo, y además puede señalar las mismas manchas y franjas en la hoja que motivaron su veredicto. Esta combinación de eficiencia en el uso de datos y transparencia es clave para el uso en el mundo real: reduce la barrera para desarrollar herramientas para cultivos nuevos y enfermedades emergentes, y aporta a agricultores y expertos evidencia visual en la que pueden confiar. Con pruebas adicionales en campos reales y interfaces de usuario más amigables, sistemas explicables y de few-shot como este podrían convertirse en colaboradores cotidianos en la agricultura inteligente, ayudando a proteger las cosechas y reduciendo el uso innecesario de pesticidas.
Cita: El-Behery, H., Attia, AF. & Rezk, N.G. An explainable deep learning framework for few shot crop disease detection in rice and sugarcane using CNN based feature extraction. Sci Rep 16, 8272 (2026). https://doi.org/10.1038/s41598-026-37501-2
Palabras clave: detección de enfermedades en cultivos, arroz y caña de azúcar, aprendizaje profundo, IA explicable, agricultura inteligente