Clear Sky Science · es
Un marco de aprendizaje profundo basado en DNABERT para predecir sitios de unión de factores de transcripción
Por qué importa predecir los interruptores de control del ADN
Cada célula de tu cuerpo porta esencialmente el mismo ADN, sin embargo las neuronas, las células hepáticas y las células inmunitarias se comportan de forma muy distinta. Una razón es que proteínas especiales llamadas factores de transcripción actúan como interruptores moleculares, activando o desactivando genes al acoplarse en tramos cortos de ADN conocidos como sitios de unión. Identificar experimentalmente todos estos puntos de acoplamiento a lo largo del genoma es lento y costoso. Este estudio presenta TFBS-Finder, un nuevo modelo de inteligencia artificial capaz de leer las letras crudas del ADN y predecir con mayor precisión dónde se unen los factores de transcripción, acelerando potencialmente la investigación sobre regulación génica y enfermedades.
Leer el ADN como un idioma
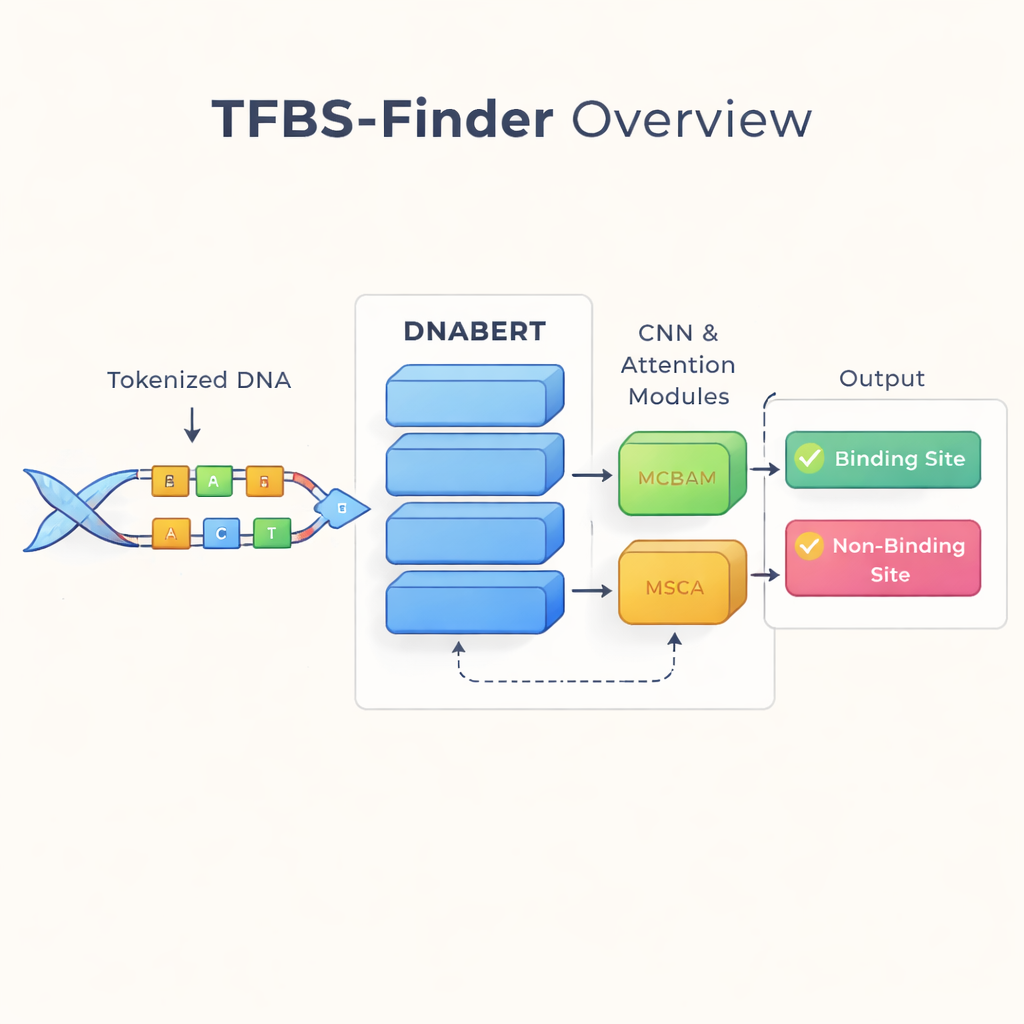
Los autores se basan en una idea que ha transformado la tecnología del lenguaje: tratar el ADN como si fuera texto. Emplean DNABERT, una versión del modelo de lenguaje BERT reentrenada con ADN humano en lugar de palabras. DNABERT no mira sólo letras individuales; divide el ADN en “palabras” solapadas de cinco letras y aprende cómo tienden a coocurrir estos fragmentos. Esto permite al modelo captar contexto a largo alcance, por ejemplo cómo los patrones en un extremo de una secuencia se relacionan con patrones lejanos, de forma similar a entender el sentido de una oración en lugar de palabras aisladas.
Encontrar patrones locales con atención focalizada
Mientras que DNABERT es bueno captando el contexto global, la unión de factores de transcripción a menudo depende de motivos muy cortos y precisos—patrones locales en el ADN. Por eso TFBS-Finder añade varios componentes sobre DNABERT. Una red neuronal convolucional (CNN) recorre las incrustaciones de la secuencia para resaltar formas locales recurrentes, de manera análoga a cómo el software de imagen detecta bordes y esquinas. Dos módulos de atención, llamados MCBAM y MSCA, actúan después como focos ajustables, reforzando las características más informativas y atenuando el ruido. Juntos, estos bloques equilibran la visión de conjunto con los detalles finos para decidir si un segmento de ADN contiene un sitio de unión real.
Demostrar que cada pieza realmente ayuda
Para comprobar si todos estos componentes eran necesarios, el equipo realizó extensos experimentos de “ablación”, eliminando o reordenando módulos de forma sistemática y reentrenando el sistema en 165 conjuntos de referencia que cubren 29 factores de transcripción en 32 tipos celulares. Usando medidas estándar de calidad predictiva, el modelo completo TFBS-Finder se situó consistentemente en la cima. Versiones más simples que dependían solo de DNABERT, o que omitían uno de los módulos de atención, perdieron claramente precisión. Pruebas estadísticas confirmaron que esas caídas en rendimiento no se debían al azar, mostrando que la combinación de comprensión global de la secuencia y una atención diseñada cuidadosamente a los patrones locales es crucial.
Funcionamiento entre tipos celulares y superando herramientas anteriores
Una cuestión importante es si un modelo entrenado en un contexto biológico puede generalizar a otro. Los autores se centraron en un factor de transcripción bien estudiado llamado CTCF y entrenaron TFBS-Finder con datos de una línea celular y luego lo probaron en otras. En todas las combinaciones, el modelo alcanzó puntuaciones altas, lo que sugiere que captó rasgos centrales de la unión de CTCF compartidos entre tejidos. Al compararlo con nueve métodos líderes, incluidos modelos previos de aprendizaje profundo y basados en BERT, TFBS-Finder mostró mayor precisión media y produjo clasificaciones de sitios de unión más fiables. Además, se ejecutó ligeramente más rápido y consumió menos memoria que el modelo previo más similar, lo que indica que un mejor rendimiento no requirió mayor coste computacional.
Ver lo que el modelo ha aprendido
Los sistemas de IA complejos suelen ser criticados como “cajas negras”. Aquí, los investigadores intentaron abrir esa caja visualizando qué posiciones del ADN influyeron más en las decisiones de TFBS-Finder. Para dos factores de transcripción con motivos bien conocidos, CEBPB y GATA3, generaron puntuaciones de importancia a lo largo de la secuencia y agruparon las señales más fuertes en patrones consensuados. Estos motivos recuperados coincidieron estrechamente con motivos de referencia de bases de datos establecidas, y las regiones de unión predichas se solaparon con instancias de motivos detectadas de forma independiente. Esto sugiere que TFBS-Finder no está simplemente memorizando ejemplos, sino que ha aprendido reglas biológicamente significativas sobre cómo los factores de transcripción reconocen el ADN.
Qué significa esto para la genética y la medicina
TFBS-Finder ofrece una forma más precisa e interpretable de mapear los interruptores de control incrustados en nuestro ADN. Al localizar dónde es probable que se unan los factores de transcripción, puede ayudar a los investigadores a trazar redes reguladoras de genes, priorizar qué variantes genéticas podrían alterar sitios de control cruciales y diseñar experimentos más dirigidos. Aunque el trabajo actual usa secuencias barajadas como negativos artificiales y se centra solo en las letras del ADN, los autores planean añadir información estructural sobre la forma del ADN y explorar secuencias de fondo más realistas. A medida que estos modelos mejoren, podrían convertirse en herramientas poderosas para comprender cómo los cambios en el ADN no codificante contribuyen al desarrollo, la evolución y el riesgo de enfermedad.
Cita: Dutta, P., Ghosh, N. & Santoni, D. A DNABERT based deep learning framework for predicting transcription factor binding sites. Sci Rep 16, 7018 (2026). https://doi.org/10.1038/s41598-026-37483-1
Palabras clave: sitios de unión de factores de transcripción, aprendizaje profundo, DNABERT, regulación génica, genómica