Clear Sky Science · es
Mejora de la representación del conocimiento médico en modelos de lenguaje grande mediante la optimización de tokens clínicos
Por qué importa una lectura médica más inteligente
Detrás de todo asistente médico de IA hay una habilidad simple pero crítica: cómo divide el texto en fragmentos que puede comprender. Cuando ese “corte” falla —especialmente con términos médicos chinos complejos— la IA puede pasar por alto ideas clave en las notas de los médicos o en las preguntas de los pacientes. Este artículo muestra cómo un cambio pequeño pero dirigido en ese primer paso puede mejorar la capacidad de los modelos de lenguaje grandes para leer, razonar y responder preguntas sobre datos médicos chinos, sin construir un sistema completamente nuevo desde cero.
Dividir el texto en piezas de la forma correcta
Los modelos de lenguaje modernos no leen caracteres o palabras directamente; primero convierten el texto en unidades cortas llamadas tokens. En inglés esto funciona bastante bien porque los espacios ya marcan los límites de palabra. El chino es más complejo: no hay espacios y muchas expresiones médicas son frases largas y especializadas. Los tokenizadores estándar, diseñados principalmente para inglés, tienden a cortar esas frases en fragmentos arbitrarios. Cuando un modelo ve un nombre de enfermedad o una prueba de laboratorio dividido en varias piezas disjuntas, le resulta más difícil aprender lo que ese término realmente significa y sus respuestas a preguntas médicas pueden volverse vagas o inexactas.
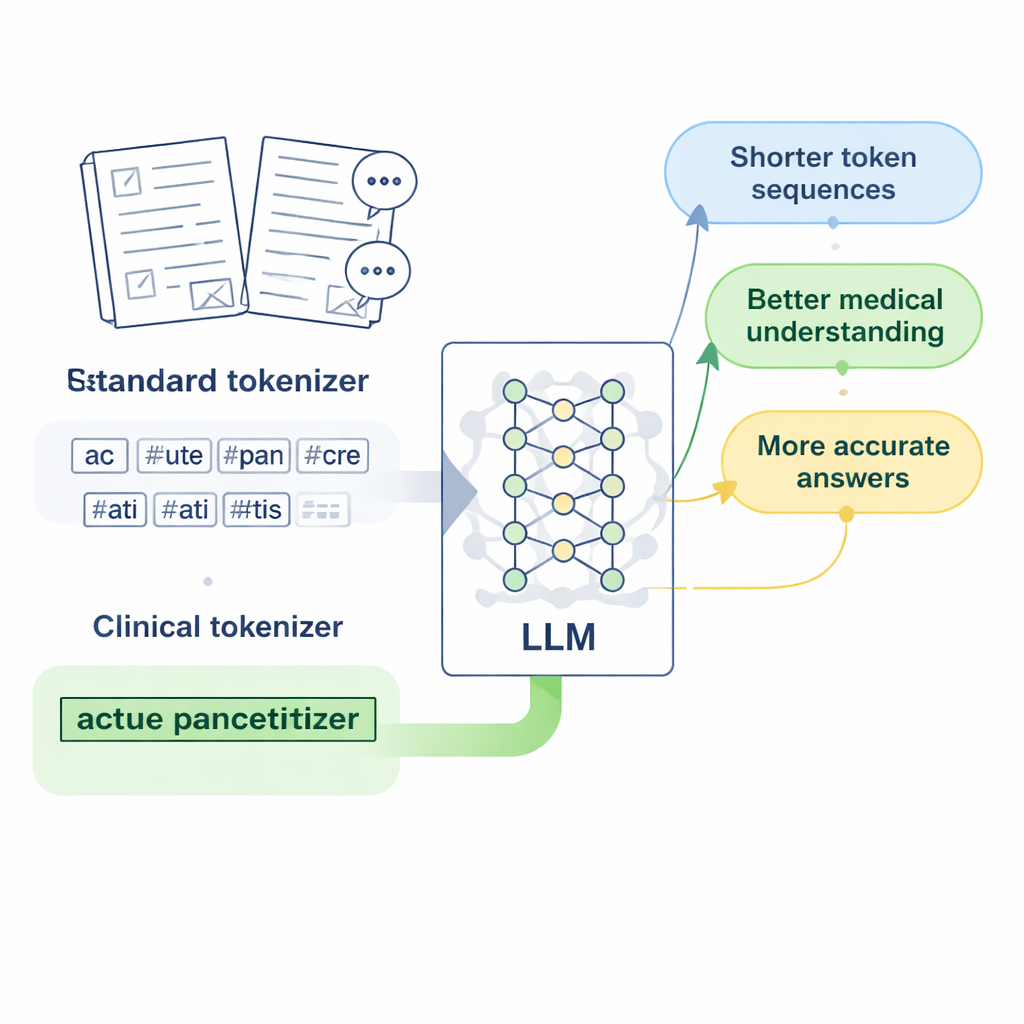
Diseñar “tokens clínicos” para la medicina china
Los investigadores se centran en LLaMA2, un modelo de lenguaje grande de código abierto popular, y se preguntan: ¿y si simplemente enseñamos a su tokenizador un vocabulario médico más rico? Reúnen grandes colecciones de texto médico chino, incluidos bases de datos cuidadosamente revisadas de medicina tradicional china, miles de registros clínicos y pares de preguntas y respuestas médico–paciente. Usando una versión a nivel de bytes del algoritmo Byte Pair Encoding, implementada con la herramienta SentencePiece, entrenan un nuevo tokenizador que aprende a mantener expresiones médicas comunes juntas como unidades únicas. Estas nuevas unidades, que los autores llaman “tokens clínicos”, se integran luego en el vocabulario original de LLaMA2, ampliándolo para cubrir mejor el lenguaje médico chino sin descartar lo que el modelo ya sabe.
De mejores tokens a un mejor modelo médico
Añadir nuevos tokens es solo el primer paso; el modelo debe aprender buenas representaciones para ellos. El equipo ajusta la capa de embeddings interna de LLaMA2 para que pueda almacenar vectores para el vocabulario ampliado y prueba dos formas de inicializar estos nuevos vectores. Un método promedia los vectores de las subpartes antiguas de cada palabra, mientras que el otro utiliza valores aleatorios cuidadosamente escalados. Contraintuitivamente, el método aleatorio rinde mejor, probablemente porque evita encasillar al modelo en una suposición inicial pobre sobre el significado de cada término. Los autores continúan entonces entrenando el modelo con texto médico y lo ajustan finamente en estilo instruccional de preguntas y respuestas médicas usando un método eficiente en recursos llamado LoRA, produciendo una versión especializada que denominan Medical-LLaMA.
Medir ganancias en velocidad, contexto y precisión
Con el vocabulario ampliado, cada carácter chino requiere ahora aproximadamente la mitad de tokens que antes, lo que significa que el modelo puede procesar pasajes más largos dentro de la misma ventana de tokens fija. En la práctica, la longitud efectiva del contexto en chino se duplica aproximadamente, y el tiempo de afinado en un gran conjunto de preguntas y respuestas médicas se reduce casi a la mitad. Para evaluar la calidad de las respuestas, los autores combinan dos estrategias: BERTScore, que mide cuán cercano semánticamente es una respuesta generada respecto a una referencia, y un modelo de valoración sofisticado (DeepSeek-R1) que puntúa relevancia, exactitud, completitud y fluidez. Según estas métricas, Medical-LLaMA supera de forma consistente tanto al LLaMA2 original como a una variante optimizada para chino que no incluyó tokens específicos médicos. También muestra mejoras pequeñas pero constantes en tareas relacionadas como el reconocimiento de entidades médicas y la clasificación de texto clínico, todo ello preservando el rendimiento en preguntas generales no médicas.
Qué significa esto para la IA médica futura
Para los no especialistas, el mensaje clave es que unas “gafas de lectura” más inteligentes para la IA —aquí, una mejor manera de fragmentar el lenguaje médico— pueden mejorar notablemente cómo entiende y responde a preguntas de salud. Al insertar tokens clínicos bien escogidos en el vocabulario de un modelo existente, los autores aumentan tanto la eficiencia como la precisión sin requerir entrenamientos masivos nuevos ni arquitecturas totalmente nuevas. Aunque el trabajo se limita a un modelo de 7 000 millones de parámetros y a texto médico en chino, apunta a una receta práctica: adaptar la capa más temprana del procesamiento del lenguaje al dominio y luego volver a entrenar ligeramente. Esta estrategia puede ayudar a que futuras herramientas de IA médica se conviertan en socios más fiables para clínicos y pacientes, especialmente en idiomas y especialidades que los modelos estándar tienen dificultades para leer.
Cita: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
Palabras clave: modelos de lenguaje médicos, texto clínico chino, tokenización, vocabulario clínico, preguntas y respuestas médicas