Clear Sky Science · es
AE-LFOG-YOLO: detección robusta de cascos de seguridad mediante anclas adaptativas y aprendizaje invariante a la iluminación
Por qué importan las inspecciones inteligentes de cascos
En grandes obras de construcción y en túneles subterráneos, un sencillo casco de seguridad puede marcar la diferencia entre un susto y una lesión que cambie la vida. Sin embargo, en el caos de los emplazamientos reales, la gente olvida o evita llevar casco, y los supervisores humanos no pueden vigilar cada rincón continuamente. Este estudio explora cómo construir un sistema de cámaras automatizado que identifique con fiabilidad quién lleva casco y quién no, incluso cuando el túnel está oscuro, lleno de reflejos de las lámparas o abarrotado de trabajadores a distintas distancias de la cámara.
Retos de ver con iluminación extrema en túneles
Los sitios de construcción en túneles son entornos visualmente extremos. Focos intensos generan deslumbramientos, mientras que profundos bolsillos de sombra ocultan detalles. Las personas se acercan o alejan de la cámara, por lo que sus cascos aparecen en muchos tamaños distintos. Los detectores de inteligencia artificial estándar fallan a menudo en estas condiciones: pasan por alto cascos en zonas oscuras, confunden otros objetos redondeados con cascos o tienen problemas con trabajadores muy pequeños o lejanos. Muchos sistemas existentes intentan arreglar esto iluminando o limpiando las imágenes antes de la detección, o ajustando algunos componentes de modelos de detección YOLO populares. Pero como estos pasos suelen ser parches añadidos en lugar de formar parte de un único proceso de aprendizaje, dejan rendimiento sobre la mesa y no son robustos cuando cambia la iluminación o la disposición de la escena.
Una nueva forma de enseñar a las cámaras a ignorar la mala iluminación
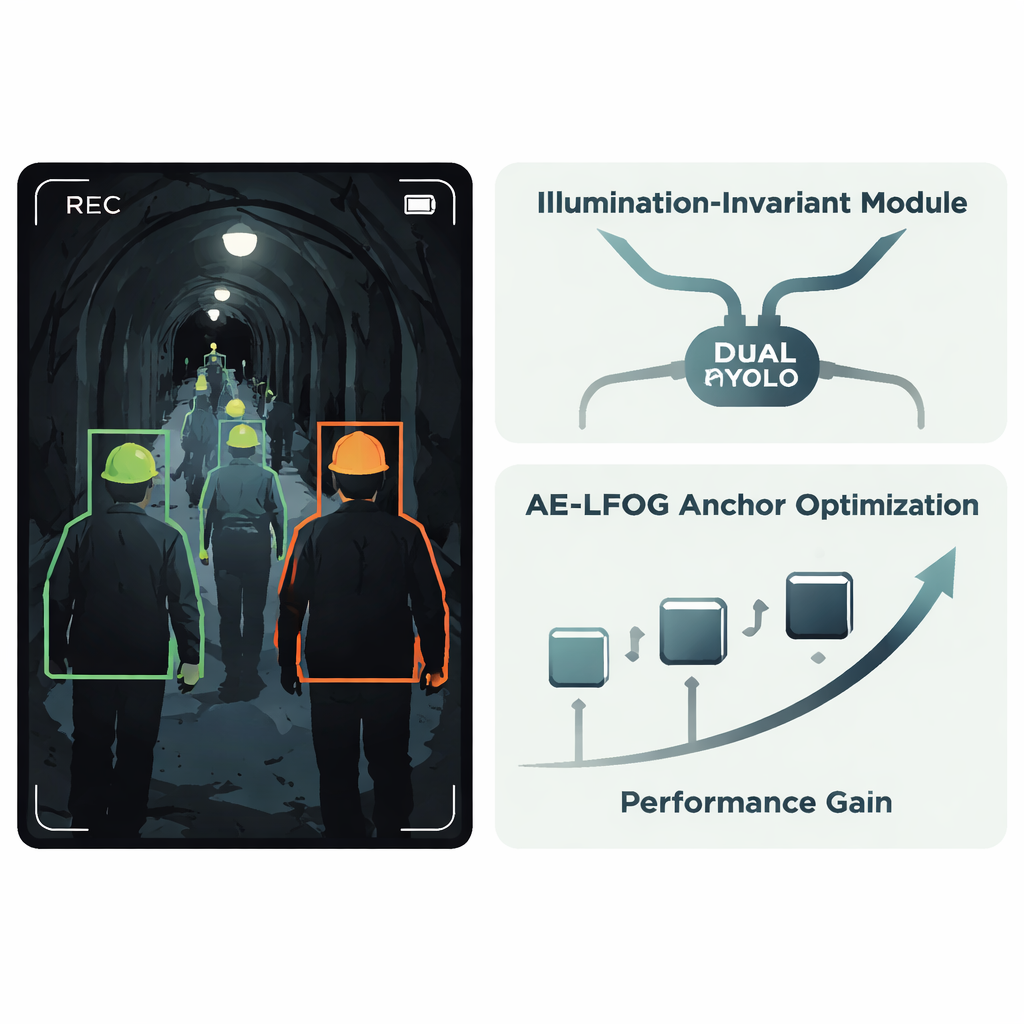
Los autores proponen un sistema mejorado llamado AE‑LFOG‑YOLO, construido sobre el detector YOLOv8 ampliamente usado. La primera idea clave es un Módulo Invariante a la Iluminación, una unidad pequeña añadida dentro de la red que aprende a separar “lo que hace la luz” de “cómo son realmente los objetos”. Divide los mapas de características entrantes en una parte que refleja principalmente patrones de iluminación y otra que captura formas y texturas más estables, como el borde curvado de un casco. Mediante operaciones de compuerta especiales y una rama centrada en bordes y esquinas, el módulo atenúa los vaivenes de brillo y enfatiza la geometría estable. Al ocurrir esto dentro del detector en lugar de en un paso de preprocesado separado, todo el sistema puede entrenarse de extremo a extremo para concentrarse en los cascos en sí en vez de dejarse engañar por parches de deslumbramiento u oscuridad.
Dejar que el modelo evolucione sus propios hábitos de visión
La segunda idea principal se dirige a cómo el detector estima dónde pueden aparecer los objetos. Muchos detectores parten de un conjunto fijo de “cajas ancla” que sugieren tamaños y formas probables; estas suelen elegirse una vez a partir de los datos de entrenamiento y no se actualizan. En los túneles, sin embargo, el tamaño aparente de un casco puede cambiar drásticamente con la distancia de la cámara y el ángulo de visión. AE‑LFOG‑YOLO sustituye las anclas estáticas por un proceso dinámico llamado Generación Evolutiva Adaptativa optimizada por Campo de Luz. Al final de cada ciclo de entrenamiento, el sistema perturba suavemente sus cajas ancla, evalúa qué tan bien coinciden con cascos reales de todos los tamaños y además comprueba si sus dimensiones tienen sentido dadas las nociones básicas de óptica de cámara—cuánto debería ocupar un casco real en el sensor a distancias de trabajo típicas. Los conjuntos de anclas con mejor puntuación sobreviven a la siguiente ronda. Con el tiempo, el detector “evoluciona” anclas que se ajustan tanto a los datos como a la forma en que las cámaras realmente representan el mundo.
Adaptar el entrenamiento a la calidad real de la imagen
Más allá de cambiar qué busca el modelo, los autores también modifican cómo aprende. Introducen una estrategia de entrenamiento que presta más atención a localizar con precisión los cascos cuando la calidad de la imagen es pobre, y más atención a clasificar correctamente casco versus sin casco cuando las condiciones son buenas. Una puntuación basada en la física, también derivada de principios de captura de imagen por cámara, indica al sistema cuán fiables son las imágenes en cada etapa. Si la iluminación o el enfoque son malos, el proceso de entrenamiento aumenta automáticamente la importancia de acertar las cajas delimitadoras; si las condiciones mejoran, desplaza el peso hacia la clasificación. Esto crea un bucle de retroalimentación en el que el modelo ajusta continuamente sus prioridades para coincidir con el entorno físico que enfrentará en túneles reales.
Qué muestran las pruebas en la práctica
Los investigadores prueban su enfoque en un conjunto de datos real de cascos en túneles y lo comparan con varios métodos avanzados basados en YOLO. AE‑LFOG‑YOLO detecta cascos con muy alta precisión, identificando correctamente alrededor del 95 por ciento de los cascos con un umbral de solapamiento estándar y superando a la línea base de YOLOv8 tanto en precisión como en exhaustividad. Funciona lo bastante rápido para uso en tiempo real y resulta especialmente eficaz cuando la iluminación se manipula intensamente para simular oscuridad extrema o sobreexposición. En estas condiciones duras, el nuevo modelo mantiene una confianza mayor, detecta más trabajadores pequeños y distantes, y opera sobre un rango de brillo que es más de un tercio más amplio que el de la línea base, lo que significa que se mantiene fiable en un conjunto mucho mayor de escenas del mundo real.
Cómo esto ayuda a proteger a los trabajadores
Para el público no especializado, la conclusión es directa: al enseñar a un sistema de IA a entender no solo los píxeles sino también la física de cómo las cámaras ven en entornos difíciles, este trabajo ofrece un vigilante en la pared del túnel más inteligente y más fiable. AE‑LFOG‑YOLO puede ignorar mejor la iluminación engañosa y adaptarse a vistas cambiantes, reduciendo detecciones perdidas y falsas alarmas. Desplegado durante meses en una línea de transporte ferroviario en operación, ya ha demostrado que puede apoyar a los equipos de seguridad para asegurarse de que los trabajadores llevan puestos sus cascos, ofreciendo un paso práctico hacia obras de construcción más seguras y más monitorizadas.
Cita: Liu, S., Wang, J. AE-LFOG-YOLO: robust safety helmet detection via adaptive anchors and illumination invariant learning. Sci Rep 16, 6402 (2026). https://doi.org/10.1038/s41598-026-37326-z
Palabras clave: detección de cascos de seguridad, construcción de túneles, visión por computador, imágenes en baja luminosidad, YOLOv8