Clear Sky Science · es
Aplicación del aprendizaje contrastivo auto‑supervisado jerárquico en la adaptación de dominio para el emparejamiento de imágenes multomoda de teledetección
Ver la Tierra desde diferentes ojos
Satélites meteorológicos, misiones radar y cámaras espaciales de alta resolución observan el mismo planeta de maneras muy distintas. Esta diversidad es una ventaja para tareas como el seguimiento de inundaciones, el mapeo de ciudades o la monitorización de bosques, siempre que podamos alinear las imágenes de forma fiable. El artículo resumido aquí presenta un nuevo método de inteligencia artificial que enseña a los ordenadores a emparejar estas distintas visiones de la Tierra con mayor precisión y con mucha menos anotación humana, abriendo la puerta a una vigilancia ambiental más rápida y robusta.
Por qué es tan difícil emparejar imágenes distintas
Las imágenes de teledetección proceden de muchos tipos de sensores: cámaras ópticas que ven como nuestros ojos, radares que miden la rugosidad de la superficie e instrumentos multiespectrales que capturan sutiles diferencias de color. Dado que cada sensor “ve” a su manera, el mismo edificio, barco o campo puede parecer completamente distinto de una imagen a otra: granuloso en radar, nítido en óptico o con tonalidades inusuales en vistas multiespectrales. Los métodos tradicionales para emparejar imágenes dependen de características visuales diseñadas a mano o de aprendizaje profundo totalmente supervisado que requiere grandes cantidades de datos etiquetados cuidadosamente. Ambos enfoques suelen fallar cuando la brecha de apariencia entre sensores es grande o cuando los ejemplos etiquetados escasean, como suele ocurrir durante desastres o en regiones remotas.
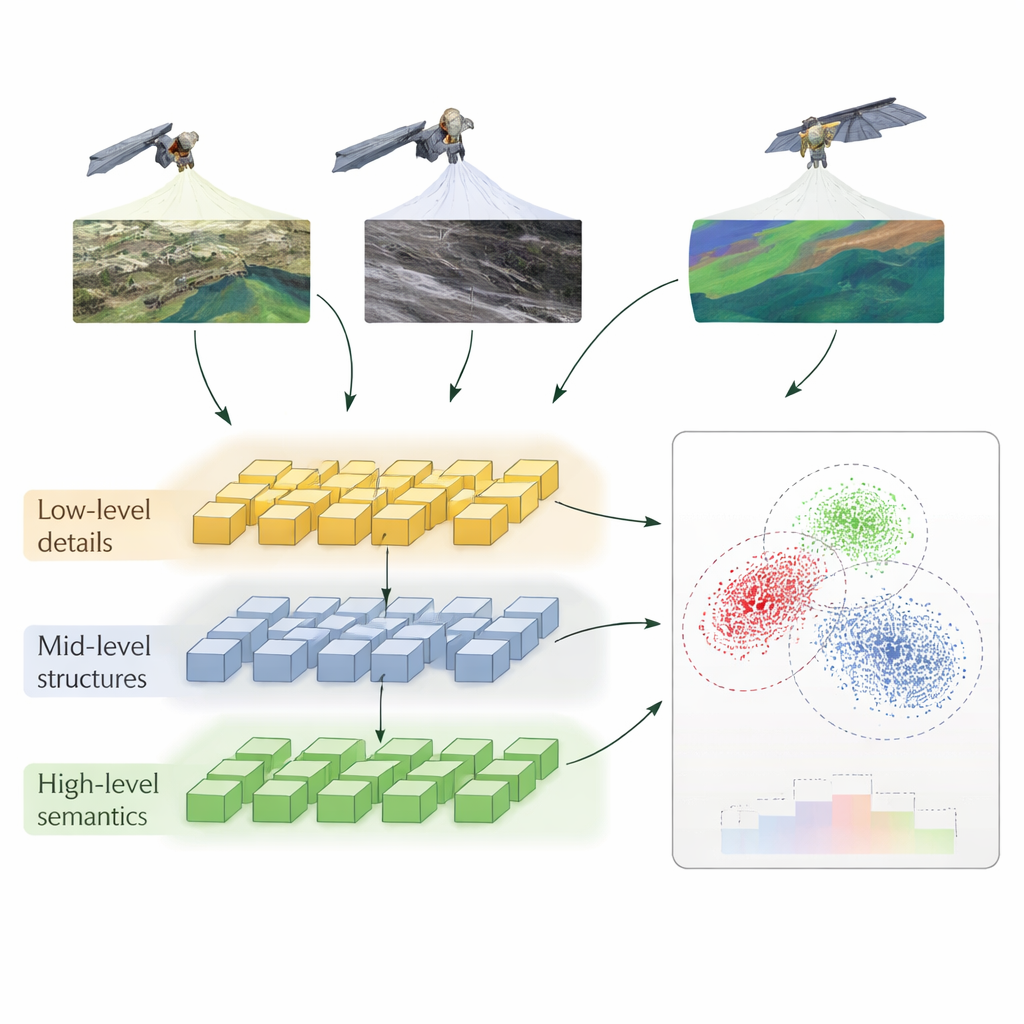
Una forma por capas de enseñar a los ordenadores a comparar
Los autores proponen un método llamado Aprendizaje Contrastivo Auto‑Supervisado Jerárquico (HSSCL, por sus siglas en inglés), que cambia la forma en que una red neuronal aprende a comparar imágenes. En lugar de fijarse solo en un resumen único de cada imagen, la red extrae información en tres niveles: detalles finos como bordes y texturas, patrones de escala media como carreteras y contornos de edificios, y patrones amplios como la disposición urbana o tipos de uso del suelo. En cada nivel, el sistema incentiva que las características procedentes de distintos sensores que muestran la misma zona se hagan más similares, mientras separa las características que provienen de áreas no relacionadas. Este entrenamiento “contrastivo” ocurre sin etiquetas humanas: el modelo usa el emparejamiento conocido de imágenes de distintos sensores sobre la misma ubicación, además de ejemplos similares encontrados automáticamente, para construir una idea rica de cómo se ve “el mismo lugar” a través de modalidades.
Limpiar el ruido y preservar la geometría
Los datos de teledetección del mundo real son desordenados: las imágenes radar contienen ruido salpicado, las imágenes ópticas pueden estar brumosas y todas pueden estar desalineadas por unos pocos píxeles. HSSCL aborda esto dividiendo primero las imágenes en pequeños bloques y aplicando desruido adaptado, lo que ayuda a la red a centrarse en estructuras significativas en lugar de en fluctuaciones aleatorias. A continuación, alimenta características de distintos bloques a un módulo basado en grafos que trata cada región como un nodo y enlaza regiones que están cercanas y se parecen. Al operar sobre este grafo, una red neuronal de grafos especializada refuerza la consistencia geométrica de los emparejamientos, haciendo más probable que carreteras coincidan con carreteras y edificios con edificios, incluso en condiciones difíciles.
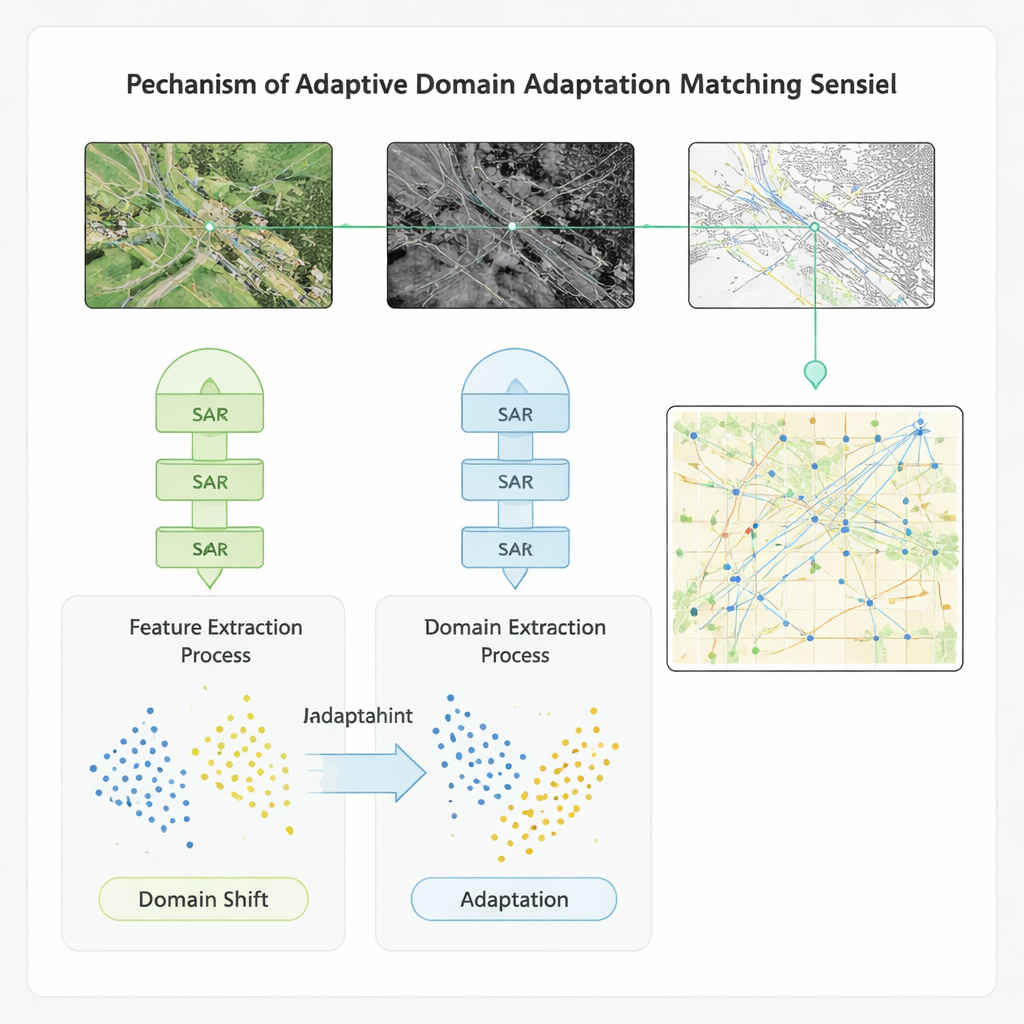
Adaptación entre conjuntos de datos y condiciones
Para garantizar que el método funcione más allá de un único banco de pruebas, los autores integran su esquema de aprendizaje en un modelo de adaptación de dominio. Este componente reduce explícitamente la brecha entre las propiedades estadísticas de las características de distintos sensores y conjuntos de datos, de modo que un modelo entrenado en una región o instrumento pueda aplicarse a otra con mínima pérdida de precisión. Probado en cuatro conjuntos de datos públicos que incluyen imágenes multiespectrales globales, pares radar‑ópticos de alta resolución, escenas de uso del suelo e imágenes de barcos, el nuevo enfoque supera a varias referencias avanzadas. Mejora la precisión, la recuperación y la puntuación F1 en alrededor de 20 puntos porcentuales, acelera el emparejamiento en más de un 20% y aumenta la precisión en la detección de defectos estilo vídeo —importante para monitorizar cambios a lo largo del tiempo— en más de un 40%. El método también muestra mayor resiliencia al ruido y a los desplazamientos entre condiciones de entrenamiento y despliegue.
Qué supone esto para la monitorización en el mundo real
Desde la perspectiva de un público general, el estudio muestra cómo se puede entrenar a los ordenadores para reconocer “esto es el mismo lugar” en imágenes que a simple vista no se parecen en nada. Al aprender en varios niveles de detalle, limpiar el ruido y adaptarse explícitamente a nuevos sensores y regiones, el método HSSCL facilita combinar múltiples corrientes de datos satelitales en una imagen coherente. Esto, a su vez, puede ayudar a los equipos de emergencia a alinear más rápidamente imágenes radar y ópticas después de una tormenta, apoyar a los planificadores en el seguimiento de cómo cambian ciudades o bosques a lo largo de años y mantener el seguimiento continuo de buques en el mar. Si bien los autores señalan que el ruido extremo y las distorsiones muy grandes siguen siendo un desafío, su trabajo ofrece una vía prometedora y práctica hacia un emparejamiento más rápido y fiable de los muchos ojos que tenemos en órbita.
Cita: Li, Y., Luo, Z., Zhu, G. et al. Application of hierarchical self-supervised contrastive learning in domain adaptation matching of multimodal remote sensing image. Sci Rep 16, 6445 (2026). https://doi.org/10.1038/s41598-026-37312-5
Palabras clave: teledetección, imágenes multimodales, aprendizaje auto‑supervisado, aprendizaje contrastivo, adaptación de dominio