Clear Sky Science · es
Evaluación del rendimiento de un transformador generativo preentrenado en el Examen Nacional de Licencias Veterinarias en Japón
Por qué unos exámenes veterinarios más inteligentes importan para todos
Detrás de cada visita al hospital veterinario hay años de formación rigurosa y un examen nacional de alta exigencia. En Japón, los aspirantes a veterinarios deben aprobar el Examen Nacional de Licencias Veterinarias (NVLE), que evalúa desde biología básica hasta juicio clínico complejo. Este estudio planteó una pregunta actual: ¿pueden los modelos avanzados de lenguaje de IA de hoy, los mismos que impulsan chatbots populares, resolver este exigente examen en japonés —y qué implicaría eso para la educación veterinaria y el cuidado animal?
Evaluando la IA en un examen real de licencia veterinaria
Los investigadores se centraron en tres generaciones de modelos de lenguaje a gran escala de OpenAI: GPT‑4o, o1 y o3. Estos sistemas están diseñados para leer y generar texto similar al humano, pero no fueron entrenados específicamente en medicina veterinaria. Para evaluarlos, el equipo utilizó como referencia el 74.º NVLE de Japón (2023). El examen se divide en cinco secciones, incluidas preguntas solo de texto y preguntas basadas en imágenes que muestran radiografías, fotos o diagramas. Todas las preguntas son de opción múltiple con cinco alternativas, igual que el examen real que presentan los estudiantes. Los modelos recibieron cada pregunta mediante un guion informático estandarizado y se les exigió responder únicamente con el número de la opción elegida, sin posibilidad de “explicar” o negociar para obtener crédito.
¿Qué modelo de IA fue el mejor?
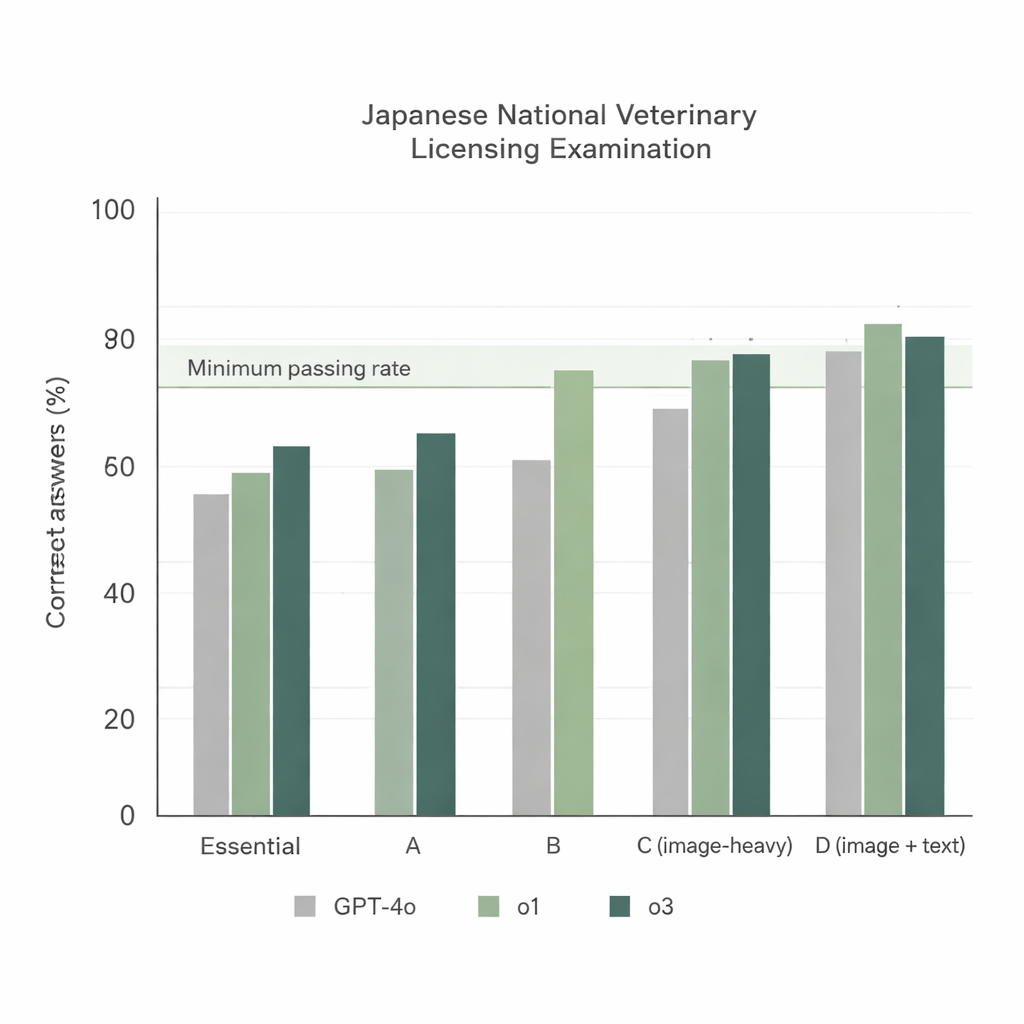
Cuando los tres modelos abordaron el 74.º NVLE usando la configuración más simple —preguntas en japonés y una instrucción directa— surgieron dos tendencias claras. Primero, todos los modelos obtuvieron buenos resultados en las secciones basadas en texto, pero o1 y o3 superaron sistemáticamente a GPT‑4o. Segundo, el rendimiento bajó en las secciones con muchas imágenes, aunque o1 y o3 se mantuvieron por encima de la tasa mínima oficial de aprobación, mientras que GPT‑4o no alcanzó esa marca en una de dichas secciones. En conjunto, GPT‑4o respondió correctamente alrededor del 78% de las preguntas, mientras que o1 alcanzó cerca del 92% y o3 alrededor del 93%. Como o3 superó ligeramente a o1 en la puntuación total, los investigadores eligieron o3 para el resto de los experimentos.
¿Realmente ayudan los prompts o las traducciones?
Se ha escrito mucho sobre la «ingeniería de prompts», es decir, elaborar instrucciones complejas para obtener mejores respuestas de la IA, y sobre traducir preguntas locales al inglés para alinearlas con los datos de entrenamiento de los modelos. El estudio probó directamente estas ideas con el modelo o3, comparando un prompt básico frente a uno más detallado y optimizado, y preguntas en japonés frente a versiones primero traducidas al inglés por el propio modelo. Sorprendentemente, ninguno de estos cambios supuso una diferencia significativa: o3 aprobó con holgura en las seis combinaciones, y el enfoque más simple (texto original en japonés con el prompt básico) funcionó igual de bien que las configuraciones más complicadas. Esto sugiere que, al menos para estas preguntas veterinarias, los modelos más recientes ya comprenden el japonés de forma fiable y no necesitan prompts intrincados para rendir a un nivel alto.
¿Qué tan estable es el rendimiento en exámenes más recientes?
Para comprobar si los buenos resultados eran algo aislado, el equipo sometió a o3 a los NVLE 75.º (2024) y 76.º (2025), nuevamente usando solo las preguntas originales en japonés y el prompt habitual. El modelo logró puntuaciones globales superiores al 92% en ambos exámenes y superó el umbral de aprobación en todas las secciones, incluidas las áreas con muchas imágenes. La mayoría de las preguntas obtuvieron la misma respuesta en tres ejecuciones independientes, lo que muestra que las respuestas de o3 fueron generalmente estables incluso cuando se permitió cierta aleatoriedad. Al examinar detenidamente los errores del modelo, los investigadores encontraron que las equivocaciones se concentraron en dos áreas: conocimientos prácticos veterinarios (como leyes veterinarias japonesas) y medicina clínica, que requieren normas específicas del país y razonamiento en varios pasos más que simples recuerdos de hechos.
Qué significa esto —y qué no
El estudio concluye que los modelos tipo GPT de última generación pueden ahora aprobar el examen de licencia veterinaria de Japón en japonés, sin trucos de traducción ni prompts complejos. Para las facultades y los estudiantes de veterinaria, esto abre la puerta al uso de la IA como compañero de estudio, generador de preguntas o explicador de temas de examen. Para el público, indica que la IA se está convirtiendo en una herramienta potente para organizar y difundir conocimientos veterinarios. Sin embargo, los autores subrayan que estos sistemas no están preparados para reemplazar a los veterinarios ni para tomar decisiones médicas por sí solos. Los modelos aún pueden malinterpretar imágenes, tener dificultades con juicios clínicos sutiles y, a veces, inventar datos. Usados con cuidado, pueden convertirse en asistentes valiosos para la educación veterinaria y el soporte informativo, pero la responsabilidad por la salud animal seguirá estando firmemente en manos humanas.
Cita: Kako, T., Kato, D., Iguchi, T. et al. Performance evaluation of generative pre-trained transformer on the National Veterinary Licensing Examination in Japan. Sci Rep 16, 4306 (2026). https://doi.org/10.1038/s41598-026-37300-9
Palabras clave: exámenes de licencia veterinaria, modelos de lenguaje a gran escala, inteligencia artificial en medicina, rendimiento de GPT, educación veterinaria en Japón