Clear Sky Science · es
Un marco híbrido de selección de variables e interpretabilidad para la predicción del oxígeno disuelto en plantas potabilizadoras
Por qué importa el oxígeno en el agua potable
El oxígeno disuelto —las pequeñas burbujas de gas oxígeno mezcladas en el agua— influye silenciosamente en que nuestra agua potable se mantenga clara, segura y con buen sabor. Un oxígeno insuficiente en el agua cruda puede liberar metales como hierro y manganeso, favorecer microbios perjudiciales y hacer que el tratamiento sea más difícil y costoso. Este estudio muestra cómo el uso inteligente de datos operativos reales y técnicas modernas de aprendizaje automático puede predecir los niveles de oxígeno en una gran planta potabilizadora, ayudando a los operadores a mantener una alta calidad del agua mientras ahorran tiempo, energía y costes de laboratorio.
Dar aire al tratamiento del agua
En muchos embalses y ríos, los niveles de oxígeno suben y bajan con las estaciones, la contaminación y el movimiento del agua. Cuando el agua se estanca o está sobrecargada de nutrientes, el oxígeno puede disminuir, creando condiciones que liberan sustancias indeseadas de los sedimentos y favorecen microbios problemáticos. En las plantas de tratamiento de agua potable, mantener niveles saludables de oxígeno es especialmente importante para los filtros biológicos y para evitar la liberación de metales y otros compuestos difíciles de eliminar. Sin embargo, la mayoría de los estudios previos se han centrado en ríos o plantas de aguas residuales, dejando un vacío de conocimiento para los sistemas de agua potable tratados, donde pasos del proceso como la coagulación, la filtración y la cloración modifican el comportamiento del oxígeno de maneras únicas.
Una década de datos desde el río hasta la llave
Los investigadores se basaron en diez años de registros diarios de una planta de tratamiento a escala real en Ahvaz, Irán, que trata el agua del río Karun para unas 450.000 personas. Emplearon siete propiedades medidas rutinariamente del agua filtrada de entrada —oxígeno disuelto histórico, nitrito, cloruro, conductividad eléctrica, turbidez, pH y temperatura— para predecir el nivel de oxígeno en la cuenca de salida de la planta. Tras revisar cuidadosamente los datos, tratar los valores atípicos y estandarizar las medidas, entrenaron dos modelos de aprendizaje automático basados en árboles muy usados: Random Forest y XGBoost. Estos modelos aprenden patrones construyendo muchos árboles de decisión y combinando sus resultados, lo que les permite capturar relaciones complejas y no lineales sin necesidad de ecuaciones diseñadas a mano. 
Encontrar las señales que más importan
Un reto clave fue decidir cuáles de las siete mediciones de entrada realmente impulsan el comportamiento del oxígeno y cuáles introducen ruido o complejidad innecesaria. En lugar de confiar en un único método de jerarquía, el equipo construyó una canalización de selección “híbrida” que examinó los datos desde varios ángulos. La Información Mutua resaltó las variables más fuertemente vinculadas al oxígeno, la Reducción Media de Impureza capturó qué medidas eran más útiles dentro de los árboles, y la Importancia por Permutación probó cuánto empeoraban las predicciones cuando se barajaban los valores de una variable. Además, el método SHAP explicó, caso por caso, cómo cada característica empujaba la predicción hacia arriba o hacia abajo, ofreciendo tanto una visión global como específica por instancia. A través de las cuatro técnicas, tres entradas destacaron claramente: el nivel de oxígeno del día anterior, la temperatura del agua y la turbidez. Medidas como el pH y el nitrito, aunque científicamente interesantes, aportaron poco a la mejora de las predicciones en esta planta.
Pronósticos precisos con modelos más ligeros
Al centrarse en las entradas más informativas y descartar las menos útiles, los investigadores redujeron la complejidad del modelo hasta en un 70 por ciento manteniendo la precisión casi sin cambios. Tanto Random Forest como XGBoost reprodujeron con alta precisión los niveles de oxígeno medidos en la salida, explicando más del 93 por ciento de la variación y manteniendo errores típicos por debajo de 0,3 miligramos por litro —muy dentro del rango útil para las operaciones diarias. XGBoost rindió algo mejor en conjunto, pero ambos modelos se mostraron robustos incluso cuando el conjunto de entradas se redujo. Esta eficiencia importa en la práctica: menos medidas necesarias implican costes de monitorización más bajos y pronósticos más rápidos y fiables que pueden integrarse en los sistemas de control de la planta. 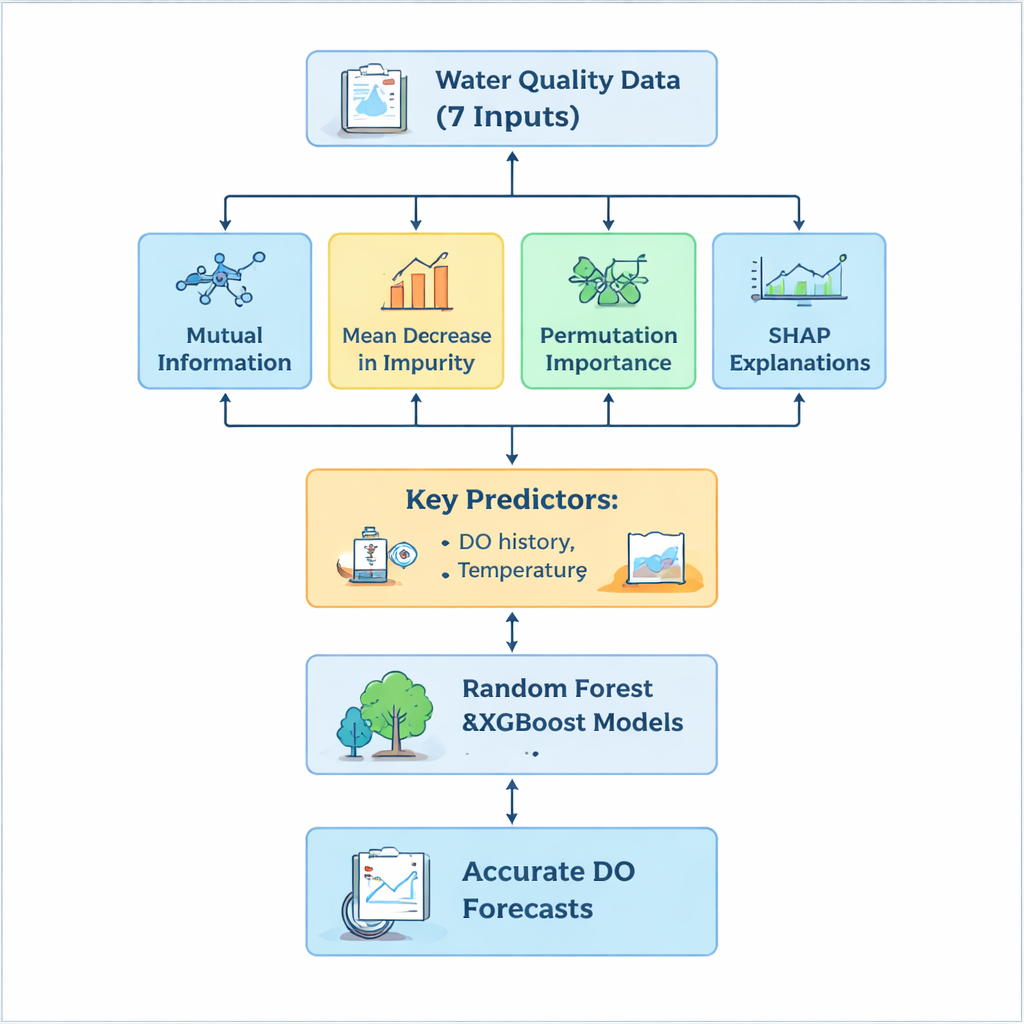
Qué significa esto para un agua potable segura y eficiente
Para no especialistas, la conclusión es sencilla: permitiendo que distintos métodos basados en datos “voten” sobre qué mediciones son más relevantes, los operadores pueden construir herramientas de predicción compactas y transparentes que pronostiquen de forma fiable el oxígeno disuelto en tiempo real. Saber con antelación cuándo el oxígeno podría bajar permite a una planta ajustar la aireación, proteger los filtros y evitar condiciones que liberen metales o favorezcan microbios dañinos —todo ello evitando el uso excesivo de energía y productos químicos. Más allá de esta única planta y este parámetro, el mismo enfoque híbrido podría aplicarse a otras cuestiones ambientales, desde el seguimiento de contaminantes hasta la anticipación de floraciones de algas, ofreciendo una orientación más clara y confiable dondequiera que se crucen la calidad del agua y la salud pública.
Cita: Hoshyarzadeh, R., Hafshejani, L.D., Tishehzan, P. et al. A hybrid framework of feature selection and interpretability for dissolved oxygen prediction in drinking water treatment plants. Sci Rep 16, 6912 (2026). https://doi.org/10.1038/s41598-026-37276-6
Palabras clave: oxígeno disuelto, tratamiento de agua potable, aprendizaje automático, selección de variables, monitorización de la calidad del agua