Clear Sky Science · es
El impacto de la selección de K en la validación cruzada K‑fold sobre sesgo y varianza en modelos de aprendizaje supervisado
Por qué comprobar el modelo dos veces importa realmente
Desde el diagnóstico médico hasta la evaluación crediticia, muchas decisiones dependen hoy de modelos de aprendizaje automático entrenados con datos pasados. Pero, ¿cómo sabemos si un modelo que parece funcionar bien en nuestra pantalla se comportará bien con casos nuevos y no vistos? Una forma popular de «probar» modelos es la validación cruzada k‑fold, en la que los datos se dividen repetidamente en trozos de entrenamiento y de prueba. Este estudio plantea una pregunta aparentemente simple pero crucial: ¿cuántos trozos —qué valor debería tener k— y cómo esa elección influye silenciosamente en la fiabilidad del rendimiento declarado del modelo?
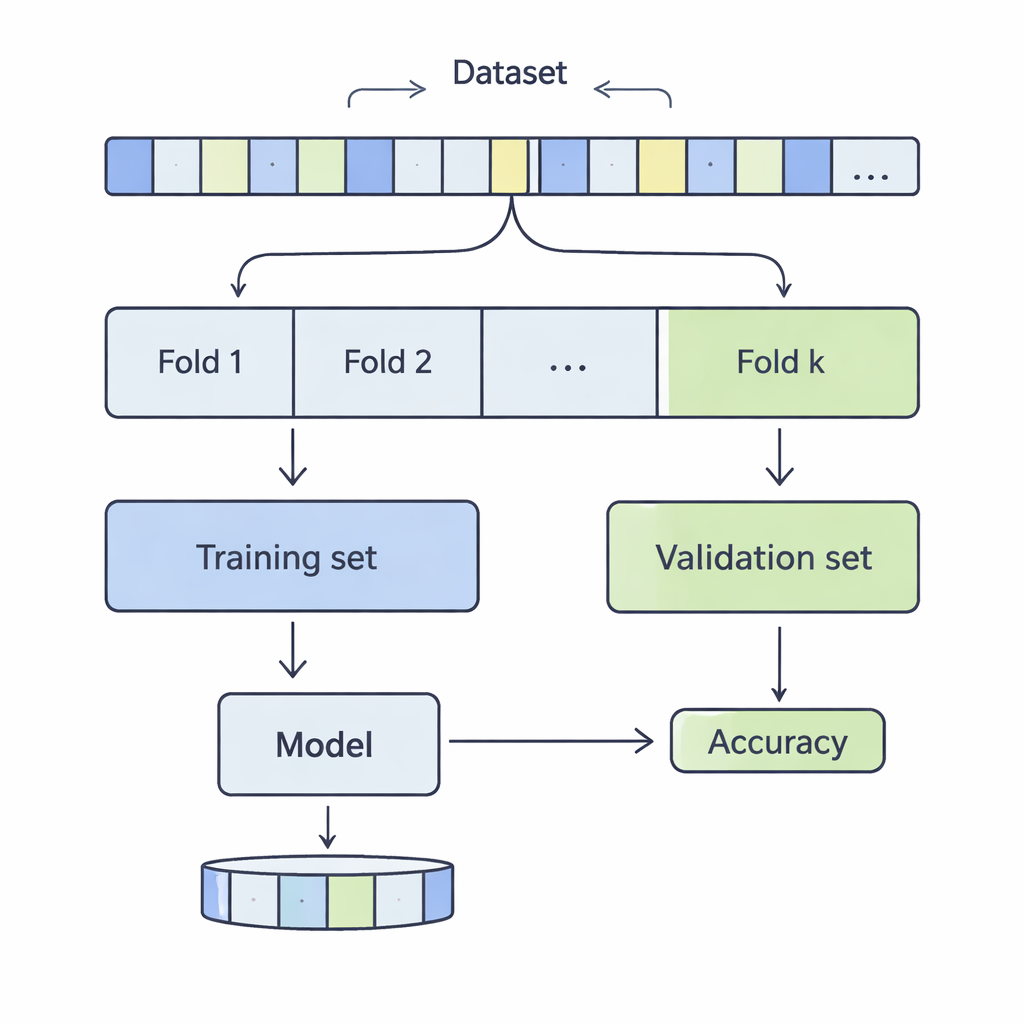
Cómo se cortan los datos para una comprobación de la realidad
En la validación cruzada k‑fold, un conjunto de datos se mezcla y se divide en k partes iguales, o folds. El modelo se entrena con k‑1 de esos folds y se evalúa en el restante; este proceso se repite hasta que cada fold haya ejercido como porción de prueba. Los autores examinaron valores de k de 3 a 20, en 12 conjuntos de datos reales que van desde unos pocos millares hasta más de medio millón de registros, abarcando áreas como predicción de ingresos, resultados médicos, ciberataques, juegos y calidad del vino. Aplicaron cuatro métodos de clasificación comunes —Máquinas de Vectores de Soporte, Árboles de Decisión, Regresión Logística y k‑Vecinos más Cercanos— y midieron con cuidado cómo la elección de k afectaba a dos aspectos clave del rendimiento: sesgo y varianza.
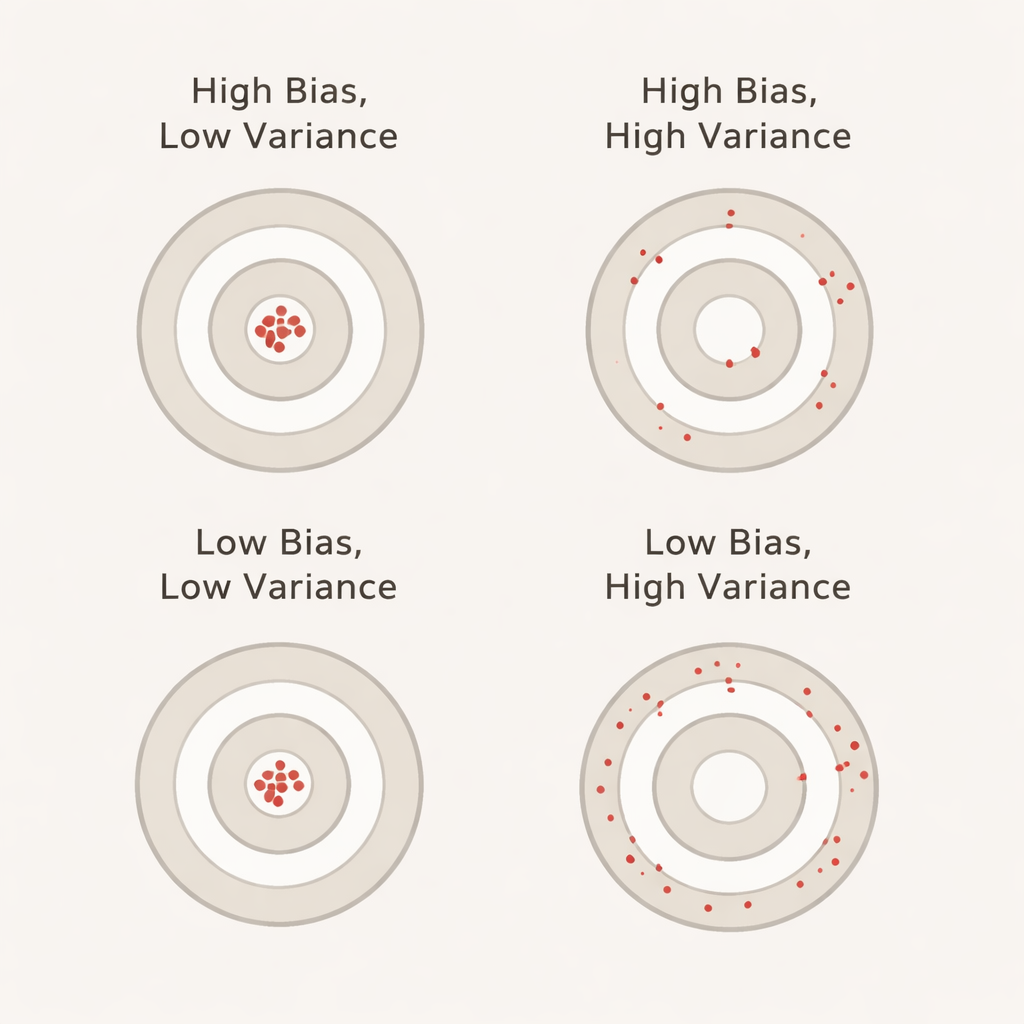
Qué significan sesgo y varianza en términos cotidianos
El sesgo, en este contexto, refleja cuánto mejor parece rendir el modelo durante la validación cruzada respecto a lo que realmente hace en un conjunto de prueba separado e intacto. Un sesgo grande y positivo significa que el modelo parece excesivamente optimista durante la validación —similar a un estudiante que aprueba con nota los ejercicios de práctica pero falla en el examen real. La varianza refleja cuánto varía el rendimiento del modelo entre folds: baja varianza significa que las puntuaciones son estables entre distintos cortes de datos, mientras que alta varianza indica que oscilan. Idealmente queremos que tanto el sesgo como la varianza sean bajos para que la precisión declarada sea a la vez realista y estable.
Qué ocurre al aumentar el número de folds
En los doce conjuntos de datos y con los cuatro algoritmos, surgió un patrón consistente: a medida que k aumentaba, la varianza casi siempre se incrementaba. En otras palabras, usar más folds hacía que la precisión reportada fuera menos estable de un fold a otro. Esto contradice la creencia común de que más folds proporcionan automáticamente estimaciones mejores y más fiables. La razón es que cuando k es grande, cada porción de validación se vuelve muy pequeña y menos representativa, de modo que los resultados se vuelven más sensibles a particularidades de los datos. Al mismo tiempo, el comportamiento del sesgo fue menos uniforme. Para k‑Vecinos más Cercanos y Máquinas de Vectores de Soporte, el sesgo tendió a aumentar con k, lo que significa que estos modelos a menudo parecían más precisos en la validación cruzada de lo que eran en el conjunto de prueba retenido. Los Árboles de Decisión mostraron patrones más equilibrados, y la Regresión Logística quedó en un punto intermedio, con cambios de sesgo mixtos pero más moderados.
Por qué los «ajustes estándar» pueden ser engañosos
La mayoría de las guías prácticas sugieren simplemente usar cinco o diez folds, independientemente del conjunto de datos o del algoritmo de aprendizaje. El análisis de los autores muestra que ese enfoque único puede inducir a error. En algunos conjuntos de datos y para ciertos modelos, valores altos de k amplificaron impresiones excesivamente optimistas del rendimiento; en todos los casos, más folds aumentaron la variabilidad de las estimaciones. Esto resulta especialmente preocupante en ámbitos de alto riesgo como la salud, las finanzas o la infraestructura, donde la confianza equivocada en la precisión de un modelo puede tener consecuencias reales. El estudio sostiene que los efectos de k dependen tanto de la naturaleza de los datos (pequeños frente a grandes, ruidosos frente a más limpios) como de cómo el algoritmo concreto aprende a partir de conjuntos de entrenamiento repetidos y casi idénticos.
Mensaje principal para quien use aprendizaje automático
La lección central es que el número de folds en la validación cruzada no es un detalle técnico inocuo: influye directamente en lo confiables que son tus cifras de precisión. En estos experimentos, más folds hicieron que los resultados fueran sistemáticamente más inestables y, con frecuencia, hicieron que algunos modelos parecieran mejores de lo que realmente eran. En lugar de elegir a ciegas k=5 o k=10, los autores recomiendan tratar k como un mando de ajuste: comprobar cómo cambian los resultados en un pequeño rango de valores de k y, cuando sea posible, mirar más de una métrica de rendimiento. Para practicantes y lectores interesados, el mensaje es claro: al evaluar modelos de aprendizaje automático, cómo cortas los datos puede importar casi tanto como el propio modelo.
Cita: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
Palabras clave: validación cruzada k-fold, compensación sesgo-varianza, evaluación de modelos, validación en aprendizaje automático, clasificación supervisada