Clear Sky Science · es
Sistema de asignación de expertos basado en procesamiento de lenguaje natural para las acciones Marie Skłodowska-Curie
Por qué elegir al experto adecuado importa de verdad
Cuando miles de propuestas de investigación compiten por una financiación limitada, todo depende de quién las evalúa. Si los expertos asignados no comprenden realmente el tema de una propuesta, ideas prometedoras pueden ser malinterpretadas u pasadas por alto. Este artículo explora cómo la inteligencia artificial, y en particular los sistemas modernos de procesamiento del lenguaje, puede ayudar a emparejar las propuestas con los mejores expertos posibles de forma más precisa y justa que las herramientas actuales basadas en palabras clave.
El problema de las listas de verificación por palabras clave
Hasta ahora, la asignación de expertos en programas europeos de financiación importantes, como las becas postdoctorales Marie Skłodowska-Curie, se ha apoyado en gran medida en palabras clave. La plataforma actual escanea las descripciones de las propuestas y los perfiles de los revisores para encontrar términos coincidentes, y luego sugiere tres expertos más alternativas. Pero los Vicepresidentes del panel—científicos sénior que supervisan el proceso—terminan cambiando alrededor del 40% de estas asignaciones. Ese nivel de corrección humana hace que el sistema sea laborioso, lento y algo opaco, especialmente cuando llegan hasta 10.000 propuestas cada año, a menudo en áreas emergentes donde las listas de palabras clave fijas funcionan mal.
Leer la investigación como un humano, a gran escala
Los autores desarrollaron un nuevo sistema de asignación que intenta “leer” la investigación más como lo haría un experto humano. En lugar de fiarse de etiquetas, recopila las publicaciones de cada experto a través de ORCID, un identificador global de investigadores, y construye una base de datos de más de 2.800 resúmenes de artículos. Tanto los resúmenes de las propuestas como los de las publicaciones se procesan con GALACTICA, un modelo de lenguaje grande entrenado específicamente en textos científicos. GALACTICA convierte cada resumen en una huella numérica que captura su significado, no solo su redacción. Al comparar estas huellas, el sistema puede estimar qué tan estrechamente se alinea el contenido de una propuesta con el trabajo previo de cada experto.
Tres maneras de sumar la pericia
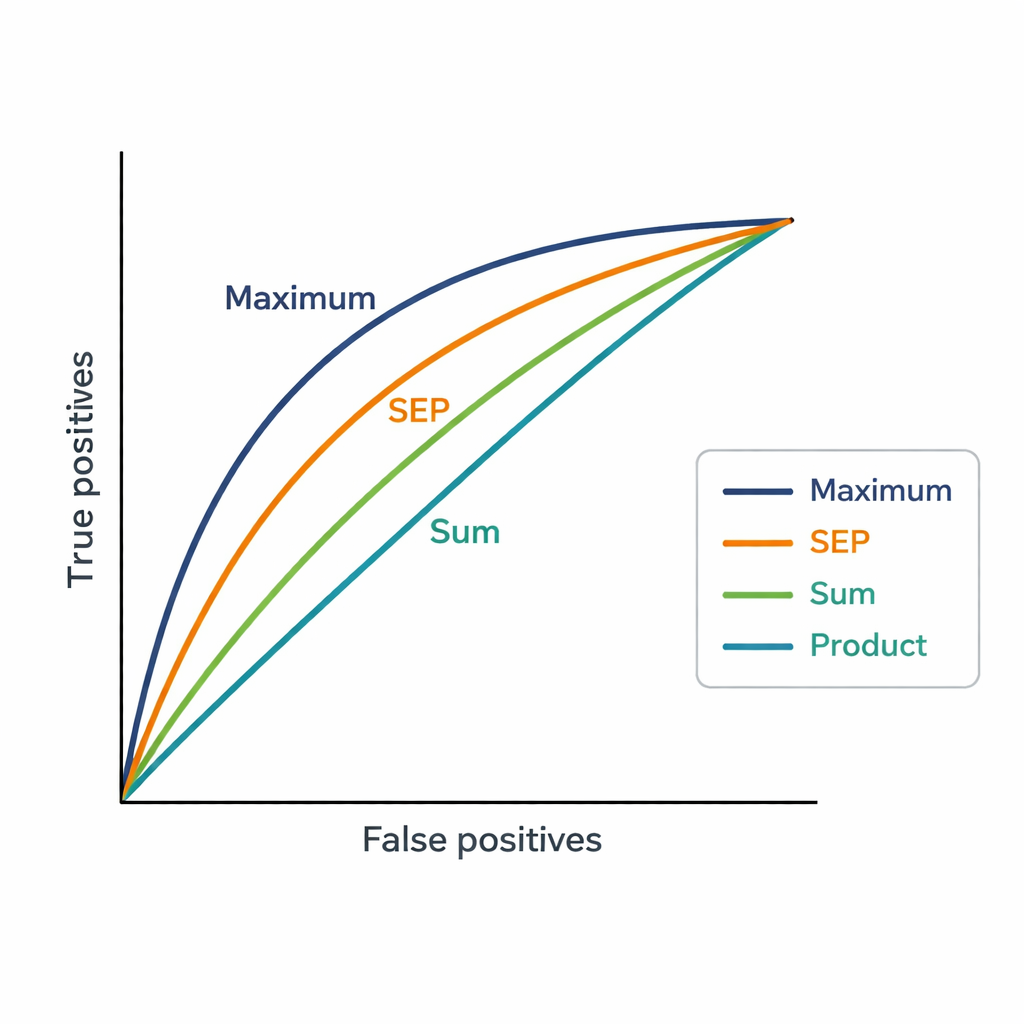
Un desafío es que los expertos pueden tener docenas de publicaciones. El sistema necesita una sola puntuación por experto y propuesta, por lo que los autores probaron tres formas sencillas de combinar las similitudes. La estrategia Suma agrega todas las puntuaciones de similitud, premiando la relevancia amplia y repetida. La estrategia Producto las multiplica, enfatizando la similitud consistente a través de muchas publicaciones pero castigando fuertemente cualquier coincidencia débil. La estrategia Máximo conserva solo la coincidencia más fuerte, partiendo de la premisa de que un artículo muy relacionado puede ser suficiente para justificar una asignación. Estas puntuaciones se usan luego para ordenar 48 expertos candidatos para cada una de 181 propuestas, y las clasificaciones se comparan con las decisiones finales de los Vicepresidentes.
Lo que revelan los números sobre las decisiones humanas
La estrategia Máximo coincidió con las decisiones de los Vicepresidentes de forma más estrecha, alcanzando un AUC de 0,82, mejor que tanto el sistema actual basado en palabras clave (AUC 0,75) como las otras metodologías de agregación. En la práctica, el experto elegido por los Vicepresidentes suele aparecer entre las cuatro primeras sugerencias producidas por Máximo. Esto sugiere que, al asignar revisores, las personas tienden a centrarse en si existe al menos una conexión muy fuerte entre el trabajo previo de un experto y una propuesta, en lugar de exigir que todas las publicaciones del experto se alineen. El nuevo método también genera puntuaciones mucho más detalladas que los groseros niveles de “afinidad” de la plataforma, lo que permite distinguir con mayor claridad entre expertos con clasificaciones cercanas.
Qué significa esto para las futuras evaluaciones de subvenciones
Para un lector no especializado, la conclusión es sencilla: usando IA que entiende el lenguaje científico, las agencias de financiación pueden emparejar mejor las propuestas con los expertos adecuados, reducir las correcciones manuales y hacer el proceso más coherente y transparente. Aunque distintas formas de combinar la evidencia procedente de las publicaciones resaltan distintos aspectos de la pericia, la regla simple del “mejor único emparejamiento” parece reflejar cómo deciden los humanos. A medida que estos sistemas se prueben más ampliamente y con modelos de lenguaje más recientes, podrían convertirse en una parte clave de una evaluación de la investigación más justa y eficiente a nivel mundial.
Cita: Álvarez-García, E., García-Costa, D., De Waele, I. et al. Expert assignment system based on natural language processing for Marie Sklodowska-Curie actions. Sci Rep 16, 6396 (2026). https://doi.org/10.1038/s41598-026-37115-8
Palabras clave: revisión por pares, coincidencia de expertos, financiación de investigación, procesamiento de lenguaje natural, modelos de lenguaje grande