Clear Sky Science · es
Estudio comparativo sobre la predicción de metástasis a distancia postoperatoria en cáncer de pulmón basado en modelos de aprendizaje automático
Por qué importa predecir la diseminación del cáncer
El cáncer de pulmón sigue siendo uno de los más letales, incluso cuando los cirujanos extirpan todos los tumores visibles. Muchos pacientes desarrollan más adelante depósitos de cáncer ocultos que aparecen en el cerebro, los huesos, el hígado u otros órganos. Los médicos querrían saber, poco después de la cirugía, qué pacientes tienen mayor probabilidad de presentar este tipo de diseminación a distancia para poder personalizar las visitas de seguimiento y los tratamientos. Este estudio explora si los programas informáticos modernos, conocidos como modelos de aprendizaje automático, pueden ayudar a prever quiénes están en mayor riesgo utilizando información que los hospitales ya recopilan en la atención rutinaria.
Un examen detallado de muchos pacientes
Los investigadores analizaron los registros de 3.120 personas con cáncer de pulmón en estadio I a III que se sometieron a resección tumoral en un único centro oncológico en China. Todos tuvieron, al menos, dos años de seguimiento. Para cada paciente, el equipo recopiló 52 tipos de información, incluidos edad, sexo, peso corporal, antecedentes de tabaquismo, hallazgos de imagen, detalles de la operación, pruebas de laboratorio y si recibieron tratamientos adicionales como quimioterapia o radioterapia después de la cirugía. Con el tiempo, 596 de estos pacientes desarrollaron metástasis a distancia, mientras que 2.524 no lo hicieron. Esta mezcla en condiciones reales permitió al equipo ver qué características se asociaban con la diseminación futura.
Enseñar a los ordenadores a reconocer patrones de riesgo
En lugar de confiar en una sola fórmula, los científicos compararon nueve métodos distintos de aprendizaje automático, desde árboles de decisión simples hasta técnicas más avanzadas que combinan muchos modelos pequeños. Primero emplearon un filtro matemático para reducir los 52 factores originales a un conjunto más pequeño e informativo. Luego, en rondas repetidas, entrenaron cada modelo con una parte de los datos y lo probaron con pacientes que el modelo no había “visto” antes. Debido a que solo alrededor de uno de cada cinco pacientes desarrolló metástasis, ajustaron el entrenamiento para que el ordenador no limitara sus predicciones a “bajo riesgo” para todos. Evaluaron el rendimiento usando varias medidas, incluida la capacidad de los modelos para separar a pacientes de alto y bajo riesgo y la concordancia entre los riesgos predichos y lo que ocurrió realmente.
Encontrar el modelo más fiable
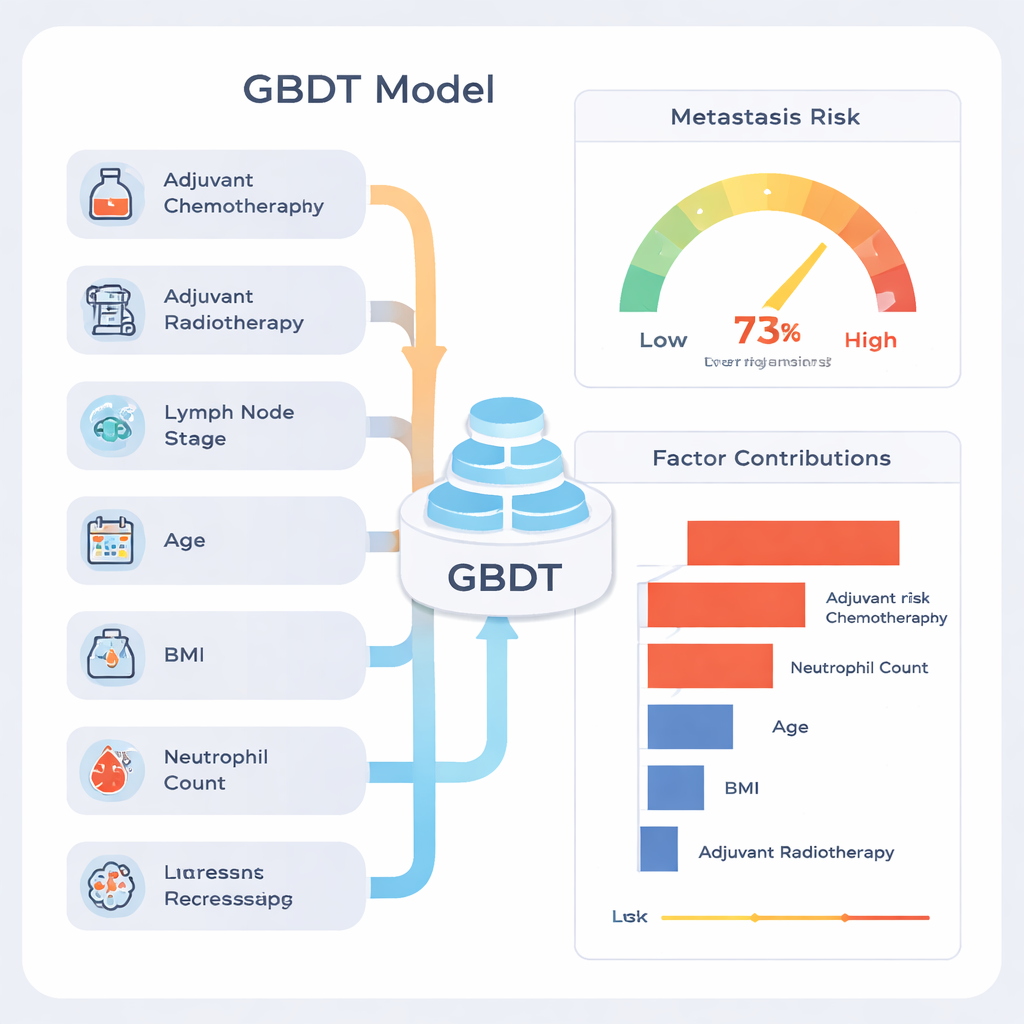
Entre los nueve enfoques, destacó uno llamado Gradient Boosting Decision Tree (GBDT). En los datos de prueba, ordenó correctamente a los pacientes con una precisión global de aproximadamente el 77%, y su puntuación resumen de discriminación (el área bajo la curva ROC) fue 0,81, considerada sólida para herramientas de predicción médicas. El modelo fue especialmente bueno identificando a los pacientes que permanecerían libres de metástasis (alto “valor predictivo negativo”), lo que significa que un resultado de bajo riesgo solía ser tranquilizador. Cuando el equipo examinó cómo se comportaba el modelo a través de muchas divisiones aleatorias de los datos, su rendimiento se mantuvo estable, lo que sugiere que no se limitaba a memorizar particularidades de un subconjunto concreto.
Qué impulsa las decisiones del modelo
Una crítica frecuente al aprendizaje automático es que puede ser una “caja negra”. Para abordarlo, los autores usaron un método explicativo llamado SHAP, que asigna a cada factor una contribución a la estimación final de riesgo para cada paciente. Este análisis mostró que las señales más fuertes eran si el paciente había recibido quimioterapia o radioterapia después de la cirugía, cuántos ganglios linfáticos contenían cáncer, la edad, el índice de masa corporal (IMC) y el recuento preoperatorio de neutrófilos, un tipo de glóbulo blanco. Los pacientes con mayor afectación ganglionar y signos de inflamación sistémica tendían a tener un riesgo predicho más alto. Los autores enfatizan que las altas contribuciones de la quimioterapia y la radioterapia no significan que estos tratamientos causen metástasis; más bien, son marcadores de que los médicos ya habían considerado la enfermedad más agresiva, por lo que esos pacientes partían de un riesgo mayor.
Cómo esto podría ayudar a los pacientes en la práctica
Dado que el modelo usa información que la mayoría de los centros oncológicos ya registran, podría, tras pruebas adicionales, integrarse en el software hospitalario. Para un paciente nuevo que acaba de someterse a cirugía de pulmón, el sistema podría recopilar sus datos y ofrecer una probabilidad personalizada de metástasis a distancia, junto con una explicación sencilla de qué factores elevan o reducen el riesgo. Los clínicos podrían entonces usar esto para decidir quién necesita un seguimiento de imagen más estrecho, asesoramiento adicional o inclusión en ensayos clínicos, y quién podría evitar una vigilancia intensiva de forma segura. El estudio se realizó en un solo hospital, por lo que la herramienta aún necesita comprobarse y ajustarse en otras regiones y sistemas sanitarios. Pero ofrece un esquema prometedor para combinar datos clínicos rutinarios con aprendizaje automático transparente y mejorar la atención a largo plazo de personas con cáncer de pulmón.
Cita: Guo, X., Xu, T., Luo, Y. et al. Comparative study on predicting postoperative distant metastasis of lung cancer based on machine learning models. Sci Rep 16, 6468 (2026). https://doi.org/10.1038/s41598-026-37113-w
Palabras clave: cáncer de pulmón, metástasis a distancia, aprendizaje automático, predicción de riesgo, seguimiento postoperatorio