Clear Sky Science · es
Resumen temporal innovador para clasificación compleja de vídeo
Por qué importan resúmenes de vídeo más inteligentes
Desde cámaras de seguridad hasta plataformas de streaming, el mundo está registrando más vídeo del que humanos o máquinas pueden procesar cómodamente. Cada segundo de metraje contiene decenas de fotogramas, y muchos de ellos son casi idénticos. Este artículo explora una forma de reducir vídeos largos hasta los momentos más significativos, de modo que los ordenadores sigan reconociendo acciones como cocinar, practicar deportes o pasear a un perro, pero empleando mucho menos tiempo, memoria y energía. Estos avances podrían ayudar a llevar análisis de vídeo potentes a dispositivos cotidianos, desde robots domésticos hasta cámaras portátiles.

De fotogramas infinitos a momentos clave
Los sistemas tradicionales de clasificación de vídeo intentan reconocer lo que ocurre en un clip —por ejemplo, cortar verduras o lanzar una canasta— alimentando largas secuencias de fotogramas a modelos profundos y pesados. Estos modelos deben manejar tanto la apariencia (cómo se ven las cosas) como la temporalidad (cómo se mueven en el tiempo). Procesar todos los fotogramas conlleva grandes conjuntos de datos, altas demandas de almacenamiento y cómputo lento y con mucho consumo energético. Los autores sostienen que muchos de esos fotogramas son redundantes: si no cambia nada importante de un fotograma al siguiente, el sistema no gana mucho al analizar ambos. La idea central del artículo es seleccionar un conjunto mucho más pequeño de “fotogramas clave” que aún capture los cambios importantes en la escena.
Medir el cambio entre fotogramas
Para encontrar esos momentos clave, los investigadores diseñan y comparan varias formas de medir cuánto difiere un fotograma de otro. En lugar de confiar únicamente en la clásica distancia euclidiana, que compara todos los píxeles por igual, prueban alternativas más sensibles a cambios estructurales. Su propuesta principal, llamada distancia de “Norma de Filas”, se centra en la mayor diferencia a lo largo de cada fila de píxeles y luego toma la fila más pronunciada como medida del cambio entre dos fotogramas. También exploran distancias basadas en columnas y métodos basados en los valores propios de matrices que resumen cómo se distribuyen las diferencias de píxeles. Todas estas aproximaciones intentan detectar mejor movimientos o cambios de escena significativos, como una mano alcanzando un utensilio o un jugador que salta.
Cómo funciona la canalización de resumen
El proceso de resumen comienza con el primer fotograma del vídeo, que se trata como el fotograma clave inicial. El sistema compara entonces este fotograma clave con cada fotograma posterior usando una de las medidas de distancia. Siempre que la distancia supere un umbral elegido, el fotograma correspondiente se marca como nuevo fotograma clave, indicando que ha ocurrido un cambio visual importante. El procedimiento se repite usando este nuevo fotograma clave como referencia, avanzando a través del vídeo y recopilando una cadena de instantáneas representativas. Ajustando el umbral, el método puede conservar desde tan solo el 20 por ciento hasta el 80 por ciento de los fotogramas originales, equilibrando compacidad y detalle. Estas secuencias resumidas se pasan luego a un clasificador profundo estándar que combina una potente red de imágenes (ResNet-50) con un módulo LSTM sensible al tiempo.
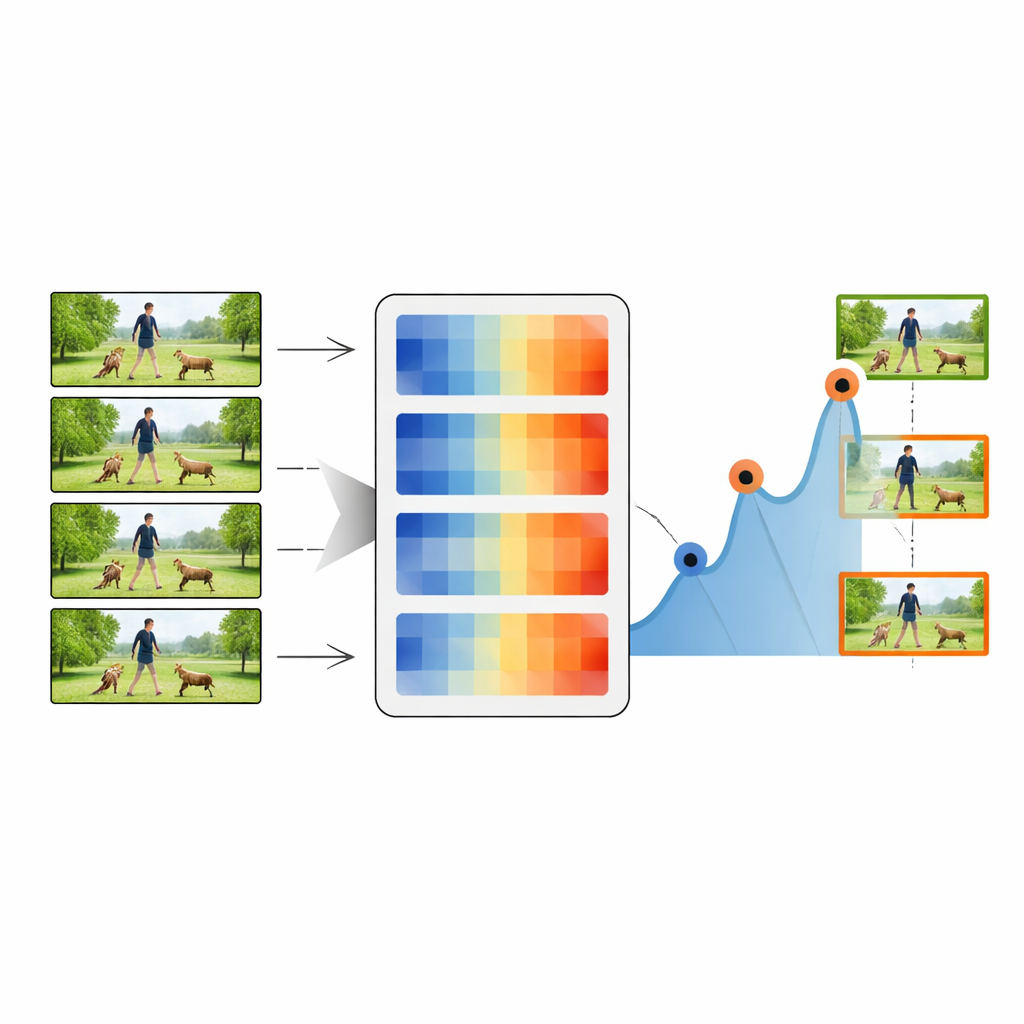
Poniendo el método a prueba
Los autores evalúan rigurosamente su enfoque en cuatro colecciones de vídeo bien conocidas: actividades cotidianas en cocina (MMAC), deportes y acciones generales (UCF101 y UCF11) y clips más variados y desafiantes (HMDB51). En todos estos bancos de pruebas, la distancia Norma de Filas ofrece de manera consistente el mejor equilibrio entre velocidad y precisión. Conservando aproximadamente la mitad de los fotogramas, su sistema alcanza precisiones de clasificación superiores al 90 por ciento en varios conjuntos de datos, con frecuencia igualando o superando métodos más complejos que usan vídeos completos sin resumir. También miden cuánto cubren los resúmenes del contenido original, cuánta redundancia presentan los fotogramas seleccionados y cuán diversa es la representación de los momentos capturados. La métrica propuesta logra alta cobertura con baja redundancia, lo que significa que preserva la narrativa del vídeo sin repetir fotogramas similares.
Decisiones más rápidas para vídeo del mundo real
Al reducir el número de fotogramas aproximadamente a la mitad, el método prácticamente divide por dos el tiempo de procesamiento en hardware informático estándar y aún ofrece incrementos de velocidad notables incluso en tarjetas gráficas modernas. Para sistemas del mundo real que deben reaccionar en tiempo real, como la vigilancia, robots autónomos o aplicaciones móviles, esta reducción de la carga de trabajo es crucial. El estudio demuestra que una medida de distancia cuidadosamente diseñada puede actuar como un portero inteligente, escogiendo qué fotogramas merecen atención y cuáles pueden omitirse con seguridad.
Conclusión para el uso cotidiano
En términos sencillos, este trabajo muestra que los ordenadores no necesitan ver cada fotograma para entender qué ocurre en un vídeo. Al centrarse en los momentos en que la imagen cambia de verdad y descartar casi duplicados, la técnica propuesta conserva la esencia de una acción mientras reduce drásticamente la cantidad de datos. Esto hace que la comprensión de vídeo de alta calidad sea más práctica en hardware limitado y abre la puerta a herramientas más rápidas y eficientes para analizar el creciente flujo de información visual en nuestra vida diaria.
Cita: Khan, A., Rahnama, A., Islam, A. et al. Innovative temporal summarization for complex video classification. Sci Rep 16, 7970 (2026). https://doi.org/10.1038/s41598-026-37111-y
Palabras clave: clasificación de vídeo, resumen de vídeo, selección de fotogramas clave, reconocimiento de acciones, eficiencia en visión por ordenador