Clear Sky Science · es
Construcción y aplicación de un grafo de conocimiento para documentos de normas de calidad de semillas
Por qué las normas de semillas importan para la alimentación de todos
Detrás de cada saco de arroz o paquete de semillas de hortalizas hay un entramado de normas técnicas que protegen discretamente los rendimientos de los cultivos y la seguridad alimentaria. Sin embargo, estas reglas de calidad de semillas suelen estar enterradas en documentos PDF densos que resultan difíciles de buscar o interpretar para agricultores, reguladores y empresas. Este estudio muestra cómo convertir esos documentos estáticos en un “mapa” vivo de hechos conectados —un grafo de conocimiento— puede hacer que las normas agrícolas sean más transparentes, consultables y aptas para la era de la agricultura digital. 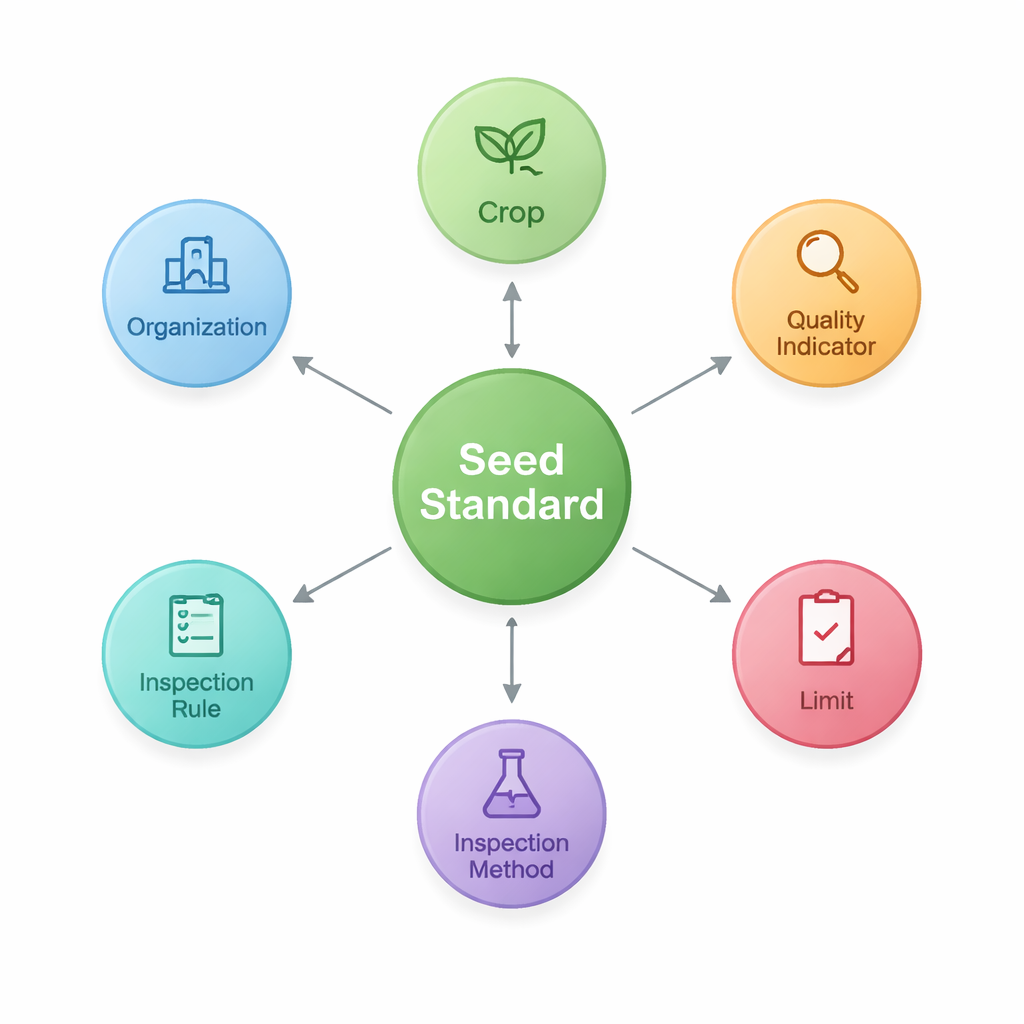
De normas en papel a información inteligente
Las normas de calidad de semillas especifican qué se considera una semilla aceptable: cuán pura debe ser la partida, cuántas semillas deben germinar, cuánto contenido de humedad se permite y los métodos usados para evaluar estos rasgos. En China, el número de estos documentos se ha disparado y muchos aún existen solo como páginas escaneadas o texto no estructurado. La búsqueda por palabras clave tiene dificultades para responder preguntas prácticas como “¿Cuáles son los límites de pureza para este cultivo?” o “¿Qué norma sustituyó a una anterior?”. Los autores sostienen que, para seguir el ritmo de los cambios rápidos en la agricultura, estas normas deben pasar de páginas legibles para humanos a conocimientos comprensibles por máquinas que puedan soportar consultas rápidas, comparaciones y verificaciones automatizadas.
Construyendo un mapa del conocimiento sobre semillas
Para lograrlo, los investigadores primero diseñan una “ontología”: un esquema compartido que define los bloques principales de las normas de semillas y cómo se conectan. Identifican siete tipos centrales de elementos, incluido el propio estándar, el cultivo que cubre, indicadores de calidad como la pureza o la tasa de germinación, los límites numéricos para esos indicadores, los métodos y reglas de inspección y las organizaciones que redactan o publican los documentos. Esta estructura captura patrones como “Cultivo–Indicador de calidad–Límite”, que son especialmente importantes en agricultura. Con este esquema, almacenan los hechos extraídos como nodos y enlaces en una base de datos de grafos (Neo4j), creando una red de 2.436 entidades unidas por 3.011 relaciones.
Combinando reglas y aprendizaje automático
El desafío real consiste en extraer hechos limpios y fiables de documentos fuente desordenados. Las normas de semillas mezclan tablas bien formateadas, metadatos rígidos en la portada y cláusulas largas de texto libre. Ninguna técnica única maneja todo esto bien. Por ello, el equipo desarrolla un sistema de extracción híbrido. Utilizan patrones de reglas precisas (expresiones regulares) para leer tablas estructuradas e información básica del documento, que tienden a seguir formatos estrictos. Para el texto narrativo más complejo —como reglas detalladas de inspección— entrenan una canalización de modelos de lenguaje moderna llamada BERT–BiLSTM–CRF para reconocer nombres clave, códigos y términos técnicos. Este modelo aprende a partir de ejemplos cuidadosamente etiquetados y puede detectar entidades aun cuando aparecen con redacciones variadas y en oraciones largas. 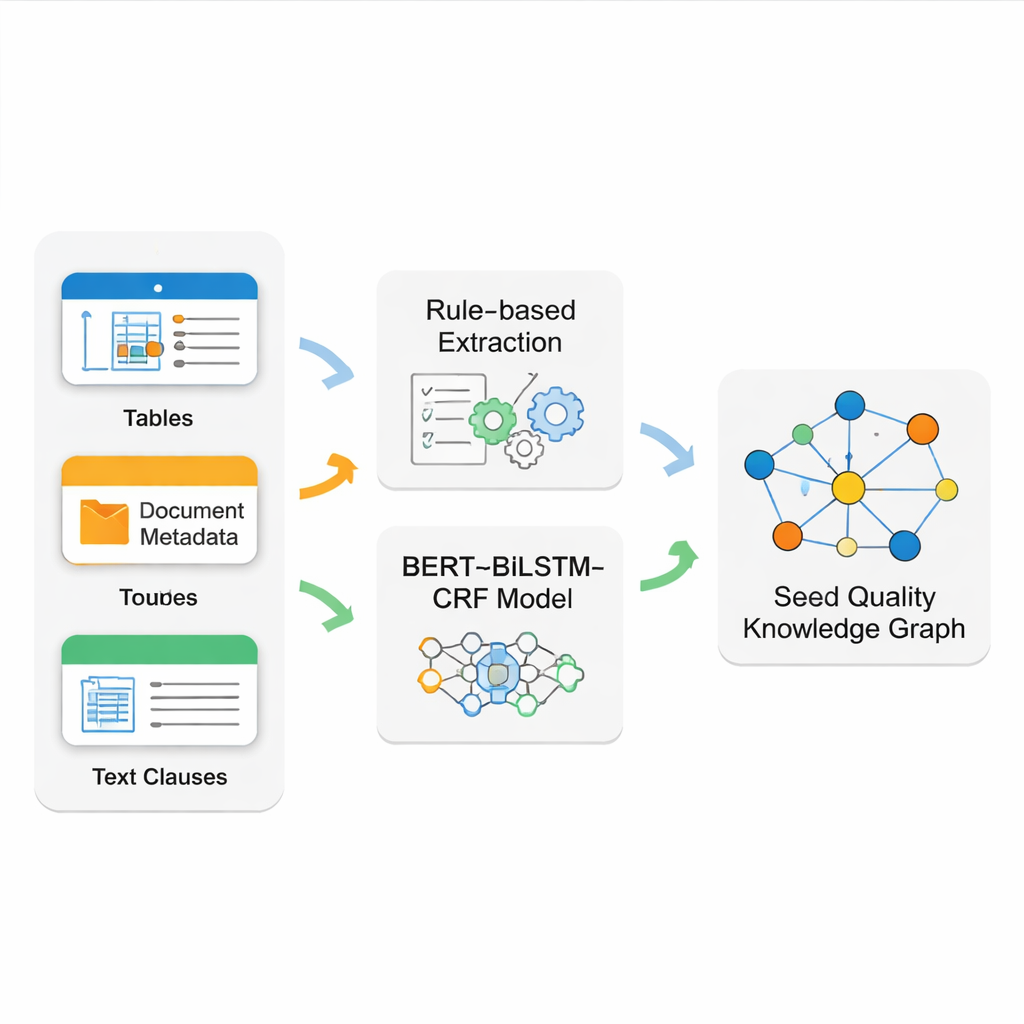
Qué tan bien funciona el sistema en la práctica
En las pruebas, el enfoque híbrido rinde de forma sólida. El modelo de lenguaje alcanza una puntuación F1 global (un equilibrio entre precisión y exhaustividad) de aproximadamente 91,6%, superando a dos modelos de referencia de uso común. Es especialmente eficaz en identificar elementos estructurados como códigos de norma y mantiene buen rendimiento incluso en tareas más difíciles, como reglas de inspección largas. Una vez que toda esa información se carga en el grafo de conocimiento, los usuarios pueden explorar visualmente cómo una norma dada se relaciona con versiones anteriores, qué organizaciones la redactaron, qué cultivos e indicadores cubre y qué métodos de ensayo prescribe. En lugar de hojear largos PDF, reguladores y empresas de semillas pueden ejecutar búsquedas dirigidas y ver resultados conectados en segundos.
Qué significa esto para agricultores y sistemas alimentarios
Para los no especialistas, el resultado es una forma más inteligente de gestionar las normas que mantienen las semillas fiables y los cultivos productivos. El estudio demuestra que, combinando un diseño conceptual claro con extracción basada en reglas y en aprendizaje, es posible convertir normas de semillas dispersas en una base de conocimiento coherente y consultable. Esto sienta las bases técnicas para normas “INTELIGENTES” que las máquinas puedan leer, verificar y actualizar conforme cambian las regulaciones. A largo plazo, dichas herramientas podrían ayudar a agricultores y empresas agropecuarias a comprobar rápidamente si las semillas cumplen los requisitos de calidad vigentes, apoyar a los reguladores en el seguimiento de revisiones y lagunas, y contribuir a cosechas y seguridad alimentaria más estables.
Cita: Yang, Z., He, Q. & Zhang, J. Construction and application of knowledge graph for seed quality standard documents. Sci Rep 16, 5997 (2026). https://doi.org/10.1038/s41598-026-37084-y
Palabras clave: normas de calidad de semillas, grafo de conocimiento, digitalización agrícola, reconocimiento de entidades nombradas, normas inteligentes