Clear Sky Science · es
Modelo de lenguaje grande fundamentado en conocimiento para la generación de planes de entrenamiento deportivo personalizados
Planes de entrenamiento más inteligentes para personas de a pie
La mayoría de las aplicaciones de fitness prometen entrenamiento personalizado, pero muchas siguen basándose en plantillas genéricas que ignoran cómo está funcionando realmente tu cuerpo. Este artículo presenta LLM-SPTRec, un nuevo sistema que emplea el mismo tipo de modelos de lenguaje grande detrás de los chatbots modernos, combinado con conocimiento de ciencias del deporte verificado y datos de wearables, para construir planes de entrenamiento más seguros y efectivos. Para cualquiera que se haya preguntado por qué su app sigue sugiriendo ejercicios inadecuados —o que haya temido si el asesoramiento de salud generado por IA es realmente seguro— este trabajo muestra cómo hacer que el entrenamiento digital sea a la vez más personal y más científico.
Por qué las aplicaciones de fitness tradicionales se quedan cortas
Los motores de recomendación convencionales, como los que sugieren películas o productos, tienen dificultades cuando se aplican al ejercicio. A menudo copian y reutilizan plantillas estándar, tienen problemas para manejar datos limitados de usuarios nuevos y rara vez consideran cómo cambia tu cuerpo de un día a otro. Peor aún, no están diseñados para decisiones con implicaciones de seguridad. Los modelos de lenguaje de propósito general son buenos hablando sobre entrenamientos, pero, al estar entrenados con textos amplios de Internet, pueden “alucinar” consejos arriesgados u omitir días de descanso importantes. Los autores sostienen que, para la planificación del ejercicio—donde una guía inadecuada puede causar lesiones o sobreentrenamiento—la IA debe estar fundamentada en ciencias del deporte verificadas y debe hacer seguimiento de la condición cambiante de la persona a lo largo del tiempo.
Construir un retrato rico del individuo
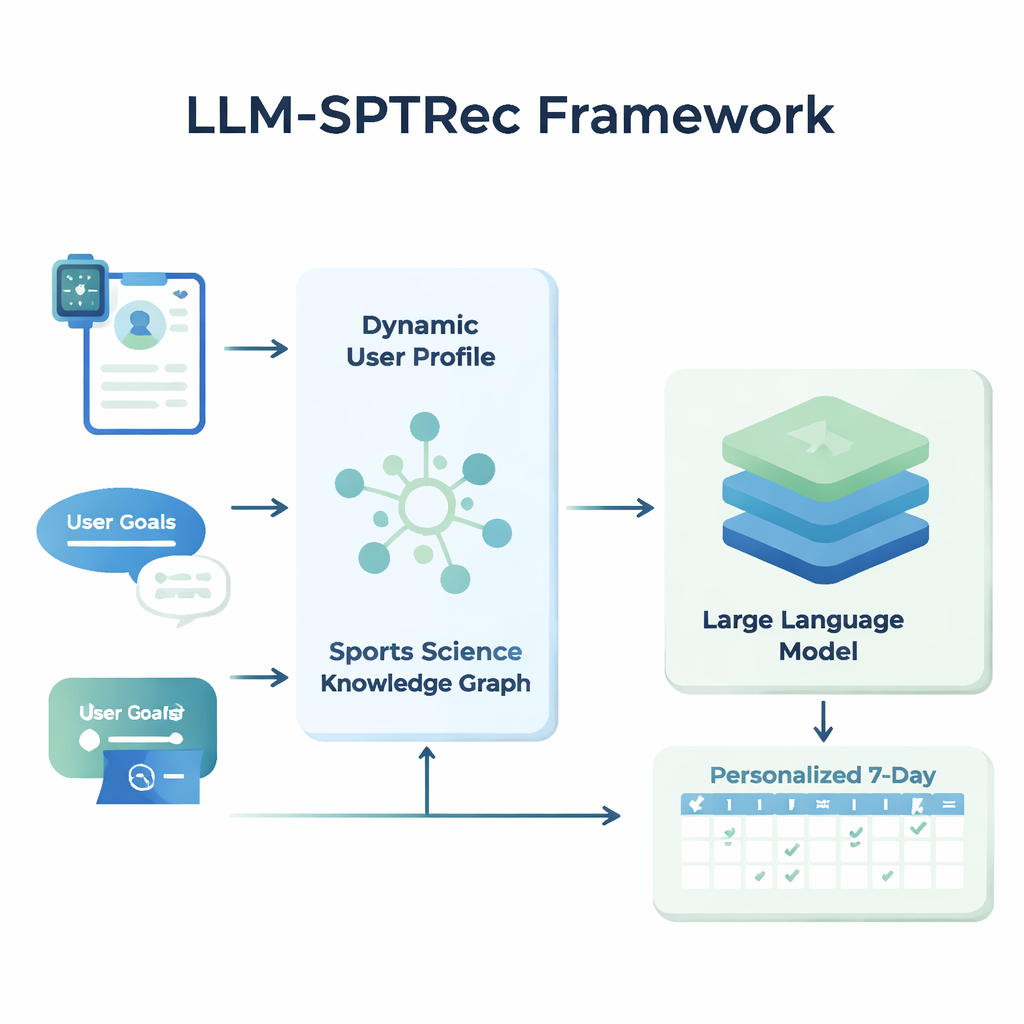
En el núcleo de LLM-SPTRec hay un módulo que crea una instantánea detallada de cada usuario. En lugar de almacenar solo edad, sexo o nivel de experiencia, el sistema fusiona tres tipos de información: rasgos estáticos (como historial de entrenamiento), señales dinámicas (como frecuencia cardíaca, variabilidad de la frecuencia cardíaca, puntuación de sueño y entrenamientos previos de wearables y registros) y objetivos en texto libre escritos por el usuario. Un modelo basado en transformadores—relacionado con la tecnología detrás de los modelos de lenguaje modernos—aprende patrones en estas series temporales, por ejemplo, cómo un entrenamiento intenso de ayer puede afectar la preparación de hoy. Un mecanismo de atención pondera qué señales importan más en un momento dado, combinándolas en una representación numérica única del estado actual del usuario.
Enseñar al IA la ciencia real del deporte
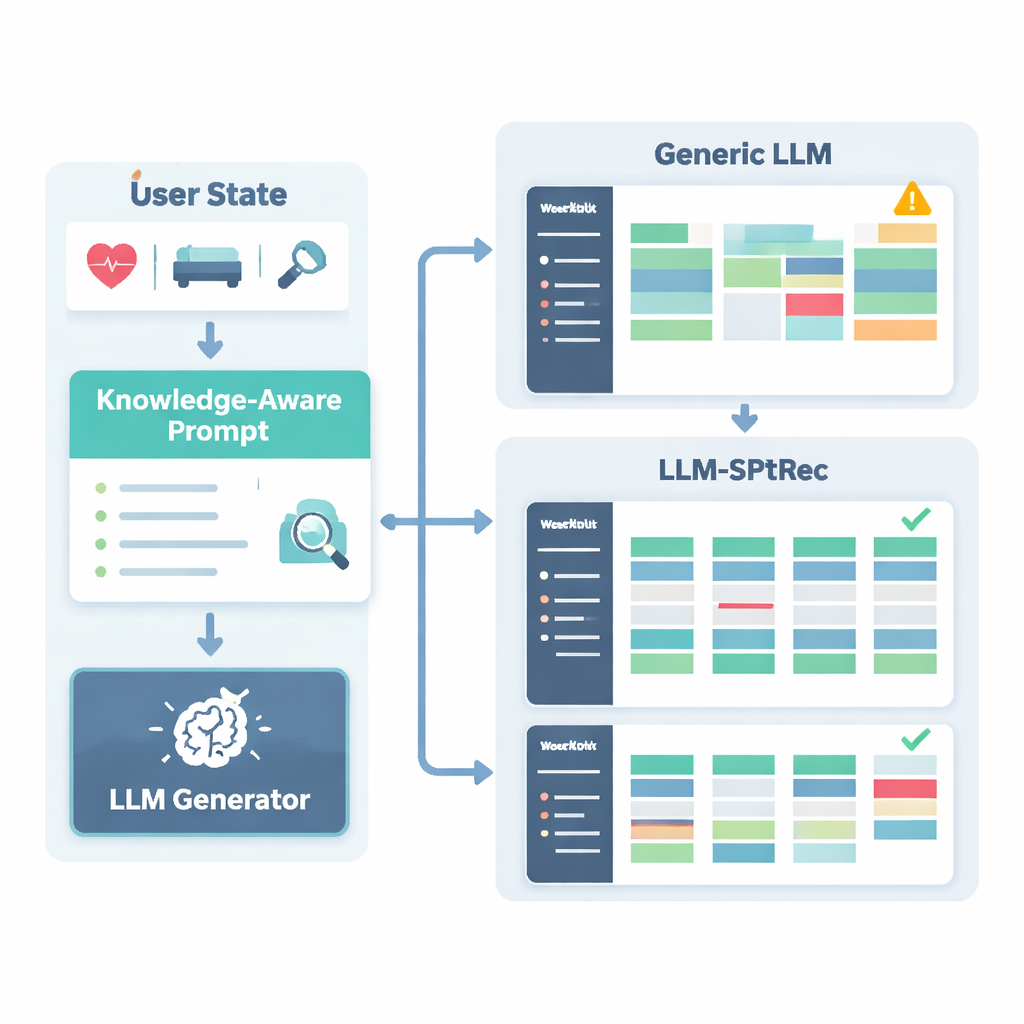
Para evitar recomendaciones inseguras o poco científicas, los investigadores construyeron un Grafo de Conocimiento de Ciencias del Deporte, esencialmente un mapa estructurado de hechos aprobados por expertos. Incluye miles de entradas que vinculan ejercicios con músculos, tipos de movimiento, equipamiento, lesiones comunes y principios de entrenamiento como la sobrecarga progresiva y la especificidad. Para cada usuario, el sistema extrae las partes más relevantes de este grafo—por ejemplo, qué músculos activa el press de banca y qué movimientos son perjudiciales para problemas de hombro—y las convierte en texto legible que se introduce en el modelo de lenguaje junto con el perfil del usuario. Al modelo de lenguaje se le solicita, mediante un prompt cuidadosamente diseñado, que genere un plan de entrenamiento de varios días en un formato estructurado, obedeciendo reglas como rotar grupos musculares entre días y evitar contraindicaciones conocidas.
Mantener los planes estructurados, seguros y en mejora continua
LLM-SPTRec hace más que generar texto. Un módulo de validación verifica cada plan frente a reglas estrictas, como no sobrecargar los mismos músculos primarios en días consecutivos, y señala conflictos con riesgos de lesión almacenados en el grafo de conocimiento. Si un plan no supera estas comprobaciones, el sistema vuelve a solicitar al modelo, indicando explícitamente qué salió mal, hasta que se produce un plan seguro. El entrenamiento del sistema también ocurre en dos etapas. Primero aprende a partir de una gran colección de planes diseñados por expertos. Luego se refina mediante retroalimentación, donde valoraciones simuladas o reales de usuarios premian planes que son coherentes, alineados con los objetivos y satisfactorios de seguir, mientras que penalizan fuertemente sugerencias inseguras. Este bucle de retroalimentación orienta al modelo hacia recomendaciones que funcionan mejor en la práctica.
Qué tan bien funciona el sistema en la práctica
Los autores evaluaron LLM-SPTRec con un gran conjunto de datos del mundo real llamado SportFit-1M, que combina datos anonimizados de apps de fitness y dispositivos wearables, cubriendo decenas de miles de usuarios y millones de registros de entrenamiento y datos fisiológicos. Compararon su sistema con bases sólidas: filtrado colaborativo clásico, un modelo de secuencia que solo mira elecciones pasadas, un recomendador de grafo de conocimiento de última generación y un marco basado en modelos de lenguaje de propósito general. LLM-SPTRec superó a todos no solo en seleccionar ejercicios apropiados, sino —más importante— en producir planes completos que los expertos juzgaron más coherentes y más alineados con los objetivos de los usuarios. Las puntuaciones de satisfacción predichas también fueron mayores, y un pequeño estudio humano con entrenadores certificados valoró su seguridad mucho mejor que la de un modelo de lenguaje general sin fundamentación específica en deporte.
Qué implica esto para el futuro del coaching digital
Para el lector no especializado, la conclusión es que un coaching por IA más inteligente y más seguro es posible cuando confluyen tres ingredientes: datos ricos de tus dispositivos, ciencias del deporte experta codificadas como conocimiento estructurado y potentes modelos de lenguaje cuya creatividad está cuidadosamente guiada y verificada. LLM-SPTRec muestra que tal combinación puede generar planes adaptativos día a día que respetan el estado cambiante de tu cuerpo y tus objetivos personales, a la vez que reducen el riesgo de consejos dañinos o sin sentido. Mirando hacia el futuro, la misma fórmula podría extenderse más allá de los entrenamientos a la nutrición, la rehabilitación de lesiones o incluso el bienestar mental, apuntando a un futuro en el que los asistentes de IA se parezcan menos a chatbots genéricos y más a entrenadores digitales conocedores y conscientes de la seguridad.
Cita: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
Palabras clave: entrenamiento personalizado, IA en ciencia del deporte, recomendación de fitness, datos de wearables, grafo de conocimiento