Clear Sky Science · es
Deriva en la interpretación de la IA explicable bajo ruido en las etiquetas
Por qué las explicaciones de la IA pueden fallar en silencio
Hoy muchas personas confían en la inteligencia artificial no solo para obtener respuestas, sino también para obtener razones: ¿por qué se denegó un préstamo? ¿por qué un sistema marcó a un paciente como de alto riesgo? Este estudio muestra que, incluso cuando la precisión de un modelo de IA parece estable y tranquilizadora, la historia que cuenta sobre por qué tomó una decisión puede derivar de forma dramática si los datos de entrenamiento contienen errores. Ese cambio oculto en las explicaciones —lo que los autores denominan “deriva en la interpretación”— podría engañar a los profesionales que dependen de la IA para justificar decisiones importantes.
Cuando datos limpios se encuentran con etiquetas desordenadas
La mayoría de los sistemas modernos de IA son “cajas negras”, ofrecen predicciones sin razones claras. Para hacer la IA más transparente, muchas aplicaciones recurren a modelos basados en reglas que recuerdan el razonamiento humano de tipo si–entonces: por ejemplo, “si la presión arterial es alta y la edad es mayor de 60, entonces el riesgo es alto.” Estos conjuntos de reglas son especialmente atractivos en ámbitos sensibles como la salud, el derecho y las finanzas, donde los usuarios necesitan inspeccionar y confiar en la lógica. Pero los datos del mundo real rara vez son perfectos. Un problema común es el ruido en las etiquetas: casos en los que la supuesta “respuesta correcta” en los datos de entrenamiento es errónea, como un diagnóstico mal registrado o un resultado del cliente etiquetado incorrectamente. Aunque se sabe que el ruido en las etiquetas perjudica la calidad de la predicción, no se había estudiado de forma sistemática su impacto en la estabilidad de las explicaciones de la IA.
Evaluando cuánto resisten las explicaciones ante el ruido
Los autores evaluaron cuán robustas permanecen las explicaciones basadas en reglas cuando las etiquetas se corrompen gradualmente. Usaron cuatro conjuntos de datos diferentes procedentes de atención sanitaria, banca, enfermedad hepática e incluso teoría de números, todos planteados como tareas de predicción sí–no. Se compararon tres métodos de aprendizaje de reglas: dos algoritmos populares y rápidos (IREP y RIPPER) y un enfoque más intensivo en cómputo llamado Human Knowledge Models (HKM), que procura producir conjuntos de reglas muy simples y parecidos a los humanos. Para cada método, los investigadores entrenaron modelos repetidamente mientras alteraban aleatoriamente una fracción creciente de las etiquetas de entrenamiento —desde datos casi perfectamente limpios hasta casi completo sinsentido. Seguían en paralelo dos aspectos: qué tan bien seguían prediciendo los modelos en un conjunto de prueba limpio y cuánto cambiaban las reglas aprendidas en comparación con las obtenidas con datos sin ruido.
Precisión estable, lógica en flujo
En apariencia, los resultados podrían adormecer la alerta de los usuarios. Para niveles moderados de ruido, especialmente con el método HKM, el rendimiento predictivo parecía relativamente estable cuando se medía con la habitual puntuación F1. Sin embargo, un examen más detallado de los conjuntos de reglas contó otra historia. Usando una medida de similitud que compara colecciones de reglas, los autores encontraron que incluso cantidades moderadas de ruido en las etiquetas erosionaban rápidamente la superposición entre las explicaciones originales y las afectadas por ruido. En otras palabras, el modelo podría seguir acertando en muchos casos, pero por razones cada vez distintas. Los conjuntos de reglas más complejos resultaron especialmente frágiles: a medida que aumentaba el número de condiciones en una regla, pequeños cambios en los datos fracturaban o reemplazaban esas reglas con mayor facilidad, acelerando la pérdida de estabilidad interpretativa.
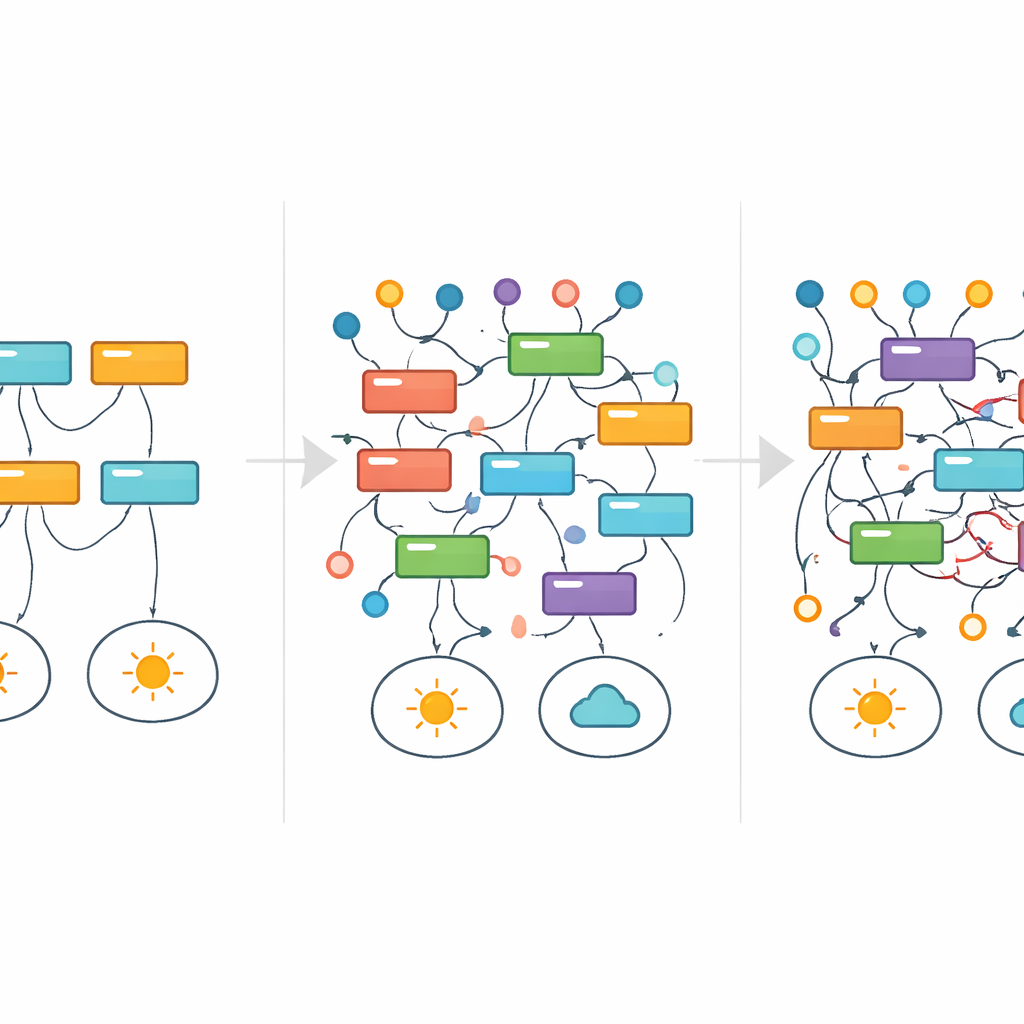
Rastreando reglas que aparecen y desaparecen
Para visualizar cómo las explicaciones individuales sobreviven o fallan a medida que aumenta el ruido, los investigadores tomaron prestada una herramienta de la medicina: el análisis de supervivencia. En lugar de seguir la supervivencia de pacientes en el tiempo, rastrearon cuánto tiempo una regla concreta continuaba apareciendo entre los mejores modelos a medida que subía el ruido en las etiquetas. En vez de desvanecerse suavemente, muchas reglas parpadeaban: una señal de que explicaciones totalmente diferentes podían dominar en distintos niveles de ruido, incluso para la misma tarea subyacente. En un sencillo conjunto de datos sobre divisibilidad de números, por ejemplo, reglas limpias y matemáticamente correctas fueron gradualmente reemplazadas por aproximaciones más amplias y, finalmente, por patrones enrevesados y aparentemente arbitrarios que aún encajaban con las etiquetas corrompidas. A lo largo de gran parte de este proceso, las métricas de rendimiento principales no avisaban claramente de que algo iba mal.
Qué significa esto para las personas que confían en la IA
El mensaje central es que una IA “confiable” no puede juzgarse solo por la precisión. Incluso los modelos que presentan su lógica en reglas legibles por humanos pueden cambiar silenciosamente su razonamiento cuando las etiquetas de las que aprenden son imperfectas —y esa es precisamente la situación en la mayoría de las bases de datos del mundo real. Los autores sostienen que desarrolladores y reguladores deberían tratar la estabilidad de las explicaciones como un requisito de primera clase, junto con la precisión y la equidad. Serán esenciales nuevas métricas que midan directamente cuán consistentes permanecen las explicaciones de un modelo bajo ruido, y herramientas que alerten a los usuarios sobre la deriva en la interpretación, si queremos que los sistemas de IA cuenten historias sobre el mundo tan fiables como sus predicciones.
Cita: Raikovskaia, A., Rakhimzhanov, N. & Pianykh, O.S. Interpretation drift in explainable AI under label noise. Sci Rep 16, 8528 (2026). https://doi.org/10.1038/s41598-026-37070-4
Palabras clave: IA explicable, ruido en las etiquetas, interpretabilidad del modelo, modelos basados en reglas, deriva en la interpretación