Clear Sky Science · es
La evolución de la detección de objetos: de las CNN a los transformers y la fusión multimodal
Enseñar a los ordenadores a ver objetos cotidianos
Cada vez que tu teléfono etiqueta amigos en una foto, un coche detecta a un peatón o la herramienta de un médico resalta un tumor en una exploración, una tecnología discreta y poderosa está en funcionamiento: la detección de objetos. Este artículo de revisión explica cómo la detección de objetos ha evolucionado rápidamente en la última década, desde trucos tempranos de procesamiento de imágenes hasta los sistemas actuales basados en transformers y sensores múltiples, y por qué estos avances importan para calles más seguras, robots más inteligentes y diagnósticos médicos más precisos.
De los píxeles a las cosas reconocibles
La detección de objetos es la tarea de localizar y etiquetar elementos específicos en imágenes o vídeo—coches, ciclistas, animales, estructuras médicas y más. El artículo comienza situando cómo se utiliza ampliamente esta capacidad: en conducción autónoma, vigilancia, imagen médica y robótica. Los sistemas tempranos dependían de reglas diseñadas a mano para identificar formas y texturas, pero los enfoques modernos aprenden directamente de los datos usando aprendizaje profundo. Hoy dominan dos familias amplias: las redes neuronales convolucionales (CNN), muy buenas para detectar patrones locales como bordes y esquinas, y los transformers, que sobresalen en comprender la escena en su conjunto y las relaciones entre objetos distantes. Juntas, definen cómo las máquinas actuales “ven” el mundo.
Cómo funcionan los motores clásicos de visión
Los métodos basados en CNN siguen alimentando muchas aplicaciones en tiempo real. Recorrer imágenes con pequeños filtros permite construir mapas de características cada vez más ricos, que luego se introducen en cabezas de detección que trazan cajas delimitadoras y asignan etiquetas. La revisión explica dos estrategias principales. Los sistemas en dos etapas como Faster R-CNN primero proponen regiones probables de objeto y luego las refinan, con frecuencia alcanzando alta precisión a costa de mayor cómputo. Los sistemas en una etapa como la familia YOLO omiten el paso de propuesta y predicen cajas y etiquetas en una sola pasada, intercambiando algo de precisión por velocidad. Versiones recientes como YOLOv5 y YOLOv8 han sido ampliamente afinadas—añadiendo pirámides de características más inteligentes para objetos pequeños, bloques constructivos ligeros para dispositivos de borde y funciones de pérdida mejoradas—para alcanzar cientos de fotogramas por segundo manteniéndose competitivas en benchmarks exigentes.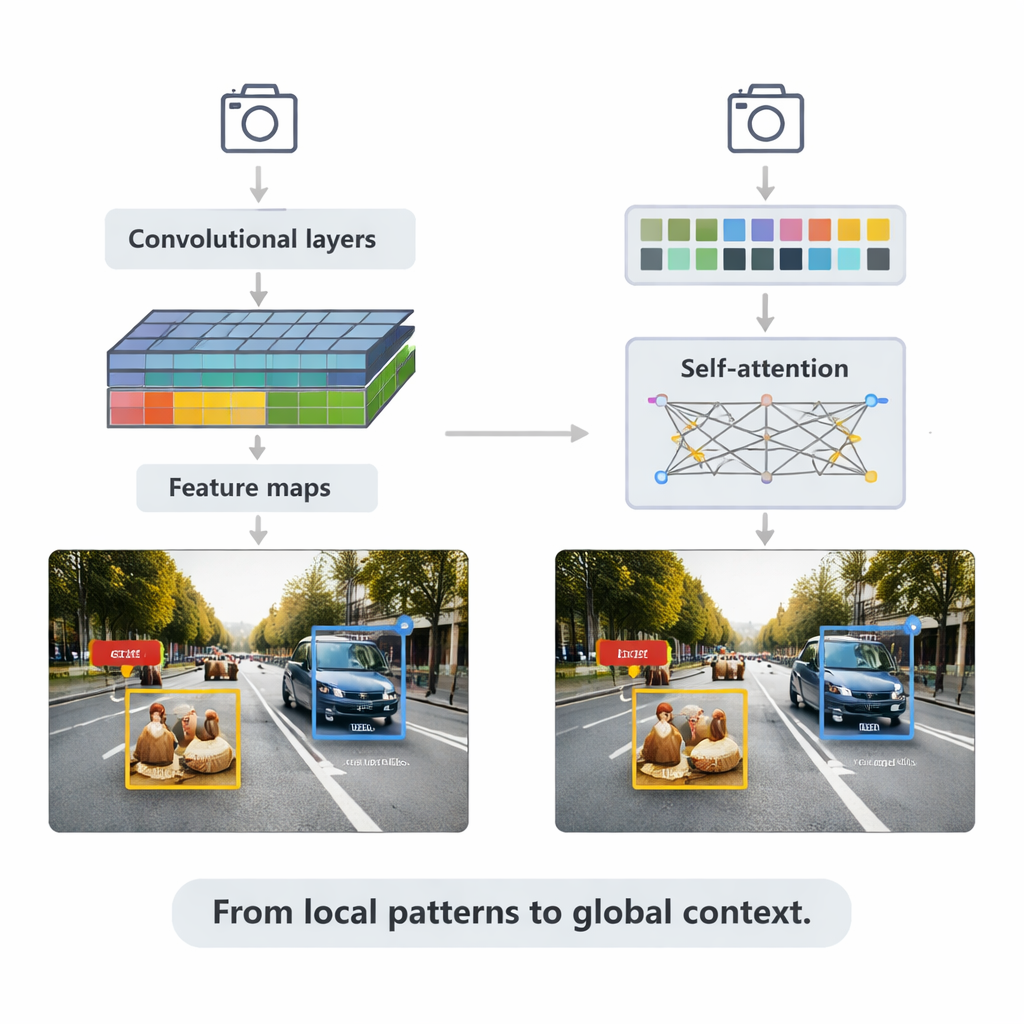
Transformers y el poder del contexto
El artículo se centra después en los transformers, una arquitectura más reciente tomada de los modelos de lenguaje. En lugar de enfocarse solo en vecindarios locales, los transformers usan “auto-atención” para comparar cada parche de una imagen con todos los demás, aprendiendo qué regiones son más relevantes para cada decisión. Detection Transformer (DETR) y sus sucesores eliminan muchas de las trampas diseñadas a mano, buscando canalizaciones más limpias y de extremo a extremo. Variantes como Deformable DETR y RT-DETR reducen el cómputo y mejoran la velocidad de entrenamiento, permitiendo que los transformers funcionen en tiempo real mientras logran algunos de los puntajes de precisión más altos en el benchmark ampliamente usado COCO. Estos modelos brillan especialmente en escenas complejas con objetos superpuestos y fondos confusos, donde el contexto global ayuda a distinguir, por ejemplo, a un peatón parcialmente oculto detrás de un coche.
Mezclando cámaras, láseres y lenguaje
Las condiciones del mundo real—niebla, oscuridad, deslumbramiento, desorden—a menudo derrotan a sistemas de un solo sensor. Un foco importante de la revisión es la fusión multimodal: combinar datos de cámaras convencionales (RGB), sensores de profundidad como LiDAR, cámaras térmicas e incluso descripciones textuales. Los autores presentan una taxonomía clara de cómo puede ocurrir esta mezcla: la fusión temprana combina datos crudos desde el principio, la fusión intermedia integra características aprendidas dentro de la red y la fusión tardía combina las salidas de detectores separados al final. Los “fusion transformers” modernos usan mecanismos de atención para alinear estos flujos, de modo que medidas de distancia precisas de LiDAR, la rica apariencia de imágenes RGB y las pistas semánticas del lenguaje se refuercen mutuamente. Este enfoque mejora la detección en conducción autónoma, imagen médica, comprensión de vídeo y escenas ricas en texto.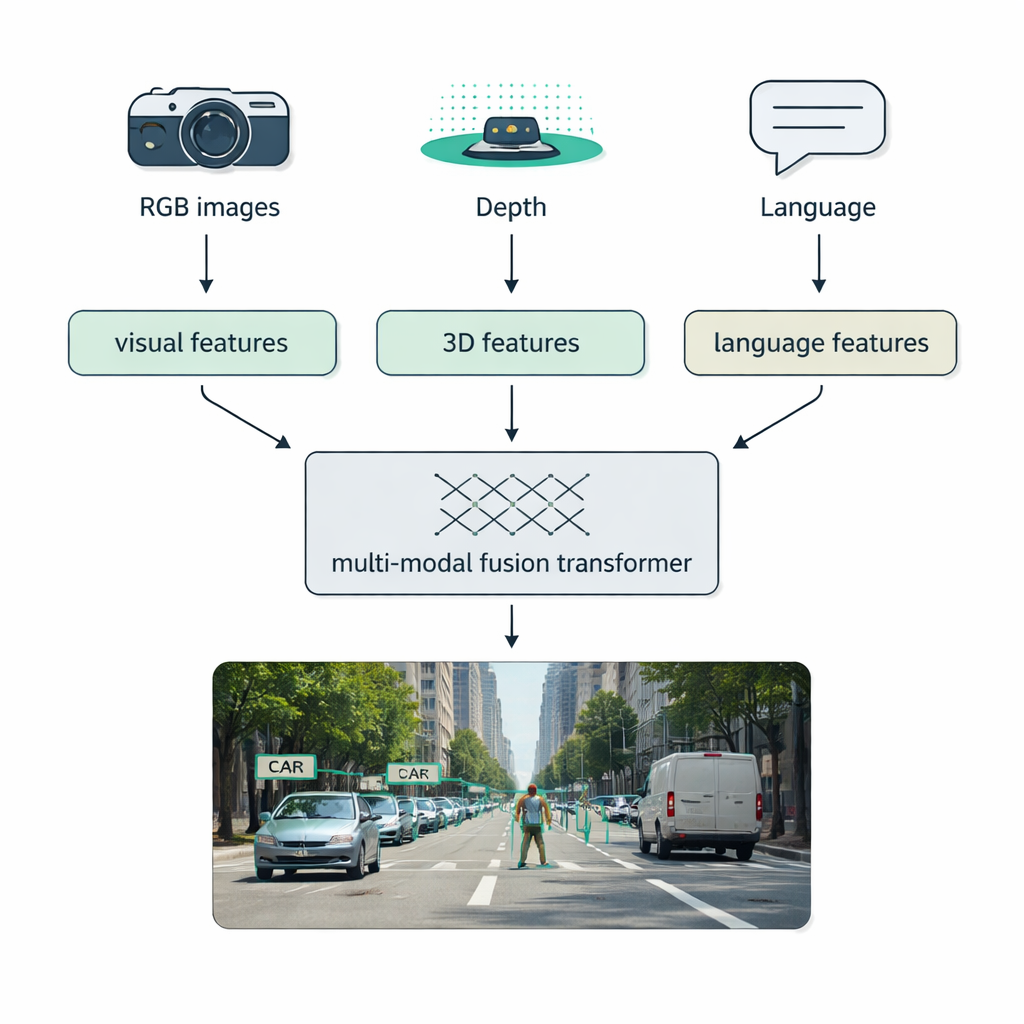
Benchmarks, límites y lo que viene
En pruebas estándar como MS COCO, la revisión compara detectores basados en CNN y transformers tanto por precisión como por velocidad. Las CNN clásicas en dos etapas siguen siendo fuertes pero más lentas, los modelos al estilo YOLO dominan en hardware ligero y los sistemas basados en transformers lideran ahora en precisión cerrando la brecha de velocidad. Métodos especializados en infrarrojo alcanzan puntuaciones muy altas en condiciones de baja visibilidad. Aun así, permanecen problemas difíciles: objetos muy pequeños o extremadamente grandes, occlusión intensa, cambios en el tiempo y la iluminación, y la necesidad de funcionar de forma fiable en dispositivos diminutos. Mirando hacia adelante, los autores destacan tendencias hacia modelos de percepción unificados que manejan detección, segmentación y generación de descripciones conjuntamente, y “modelos fundacionales” que fusionan visión y lenguaje para reconocer objetos descritos en texto llano, incluso si nunca fueron etiquetados en los datos de entrenamiento.
Por qué esto importa en la vida cotidiana
Para quienes no son especialistas, el mensaje clave es que la detección de objetos está pasando de sistemas estrechos y ajustados a mano hacia motores de visión flexibles y de propósito general que pueden adaptarse a nuevas tareas, nuevos entornos y nuevos sensores. Las CNN ofrecen reconocimiento de patrones rápido y eficiente; los transformers aportan una comprensión más global y consciente del contexto; y la fusión multimodal incorpora pistas adicionales de profundidad, temperatura y lenguaje. En conjunto, estos avances prometen coches que anticipen mejor los peligros, herramientas que asistan a los médicos con mayor confianza y dispositivos domésticos que interactúen de forma más segura e inteligente con su entorno—acercando la percepción máquina a la riqueza de la vista humana.
Cita: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
Palabras clave: detección de objetos, visión por computador, aprendizaje profundo, modelos transformer, fusión multimodal