Clear Sky Science · es
Determinación del estado funcional de la movilidad en registros electrónicos de salud mediante grandes modelos de lenguaje
Por qué la capacidad para caminar es una señal de salud poderosa
A medida que las personas viven más tiempo, los médicos prestan más atención no solo a cuánto vivimos, sino a qué tan bien podemos movernos, caminar y cuidarnos. Las dificultades para levantarse de una silla, subir escaleras o desplazarse por la ciudad suelen aparecer mucho antes de una crisis médica. Sin embargo, las descripciones más detalladas de las capacidades diarias de una persona suelen estar enterradas en notas de texto libre de médicos y terapeutas dentro de los registros electrónicos de salud, donde resultan difíciles de encontrar para los ordenadores. Este estudio explora si los modernos grandes modelos de lenguaje —el mismo tipo de IA detrás de muchos chatbots— pueden leer de forma fiable esas notas y convertir descripciones del movimiento en información estructurada y buscable.
Convertir notas desordenadas en datos de movilidad utilizables
Los investigadores se centraron en el “estado funcional de la movilidad”, un término amplio para describir qué tan bien una persona puede cambiar de posición corporal, caminar, transportar y manipular objetos, usar transporte y moverse en la vida cotidiana. Utilizaron 600 notas clínicas reales de tres instituciones sanitarias de Minnesota y Wisconsin, la mayoría procedentes de visitas de fisioterapia y terapia ocupacional, además de un conjunto de notas de consulta más generales. Anotadores expertos revisaron cada nota, sección por sección, y marcaron cada pasaje que describía una de cinco categorías de movilidad, indicando si el paciente estaba claramente limitado (“deteriorado”) o funcionaba con normalidad (“no deteriorado”). Estas etiquetas expertas sirvieron como estándar de referencia para evaluar el sistema de IA.
Cómo se entrenó el modelo de IA para leer como un clínico
El equipo utilizó Llama 3, un gran modelo de lenguaje de código abierto, y lo ejecutó en servidores locales seguros para que los datos de los pacientes nunca salieran del sistema de salud. En lugar de volver a entrenar el modelo desde cero, diseñaron cuidadosamente prompts —conjuntos de instrucciones y definiciones por escrito— para enseñar al modelo qué buscar. Probaron prompts “zero‑shot”, que solo contienen instrucciones, y prompts “few‑shot”, que incluyen también unos pocos ejemplos de notas. Luego analizaron dónde se equivocaba el modelo y elaboraron un prompt “informado por errores” que explicaba qué incluir, qué ignorar (como planes de tratamiento futuros) y cómo manejar casos complejos como caídas, mareos o uso de silla de ruedas. Se pidió a la IA que, para cada sección de nota y cada categoría de movilidad, indicara si se mencionaba la movilidad y, en caso afirmativo, si el paciente estaba deteriorado.
Buen rendimiento que mejora a nivel de paciente
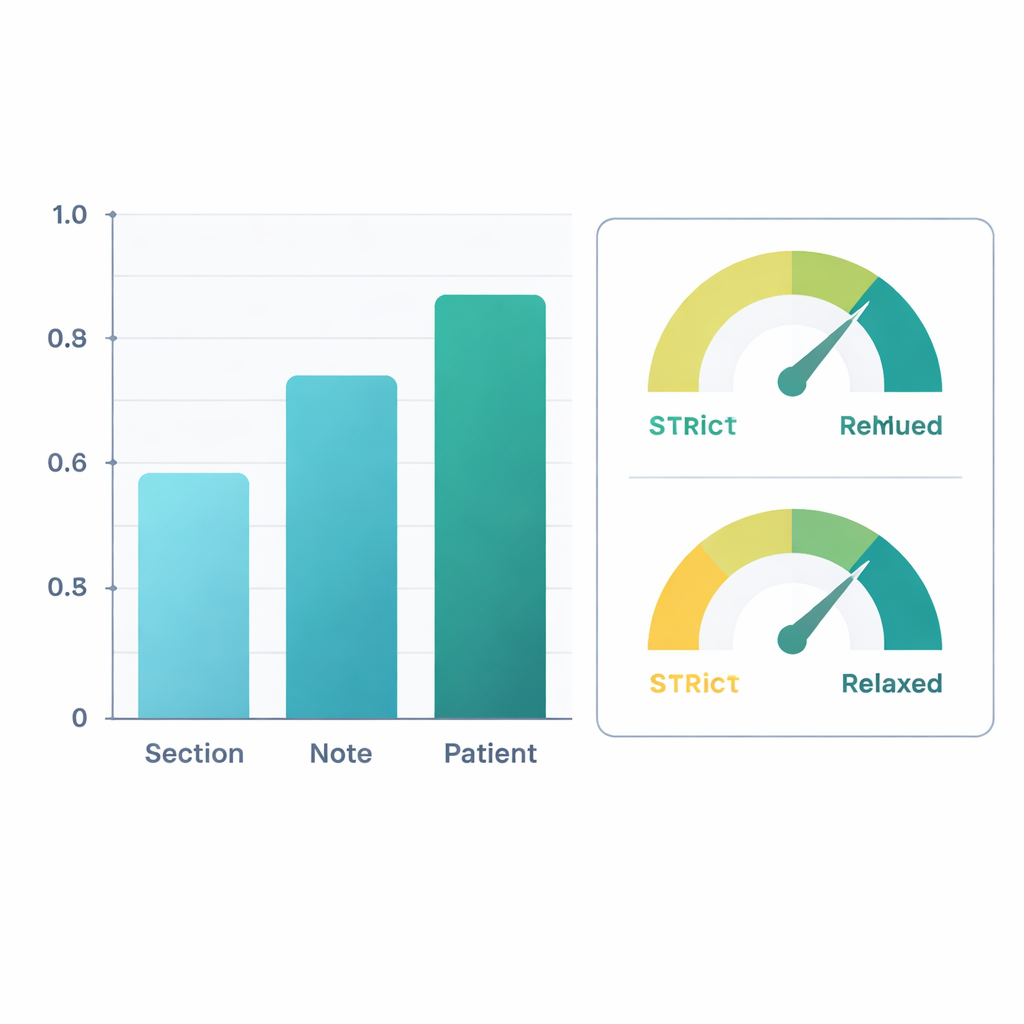
Frente a las etiquetas expertas, el sistema refinado tuvo un buen desempeño. A nivel de pacientes completos —combinando información de todas sus notas— la IA alcanzó una puntuación F1 (una medida común de precisión) de aproximadamente 0,88 para simplemente encontrar información sobre movilidad y 0,90 para decidir si la persona estaba deteriorada. Eso significa que sus juicios coincidían estrechamente con los de los revisores humanos. El rendimiento fue algo menor al examinar secciones individuales de notas, donde la redacción puede ser escasa o ambigua, pero la precisión mejoró al agrupar la información a nivel de notas completas y luego a través de todas las notas de un paciente. En un segundo análisis, los investigadores consideraron correctas las “inferencias clínicamente razonables” —por ejemplo, asumir que un dolor intenso de rodilla al caminar probablemente limita la marcha, aunque no se diga explícitamente—. Bajo esta visión más permisiva, las puntuaciones F1 a nivel de paciente superaron 0,96 para la extracción y 0,95 para la clasificación de deterioro.
Qué se equivocó la IA —y por qué eso sigue importando
La mayoría de los errores procedieron de inferencias del modelo. Con frecuencia deducía problemas de movilidad basándose en dolor, mareos o planes de terapia futuros, incluso cuando la nota no afirmaba claramente que el paciente estuviera limitado. Otros errores reflejaron zonas grises en las definiciones, como si las caídas repetidas deben tratarse como un problema al caminar o como un problema de equilibrio al cambiar de posición. La categoría denominada “movilidad, no especificada”, destinada a capturar actividades cotidianas y ejercicio, fue especialmente difícil de concretar. A pesar de estos problemas, los fallos solían ser razonables desde un punto de vista clínico en lugar de aleatorios o extraños. Al ejecutar el modelo de forma determinista (sin aleatoriedad integrada) en servidores locales cerrados, el equipo también garantizó que los resultados fueran reproducibles y que se preservara la privacidad de los pacientes.
Cómo esto podría cambiar la atención de las personas mayores
Para un público general, la conclusión es que un sistema de IA puede ahora leer notas rutinarias de médicos y terapeutas lo bastante bien como para resumir cómo se mueven los pacientes y dónde tienen dificultades. Esto significa que los sistemas de salud podrían seguir los cambios en la marcha, el equilibrio y las actividades diarias a lo largo del tiempo sin añadir nuevos cuestionarios o pruebas, identificar a personas con alto riesgo de caídas u hospitalizaciones e identificar quiénes podrían beneficiarse de fisioterapia o evaluaciones de seguridad en el hogar. Al convertir millones de notas en texto libre en datos estructurados sobre movilidad, este enfoque ayuda a los médicos a ver una imagen más amplia de cómo el envejecimiento y la enfermedad afectan la vida cotidiana, acercando la atención sanitaria a una medicina verdaderamente personalizada y centrada en la función.
Cita: Liu, X., Garg, M., Jia, H. et al. Mobility functional status ascertainment in electronic health records using large language models. Sci Rep 16, 6045 (2026). https://doi.org/10.1038/s41598-026-37025-9
Palabras clave: movilidad, registros electrónicos de salud, grandes modelos de lenguaje, estado funcional, IA clínica