Clear Sky Science · es
Un criterio de referencia para evaluar la eficiencia del interrogatorio diagnóstico de los LLM en conversaciones con pacientes
Por qué importan las preguntas médicas más inteligentes
Cuando visitas al médico, el primer diagnóstico que oyes rara vez proviene de un único síntoma que mencionas. En su lugar, los médicos hacen una serie de preguntas de seguimiento —sobre el momento, la intensidad, problemas asociados— para reducir gradualmente lo que podría estar ocurriendo. Por potentes que sean los sistemas de IA actuales, la mayoría todavía se evalúa como si hicieran exámenes tipo test, no como si conversaran con personas reales. Este artículo presenta Q4Dx, una nueva forma de juzgar qué tan bien los modelos de lenguaje grandes (LLM) pueden desempeñar al “médico curioso”: elegir las preguntas correctas, en el orden adecuado, para alcanzar el diagnóstico correcto de manera eficiente.
De las preguntas de examen a las conversaciones reales
La mayoría de las pruebas de IA médica existentes ofrecen a los modelos casos limpios y completamente especificados —como un problema de libro de texto— y les piden que elijan un diagnóstico. Eso muestra lo que el sistema “sabe”, pero no cómo se comportaría en una conversación desordenada y real con un paciente que olvida detalles o describe los síntomas en lenguaje cotidiano. Los autores sostienen que esto es una importante zona ciega. En las consultas, la información sale despacio y a menudo de forma imprecisa; la habilidad de un buen clínico reside tanto en lo que pregunta como en lo que ya sabe. Q4Dx está diseñado para cerrar esta brecha al cambiar el foco desde la respuesta estática a preguntas hacia la estrategia de hacer preguntas a lo largo del tiempo.
Construir historias de pacientes realistas
Para crear este nuevo banco de pruebas, los investigadores parten de un recurso médico curado que vincula enfermedades específicas con conjuntos característicos de síntomas. Seleccionan al azar 100 pares enfermedad–síntomas y luego usan un modelo de IA para transformar listas estériles de síntomas en descripciones en primera persona con un tono natural —historias como las que una persona podría contar realmente en una consulta. A partir de cada caso completo generan versiones más cortas en las que solo se mencionan alrededor del 80 % o el 50 % de los síntomas clave. Este “ocultamiento” controlado de la información les permite estudiar cómo se adaptan distintos modelos cuando faltan pistas importantes o solo se insinúan. Verificaciones sobre la superposición de síntomas confirman que las versiones abreviadas realmente contienen menos información utilizable, no solo menos palabras.
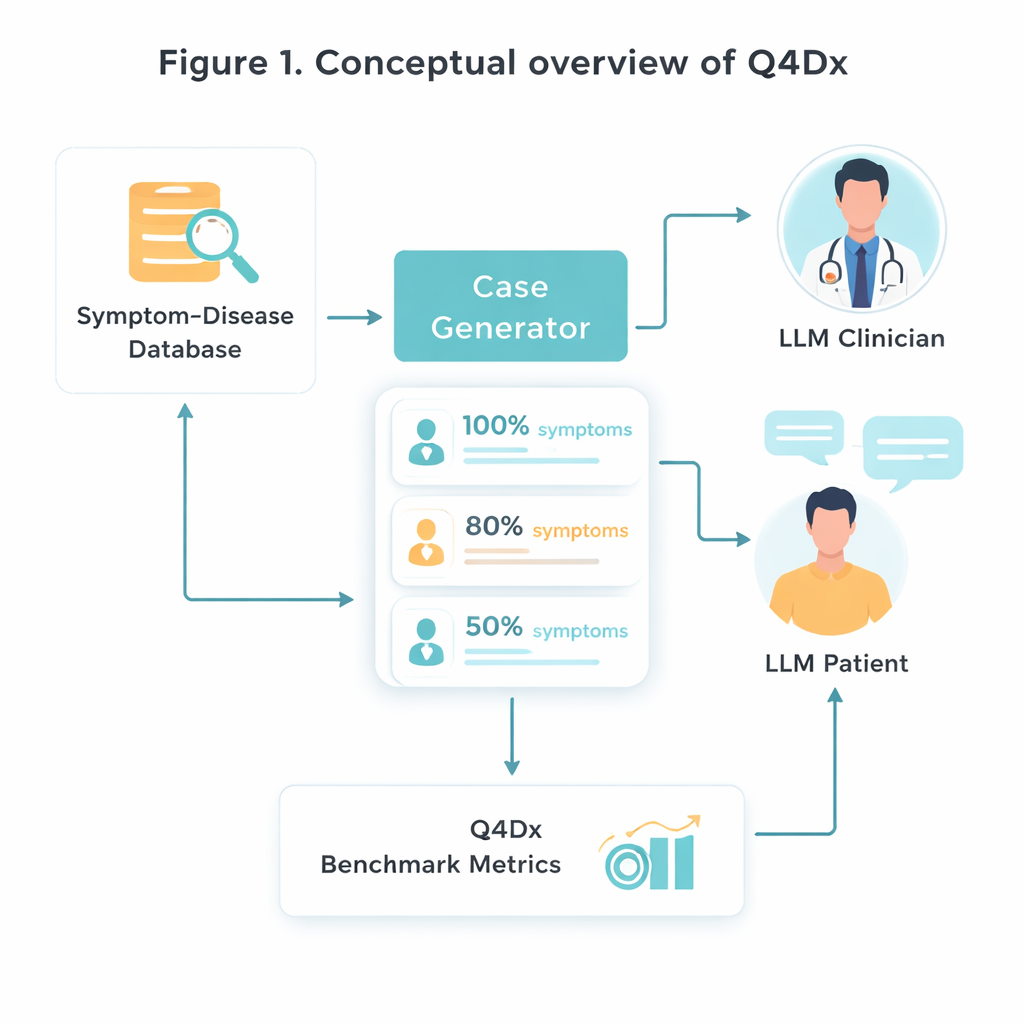
Diálogos simulados médico–paciente
El núcleo de Q4Dx es una gran colección de conversaciones simuladas entre dos agentes de IA. Uno interpreta al paciente, con pleno acceso a la enfermedad subyacente y su conjunto completo de síntomas. El otro actúa como el médico: solo ve una descripción parcial, posiblemente vaga, del caso al inicio y debe decidir qué preguntar a continuación. Tras cada respuesta del paciente, el agente médico emite un diagnóstico provisional, creando una traza paso a paso de cómo evoluciona su razonamiento. Al registrar todas las preguntas, respuestas y conjeturas intermedias, el criterio captura no solo si el modelo acierta, sino cómo llega a ello. Estas secuencias de preguntas generadas por IA se usan como estrategias de referencia —no como verdad médica perfecta, sino como un patrón coherente frente al que comparar modelos futuros e incluso a formandos humanos.
Medir buenas preguntas, no solo respuestas correctas
Para evaluar el rendimiento, los autores diseñan tres medidas simples pero complementarias. Precisión Diagnóstica de Zero‑Shot (ZDA) pregunta: si se le da al modelo el caso completo desde el principio, ¿puede nombrar inmediatamente la enfermedad correcta? Preguntas Medias hasta el Diagnóstico Correcto (MQD) refleja la eficiencia: en promedio, ¿cuántas preguntas al paciente necesita el modelo antes de acertar por primera vez, con un límite de cinco? Finalmente, Eficiencia de la Secuencia de Interrogación (ISE) analiza la calidad del propio camino de preguntas: qué tan similares son, en significado, las preguntas elegidas por el modelo a la secuencia de referencia. Usando estas métricas, el equipo muestra que un modelo sólido de uso general (GPT‑4.1) diagnostica correctamente aproximadamente la mitad de las veces con información completa, pero su precisión cae a medida que se ocultan síntomas. Al mismo tiempo, sus sesiones interactivas suelen tener éxito tras pocas preguntas bien elegidas, y sus preguntas se alinean más con estrategias semejantes a las de expertos a lo largo de turnos sucesivos.

Qué significa esto para la IA médica futura
Para no especialistas, el mensaje de este trabajo es claro: en medicina, hacer preguntas inteligentes es tan importante como tener las respuestas correctas, y la IA debe evaluarse en ambos aspectos. Q4Dx ofrece un marco reutilizable y de acceso público para hacer precisamente eso. Al proporcionar historias de pacientes realistas con cantidades variables de información faltante, trazas detalladas de conversación y medidas claras de precisión y eficiencia, el criterio permite a los investigadores comparar distintos sistemas de IA e incluso enfrentarlos con clínicos humanos en condiciones controladas. Con el tiempo, herramientas como Q4Dx podrían ayudar a entrenar asistentes clínicos más seguros y fiables y mejorar cómo los médicos y estudiantes aprenden la entrevista diagnóstica —en última instancia, respaldando una mejor atención para pacientes reales.
Cita: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
Palabras clave: IA médica, razonamiento diagnóstico, diálogo clínico, modelos de lenguaje extensos, estrategia de preguntas