Clear Sky Science · es
Modelos de aprendizaje automático para la predicción de proteína bruta en pasturas de pasto Tamani
Por qué las pasturas inteligentes importan para tu plato
La carne de vacuno y la leche nacen del pasto. En todo el mundo, miles de millones de hectáreas de pasturas alimentan vacas, ovejas y otros animales de pastoreo. Para que estos animales crezcan bien y se mantengan sanos, su pasto debe contener suficiente proteína, un bloque constructivo clave de músculos, leche y órganos vitales. Pero medir la proteína en el pasto suele implicar cortar muestras y enviarlas a un laboratorio: un trabajo lento y costoso que la mayoría de los agricultores no puede hacer con frecuencia. Este estudio explora cómo mediciones sencillas en campo, combinadas con técnicas informáticas modernas, pueden estimar la proteína del pasto de forma rápida y económica, ayudando a los ganaderos a afinar el pastoreo y la fertilización mientras usan menos recursos.
Una mirada más cercana a un pasto tropical clave
Los investigadores se centraron en el pasto Tamani, un pasto tropical productivo ampliamente utilizado en Brasil para pastoreo intensivo. Durante 18 meses controlaron una pastura de 0,96 hectáreas dividida en pequeños potreros y la sometieron a dos niveles de fertilización con nitrógeno y a dos estrategias de pastoreo basadas en la luz interceptada por las plantas. Registraron información fácil de obtener: estaciones del año, temperatura, precipitación, radiación solar, el tiempo de descanso de cada potrero entre pastoreos y la altura del pasto antes y después del paso de los animales. Al mismo tiempo, tomaron un número limitado de muestras de hojas y emplearon un método óptico especializado para medir la proteína bruta, construyendo un conjunto de datos pequeño pero detallado que vinculó la gestión diaria con la calidad del pasto. 
Enseñar a las computadoras a leer la pastura
En lugar de apoyarse en imágenes satelitales o drones, que requieren equipo especial y potencia de cálculo, el equipo usó solo datos “tabulares”, del tipo que verías en una hoja de cálculo. Probaron cinco enfoques diferentes de aprendizaje automático, que son métodos informáticos que aprenden patrones a partir de ejemplos: un modelo lineal estándar, un árbol de decisión básico, un modelo tipo red neuronal y dos métodos populares basados en árboles que combinan muchos modelos simples en uno más potente. Entrenaron estos modelos con el 80 % de las mediciones y reservaron el 20 % restante para las pruebas. El objetivo era simple pero práctico: dados los datos que un agricultor puede registrar con facilidad —tasa de fertilizante, período de descanso, altura del pasto y clima básico—, ¿podría un sistema predecir cuánta proteína hay en las hojas?
Cómo las decisiones de manejo moldean los niveles de proteína
Los modelos mostraron que la manera de gestionar las pasturas influye más en el contenido de proteína que las condiciones meteorológicas registradas en este estudio. Entre todos los factores, el tiempo entre pastoreos fue el más determinante: períodos de descanso más largos dieron lugar a plantas más viejas y fibrosas con menor proteína, mientras que intervalos más cortos ayudaron a mantener pasto más joven y con más hojas, más rico en proteína. El fertilizante nitrogenado también desempeñó un papel importante, porque el nitrógeno es un componente central de las proteínas vegetales y de la clorofila. La altura del pasto antes y después del pastoreo ocupó la siguiente posición en importancia, vinculando los niveles de proteína con qué tan intensamente se deja pastar a los animales. La precipitación, la temperatura, la radiación y las etiquetas estacionales aún tuvieron algún efecto, pero fueron menos influyentes que estas decisiones cotidianas de manejo. 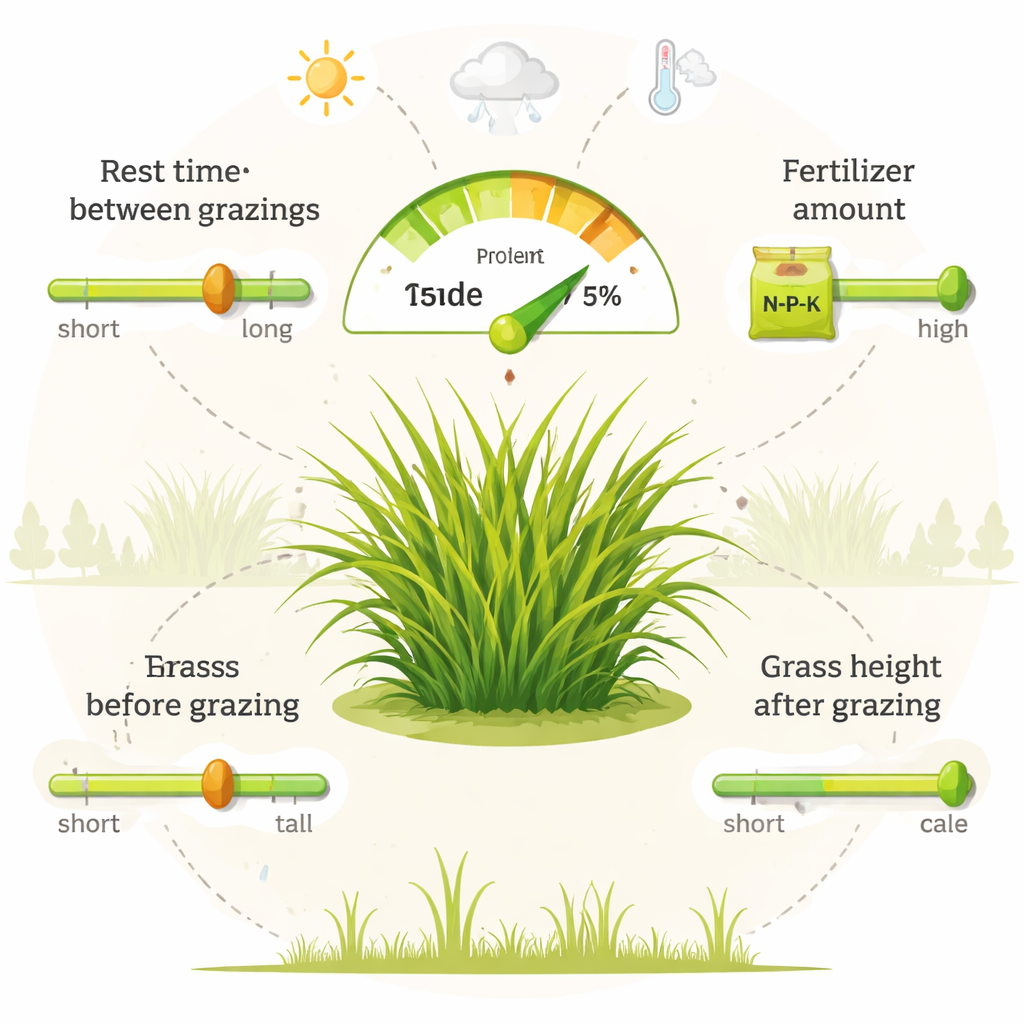
¿Qué tan precisas fueron las predicciones computacionales?
Los métodos con mejor rendimiento fueron dos modelos avanzados basados en árboles. Uno llamado Random Forest y otro conocido como XGBoost produjeron correlaciones similares entre los valores de proteína predichos y observados, lo que significa que sus estimaciones tendían a subir y bajar en consonancia con la realidad. XGBoost rindió algo mejor en conjunto, explicando un poco más de la mitad de la variación en el contenido de proteína y manteniendo errores medios de predicción alrededor de uno y medio puntos porcentuales. Aunque no es perfecto, es lo bastante preciso para ser útil en muchas decisiones de manejo, sobre todo considerando que se basa solo en información que la mayoría de las explotaciones ya puede registrar con herramientas básicas y un cuaderno o una aplicación simple.
Qué significa esto para los agricultores y los consumidores
Para un lector no especializado, el mensaje es claro: prestando atención a cuánto descansan las pasturas, a la altura del pasto cuando los animales entran y salen, y a la cantidad de fertilizante nitrogenado aplicada, los agricultores pueden dirigir el contenido de proteína del pasto en la dirección deseada. Este estudio demuestra que mediciones asequibles y fáciles de recopilar, combinadas con algoritmos inteligentes, pueden ofrecer estimaciones rápidas de la proteína del pasto sin trabajo de laboratorio constante ni equipos de detección caros. Si investigaciones futuras con conjuntos de datos más grandes y variados confirman estos resultados, tales herramientas podrían ayudar a producir más carne y leche con menos insumos, costes menores y mejores resultados ambientales —beneficios que, en última instancia, llegan a los consumidores mediante una producción ganadera más eficiente y sostenible.
Cita: Oliveira de Aquino Monteiro, G., dos Santos Difante, G., Baptaglin Montagner, D. et al. Machine learning models for crude protein prediction in Tamani grass pastures. Sci Rep 16, 5805 (2026). https://doi.org/10.1038/s41598-026-36949-6
Palabras clave: gestión de pasturas, calidad del forraje, aprendizaje automático, proteína bruta, ganadería de precisión