Clear Sky Science · es
MQADet: un paradigma plug-and-play para mejorar la detección de objetos de vocabulario abierto mediante respuesta multimodal a preguntas
Por qué importan los buscadores de objetos más inteligentes
Los teléfonos, los coches, los robots domésticos y los motores de búsqueda confían cada vez más en software capaz de localizar objetos en imágenes: un niño cruzando la calle, tus llaves perdidas sobre una mesa o un producto concreto en un estante. Pero la mayoría de los sistemas actuales solo entienden etiquetas cortas y sencillas como «perro» o «coche». Cuando pides «el perrito pequeño con un collar rojo tumbado detrás del cojín del sofá», a menudo se confunden. Este artículo presenta MQADet, una forma de actualizar los sistemas existentes de búsqueda de objetos para que comprendan descripciones ricas y detalladas sin volver a entrenar los modelos subyacentes.
De listas fijas a comprensión abierta
Los detectores tradicionales se entrenan con listas fijas de categorías, como los 80 objetos cotidianos del popular conjunto de datos COCO. Funcionan bien siempre que el objeto pertenezca a una de esas categorías y la petición sea breve y clara. Sin embargo, el mundo real es desordenado. La gente se refiere a las cosas con frases largas, atributos sutiles y relaciones como «el hombre con chaleco amarillo que está detrás del camión». Los detectores «de vocabulario abierto» más recientes intentan liberarse de listas fijas conectando imágenes con texto, pero todavía les cuesta manejar formulaciones complejas y categorías poco frecuentes de la cola larga que aparecen raramente en los datos de entrenamiento. Además, mejorar su rendimiento suele requerir mucha computación y datos.
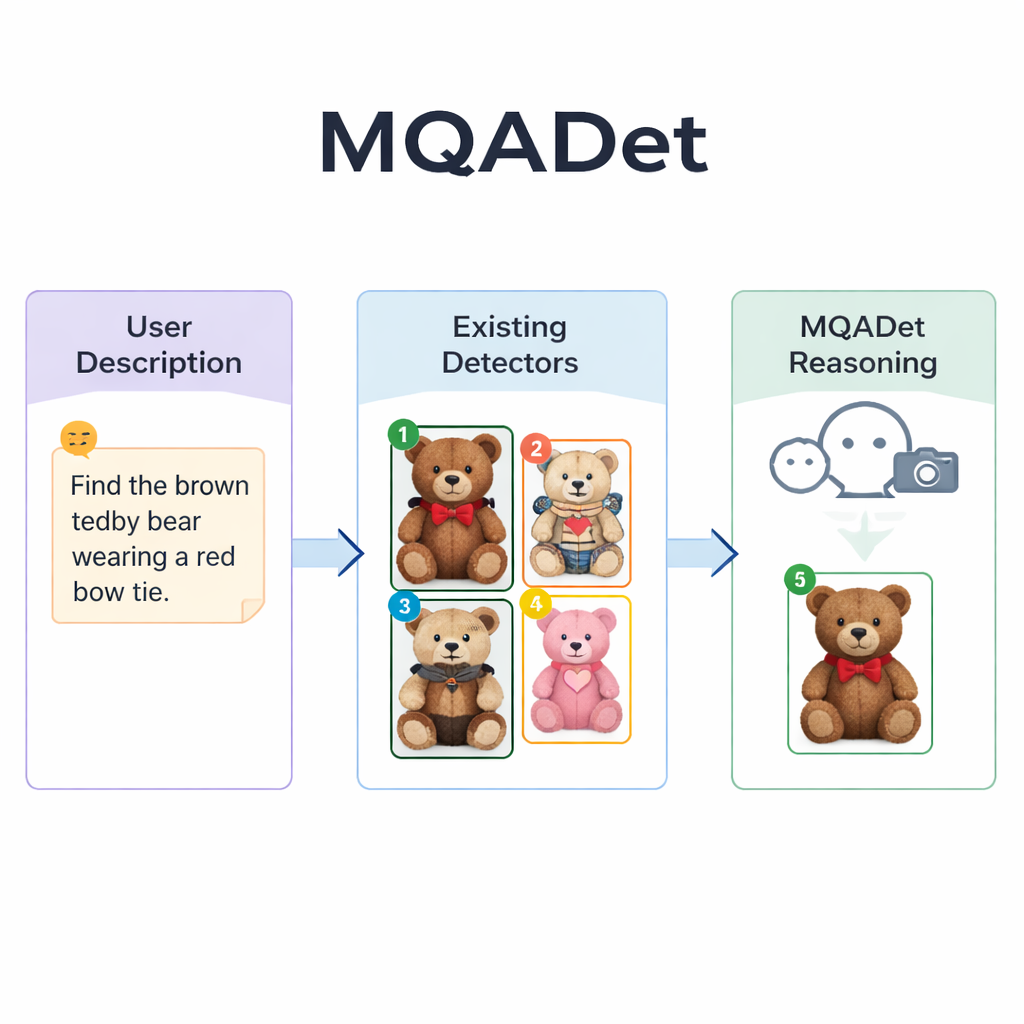
Permitir que los modelos de lenguaje guíen la búsqueda
MQADet aborda estos problemas situando un modelo multimodal de gran tamaño —un sistema que puede mirar imágenes y leer texto— encima de los detectores existentes en un proceso de preguntas y respuestas de tres pasos. Primero, una etapa llamada Extracción de Sujetos Consciente del Texto lee la frase completa del usuario y extrae los objetos reales a localizar, como «paraguas» y «peatón» en una descripción extensa. Esto refleja cómo una persona identificaría rápidamente los sustantivos principales de una oración antes de escanear una escena. Crucialmente, esta etapa aprovecha la sólida comprensión del lenguaje natural del modelo, por lo que puede manejar frases largas y descriptivas en lugar de limitarse a palabras sueltas.
Marcar objetos candidatos en la imagen
En la segunda etapa, Posicionamiento Multimodal Guiado por Texto, MQADet entrega esos sujetos extraídos junto con la imagen a un detector de vocabulario abierto existente —como Grounding DINO, YOLO-World u OmDet-Turbo—. El detector propone varias ubicaciones posibles en la imagen donde cada sujeto podría estar, trazando un recuadro alrededor de cada candidato y colocando un número sencillo dentro del recuadro. El resultado es una «imagen marcada» que muestra todas las opciones plausibles. Es importante destacar que MQADet no reentrena estos detectores; simplemente los utiliza tal cual. Esto hace que el enfoque sea plug-and-play: cuando aparece un detector mejor, se puede reemplazar en la canalización sin datos ni ajustes adicionales.

Razonar hasta encontrar la mejor coincidencia
La tercera etapa, llamada Selección Óptima de Objetos impulsada por MLLMs, convierte la elección final en una pregunta de opción múltiple para el modelo de lenguaje: dada la descripción original y la imagen marcada con cajas numeradas, ¿qué número coincide mejor con el texto? Porque el modelo ve tanto la redacción detallada como la disposición visual, puede ponderar pistas finas: patrones, colores, relaciones espaciales como «a la izquierda» e interacciones entre objetos. Los autores muestran que eliminar este paso de razonamiento reduce drásticamente la precisión, subrayando su importancia. Con este diseño de tres pasos, MQADet mejoró la precisión en cuatro conjuntos de evaluación exigentes con oraciones largas y naturales, a menudo aumentando el rendimiento de detectores existentes entre 10 y 40 puntos porcentuales sin cambiar sus pesos internos.
Qué significa esto para la tecnología cotidiana
Para un no especialista, el mensaje clave es que ya no es necesario reconstruir detectores de objetos desde cero para hacerlos más inteligentes. MQADet actúa como un asistente inteligente encima de los sistemas actuales, ayudándoles a interpretar descripciones humanas ricas y a elegir el objeto correcto en escenas complejas. Esto podría hacer que la búsqueda visual, las herramientas de asistencia y las máquinas autónomas sean más fiables al tratar con la forma natural en que habla la gente —llena de detalle, matices y contexto—, abriendo el camino a una interacción más intuitiva impulsada por el lenguaje con el mundo visual.
Cita: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
Palabras clave: detección de objetos de vocabulario abierto, modelos multimodales de gran tamaño, respuesta visual a preguntas, visión por computador, comprensión de imágenes