Clear Sky Science · es
Aplicación del aprendizaje automático en la predicción de resultados del tratamiento del cáncer de colon
Por qué importa predecir los resultados del cáncer de colon
El cáncer de colon es uno de los cánceres más comunes en todo el mundo, y muchos pacientes y familias quieren saber algo sencillo y urgente: «¿Cuáles son mis probabilidades y qué se puede hacer para mejorarlas?» Este estudio realizado en Irán explora cómo técnicas informáticas modernas, conocidas como aprendizaje automático, pueden analizar historiales médicos detallados para predecir mejor qué pacientes tienen mayor riesgo tras la cirugía. Al afinar estas predicciones, los médicos podrían ajustar con más precisión el tratamiento y el seguimiento, dando a los pacientes vulnerables una mejor oportunidad de supervivencia a largo plazo.
Convertir los registros hospitalarios en patrones útiles
Los investigadores utilizaron datos de 10 años procedentes de 764 personas que habían sido operadas por cáncer de colon en un centro importante de Shiraz, Irán. Para cada paciente recopilaron 44 datos, incluidos la edad, analíticas de sangre, tamaño del tumor, estadio del cáncer, síntomas y detalles de la operación y de tratamientos como la quimioterapia. Estos registros se limpiaron y verificaron cuidadosamente: se corrigieron valores de laboratorio imposibles, se eliminaron pacientes que no pudieron ser seguidos y las respuestas ausentes se completaron con estimaciones razonables. El equipo dividió los datos de modo que la mayor parte se usó para entrenar los modelos informáticos, mientras que una porción separada se reservó para comprobar qué tan bien esos modelos podían predecir quién estaría vivo o muerto en el seguimiento.
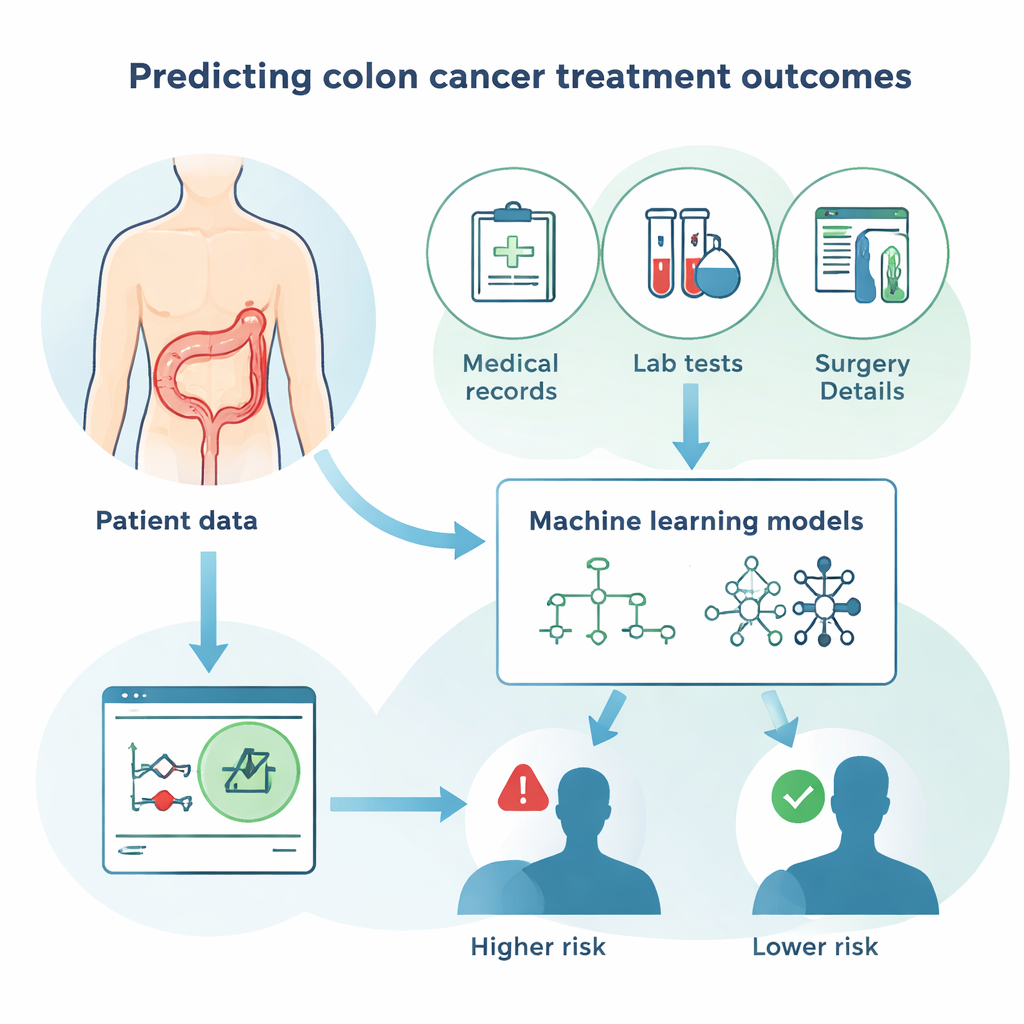
Cómo aprenden los algoritmos a partir de los pacientes
En lugar de basarse únicamente en la estadística tradicional, el estudio comparó varios enfoques informáticos modernos en paralelo. Estos incluyeron distintos métodos de «bosque» y «boosting», que combinan muchas reglas de decisión simples, así como redes neuronales, que imitan de forma aproximada cómo se conectan las células cerebrales. El objetivo para cada método fue el mismo: usar la información de los pacientes para adivinar si cada persona sobreviviría, y luego comparar esas predicciones con lo que realmente ocurrió. Los modelos se evaluaron por la frecuencia con que acertaban en general, por su capacidad para detectar a los pacientes que fallecieron y por su habilidad para evitar falsas alarmas en quienes vivieron. Los métodos con mejor rendimiento alcanzaron alrededor del 80% de precisión global, un resultado sólido dada la complejidad de los desenlaces del cáncer.
Qué modelos y factores fueron los más importantes
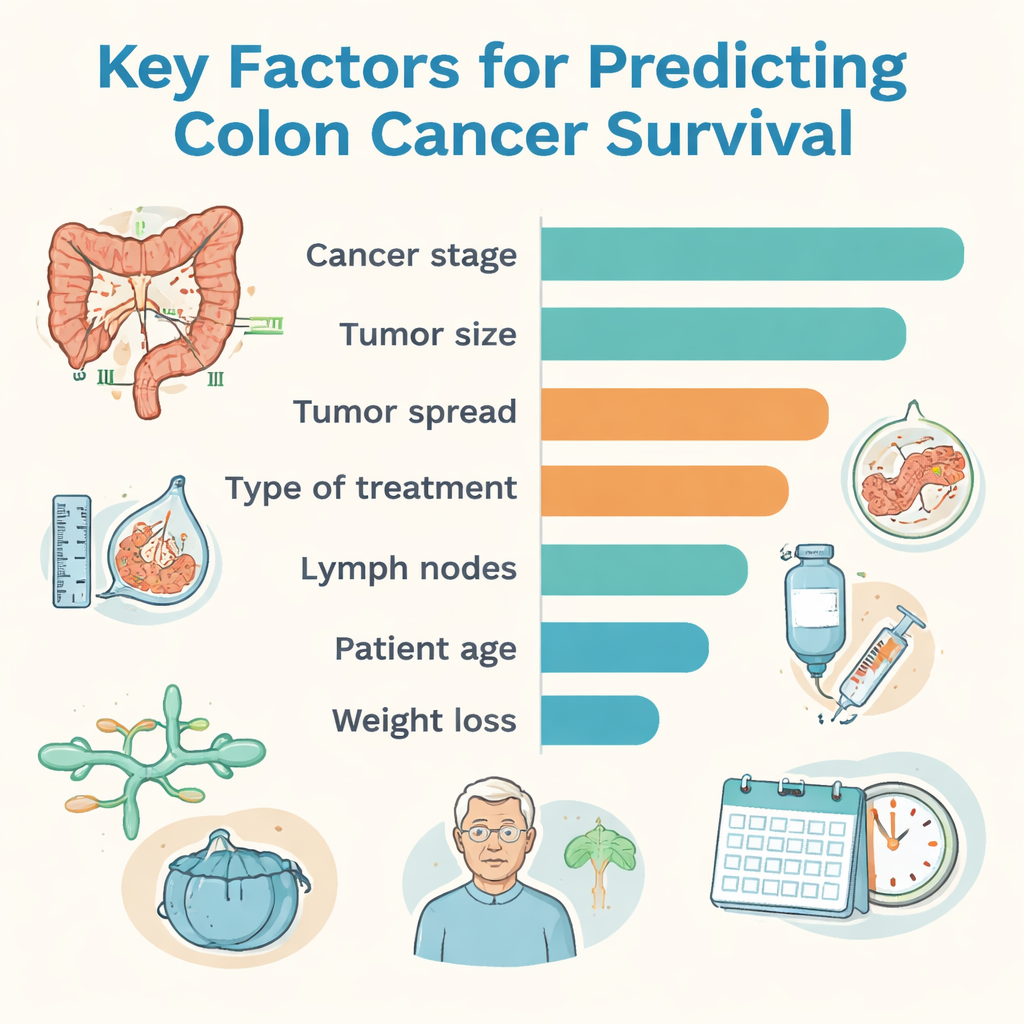
Entre todos los enfoques, un método llamado CatBoost ofreció la mayor precisión global, mientras que un modelo de bosque aleatorio mostró el mejor equilibrio entre identificar correctamente a los pacientes de alto riesgo y no sobrestimar el riesgo en los que evolucionaron bien. Para hacer los resultados más comprensibles para los médicos, el equipo utilizó una herramienta de explicación que ordena qué piezas de información influyeron más en las decisiones del ordenador. El estadio del cáncer —un resumen de cuánto mide el tumor, si ha alcanzado los ganglios linfáticos y si se ha diseminado— fue el factor más determinante. El tamaño del tumor, la profundidad de invasión en la pared del colon, la presencia de metástasis en otros órganos, el tipo de tratamiento, el grado tumoral (qué tan anormales se veían las células), la afectación de vasos linfáticos y sanguíneos, la edad del paciente y la pérdida de peso también tuvieron papeles importantes en la conformación de las predicciones de supervivencia.
De los números a las decisiones en la clínica
Estos hallazgos sugieren que un modelo informático bien entrenado, alimentado con información clínica rutinaria, puede ayudar a los médicos a detectar pacientes que silenciosamente tienen alto riesgo tras la cirugía por cáncer de colon. En la práctica diaria, una herramienta así podría integrarse en la historia clínica electrónica, combinando al instante detalles sobre el tumor y la salud general del paciente en una estimación simple de riesgo. Ese número no sustituiría el juicio del médico, pero podría orientar decisiones como la frecuencia de las revisiones, si tratamientos adicionales merecen los efectos secundarios o cuándo es necesario solicitar una segunda opinión. Dado que los factores más importantes identificados por el ordenador coinciden con lo que los especialistas en cáncer ya consideran crítico, el sistema resulta más fácil de confiar y de explicar a los pacientes.
Qué significa esto para los pacientes y el futuro
Para pacientes y familias, el mensaje clave es que los ordenadores ya pueden usar datos médicos ordinarios para apoyar una atención más personalizada del cáncer de colon. Aunque el estudio se realizó en un único centro en Irán y todavía debe probarse en otros hospitales y con datos más ricos, como información genética y de imagen, muestra que el aprendizaje automático puede destacar quién necesita atención adicional y por qué. Con el tiempo, a medida que se añadan más datos y se refinen los modelos, estas herramientas podrían ayudar a los médicos de todo el mundo a ofrecer un tratamiento que no solo esté respaldado por la evidencia, sino también ajustado con precisión a la enfermedad y las circunstancias de cada persona.
Cita: Ghasemi, H., Hosseini, S.V., Rezaianzadeh, A. et al. Machine learning application in colon cancer treatment outcome prediction. Sci Rep 16, 6159 (2026). https://doi.org/10.1038/s41598-026-36917-0
Palabras clave: cáncer de colon, aprendizaje automático, resultados del tratamiento, predicción de riesgo, datos clínicos