Clear Sky Science · es
Reduciendo la brecha de rendimiento: optimización sistemática de LLMs locales para la extracción de PHI médica en japonés
Por qué esto importa para la privacidad del paciente
Los hospitales disponen de enormes colecciones de notas médicas que podrían mejorar la atención y la investigación, pero estos registros están llenos de datos sensibles como nombres, direcciones y fechas. Los potentes sistemas de IA en la nube son muy eficaces para ocultar esta información, sin embargo muchos hospitales no pueden enviar datos de pacientes sin procesar a servidores externos. Este estudio muestra que, con un ajuste cuidadoso, modelos de IA más pequeños que se ejecutan completamente dentro del hospital pueden acercarse sorprendentemente al rendimiento de los mejores sistemas en la nube, ofreciendo una forma de usar IA manteniendo los datos de los pacientes de forma segura en las instalaciones.
El dilema privacidad versus progreso
Los modernos modelos de lenguaje grande pueden identificar y eliminar de forma fiable la información sanitaria protegida (PHI) de textos médicos, a menudo superando el 90 por ciento de precisión. Sin embargo, enviar notas de pacientes sin editar a servicios en la nube plantea cuestiones legales y éticas bajo regulaciones como HIPAA, GDPR y la APPI de Japón. Muchas instituciones exigen una “soberanía de datos” completa, es decir, que la información nunca salga de sus propios equipos. Hasta ahora, los modelos locales capaces de ejecutarse en hardware interno generalmente fallaban al detectar muchos identificadores, obligando a los hospitales a un intercambio: análisis potentes en la nube o mayor privacidad con herramientas menos precisas. Los autores se propusieron comprobar si esa brecha podía cerrarse lo suficiente para uso clínico real.
Un plan por fases para una IA local más inteligente
El equipo diseñó un marco de optimización en cinco pasos para mejorar de forma progresiva el rendimiento de modelos de lenguaje locales en la eliminación de PHI en informes de radiología en japonés. Comenzaron con 14 modelos diferentes de varios tamaños, todos ejecutándose en un ordenador aislado, sin acceso a Internet, diseñado para reproducir la seguridad hospitalaria. Usando 160 informes sintéticos cuidadosamente elaborados —realistas pero totalmente ficticios— midieron qué tan bien cada modelo identificaba y separaba ocho tipos de identificadores, desde nombres y números de identificación hasta fechas y departamentos. Tras una prueba basal inicial, crearon indicaciones generales más útiles, luego instrucciones adaptadas a las peculiaridades de cada modelo, añadieron un bucle automatizado de “auto-revisión y corrección”, y finalmente evaluaron los mejores candidatos en un conjunto reservado de informes. 
Aproximándose al rendimiento de la nube
A través de este proceso por fases, los investigadores descubrieron que el tamaño bruto del modelo no era la clave del éxito; algunos sistemas muy grandes seguían rindiendo mal. En cambio, los modelos más prometedores fueron aquellos que respondían bien al diseño cuidadoso de instrucciones y al análisis de errores. Un sistema de tamaño medio, Mistral-Small-3.2, se convirtió en el claro vencedor tras aplicar indicaciones personalizadas y una etapa de auto-refinamiento en la que el propio modelo revisaba y corregía selectivamente su output. En los 60 casos de prueba finales, esta configuración local optimizada obtuvo 91,54 de 100 —aproximadamente el 97,8 por ciento de los 93,56 puntos del principal modelo en la nube— mientras cumplía perfectamente las reglas de formato. En términos prácticos, su desventaja restante se consideró clínicamente menor. El principal coste fue la velocidad: el procesamiento local llevó alrededor de 25 segundos por informe típico, frente a menos de 2 segundos en la nube, pero esto se consideró aceptable para trabajos por lotes rutinarios y no urgentes. 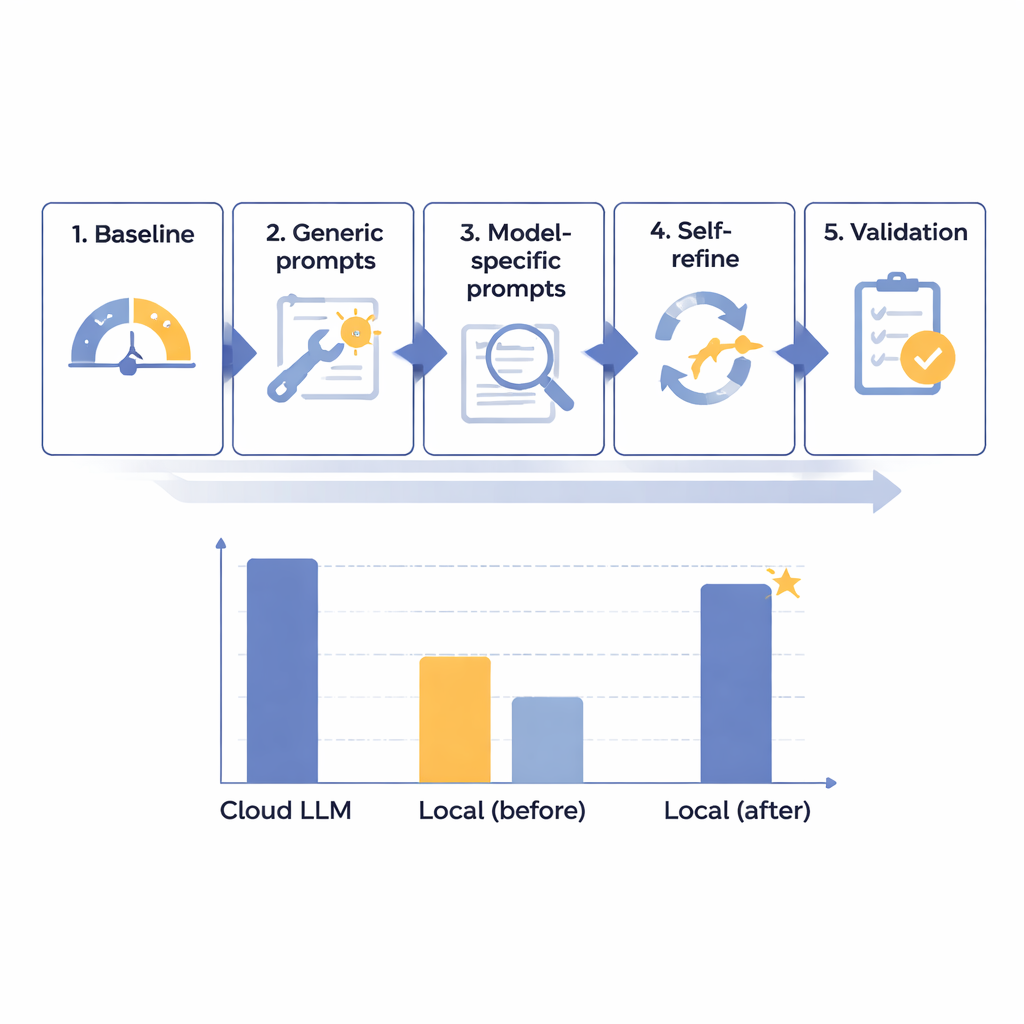
Un umbral sorprendente para la autocorrección
Uno de los hallazgos más intrigantes fue una especie de punto de inflexión alrededor de 87–88 puntos en la escala de 100 puntos de los autores. Los modelos que puntuaban por debajo de este nivel en la línea base —como Mistral-Small-3.2— se beneficiaron enormemente del bucle de auto-refinamiento, ganando casi siete puntos al corregir una pequeña fracción de sus propios errores. Los modelos que ya empezaban por encima de ese umbral mostraron casi ninguna mejora, y a veces desperdiciaron esfuerzo intentando “arreglar” respuestas correctas. Esto sugiere que las herramientas de optimización avanzada deberían reservarse para modelos que son buenos pero aún no excelentes, ofreciendo a los hospitales una forma de concentrar potencia de cálculo y tiempo del personal donde más rinde. Los autores advierten que este umbral se basa en solo dos modelos y necesita confirmación, pero ofrece una regla práctica inicial para la planificación del despliegue.
Qué significa esto para hospitales y pacientes
El estudio sostiene que los hospitales no tienen que elegir entre fuerte privacidad y buena IA. Con un enfoque sistemático —filtrar muchos modelos, afinar las indicaciones según sus fortalezas y debilidades, y añadir un paso inteligente de auto-revisión— es posible que un sistema totalmente local se acerque a la precisión de los mejores servicios en la nube para eliminar información sensible de textos médicos. En la práctica, esto abre la puerta a una estrategia híbrida: la PHI se elimina de forma segura en máquinas propiedad del hospital y solo informes anonimizado, con nombres y otros identificadores eliminados, se envían a la nube para análisis más avanzados. Aunque el trabajo hasta ahora se basa en informes sintéticos de radiología en japonés y debe probarse con datos del mundo real y otros idiomas, ofrece una hoja de ruta accionable para instituciones que quieran aprovechar la IA manteniendo la confianza y la privacidad del paciente en el centro.
Cita: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
Palabras clave: desidentificación médica, privacidad del paciente, modelos de lenguaje locales, IA en salud, informes de radiología