Clear Sky Science · es
Estimación de varianza basada en aprendizaje automático bajo muestreo en dos fases usando datos de los sectores salud y educación
Por qué las medias más inteligentes importan para decisiones del mundo real
Siempre que los médicos estudian la presión arterial o los educadores siguen las notas de los alumnos, no solo les importa la media; necesitan saber cuánto varían las personas en torno a esa media. Esta dispersión, llamada variabilidad, orienta cuántos pacientes reclutar para un ensayo, el tamaño que debe tener un programa de tutoría o cuánta confianza podemos poner en decisiones de política. El artículo que sintetiza este resumen presenta una nueva manera, con fundamento estadístico, de medir esa variabilidad con mayor precisión combinando ideas clásicas de muestreo con aprendizaje automático moderno, probada con datos de salud y educación.
Medir la dispersión cuando la información está incompleta
En un mundo ideal, los investigadores conocerían detalles adicionales sobre cada persona de una población antes de realizar una encuesta: edades, hábitos de estudio, historial médico y más. En la realidad, esa información suele ser incompleta o cara de recopilar. Los autores trabajan dentro de un diseño llamado muestreo en dos fases para manejar esto. En la primera fase toman una muestra amplia y relativamente económica y registran información de fondo sencilla, como la edad o si alguien tiene acceso a internet. En la segunda fase extraen un subsampleo más pequeño y miden un resultado más costoso o laborioso, como la presión arterial sistólica o las notas finales. El reto es usar esas dos capas de información para estimar cuán variable es realmente el resultado en toda la población.
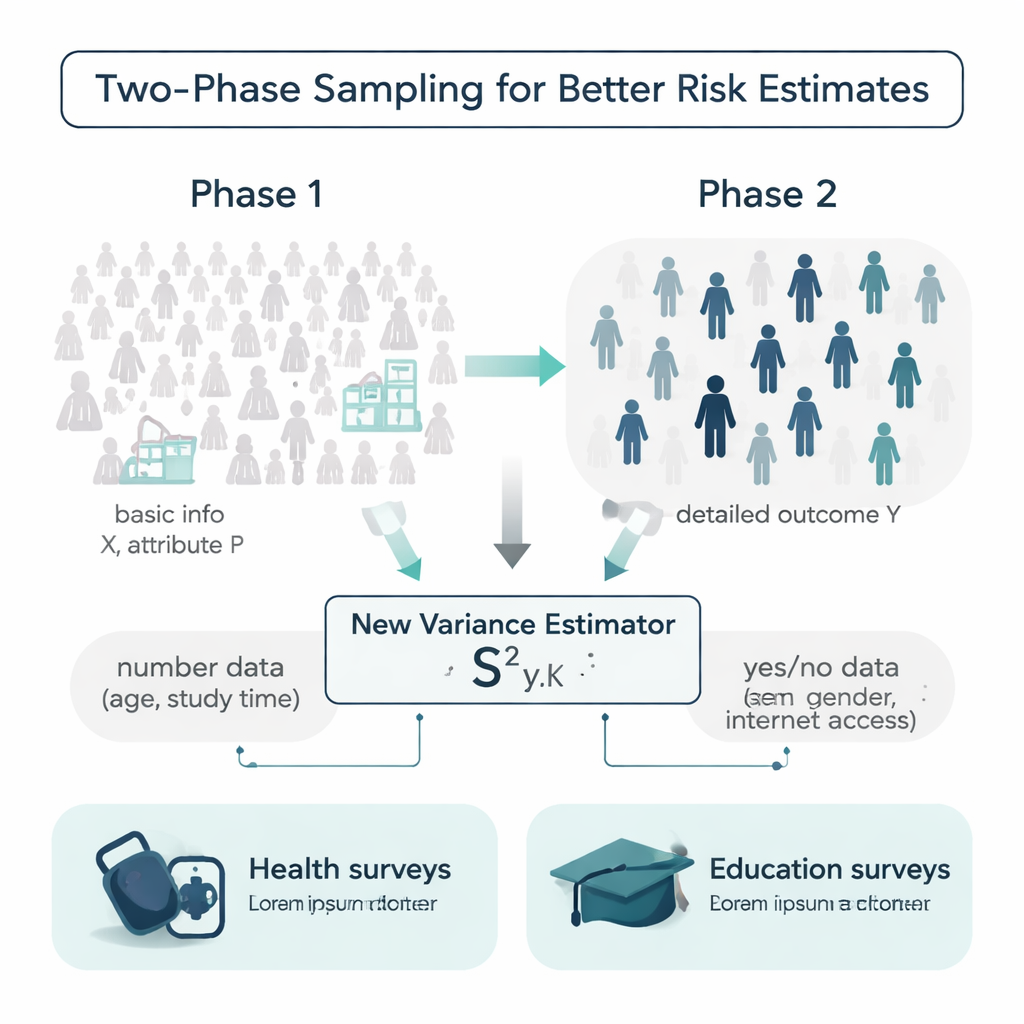
Un nuevo estimador que usa tanto números como rasgos sí/no
La mayoría de las herramientas tradicionales para medir variabilidad se basan solo en el resultado mismo o en una sola variable auxiliar, y a menudo asumen que los datos siguen patrones campana convenientes. Los autores proponen un nuevo estimador de la varianza que usa dos tipos de información adicional a la vez: un auxiliar numérico (por ejemplo, edad o horas semanales de estudio) y un atributo binario (como el sexo o el acceso a internet). Muestran matemáticamente cómo se comporta este estimador “mixto”, derivando fórmulas para su sesgo y su error cuadrático medio—dos medidas clave de precisión. Bajo condiciones razonables, el estimador es efectivamente insesgado y su error esperado es menor que el de fórmulas alternativas ampliamente usadas, lo que significa que debería proporcionar estimaciones de incertidumbre más nítidas con la misma cantidad de datos.
Probar el rendimiento en muchos mundos de datos
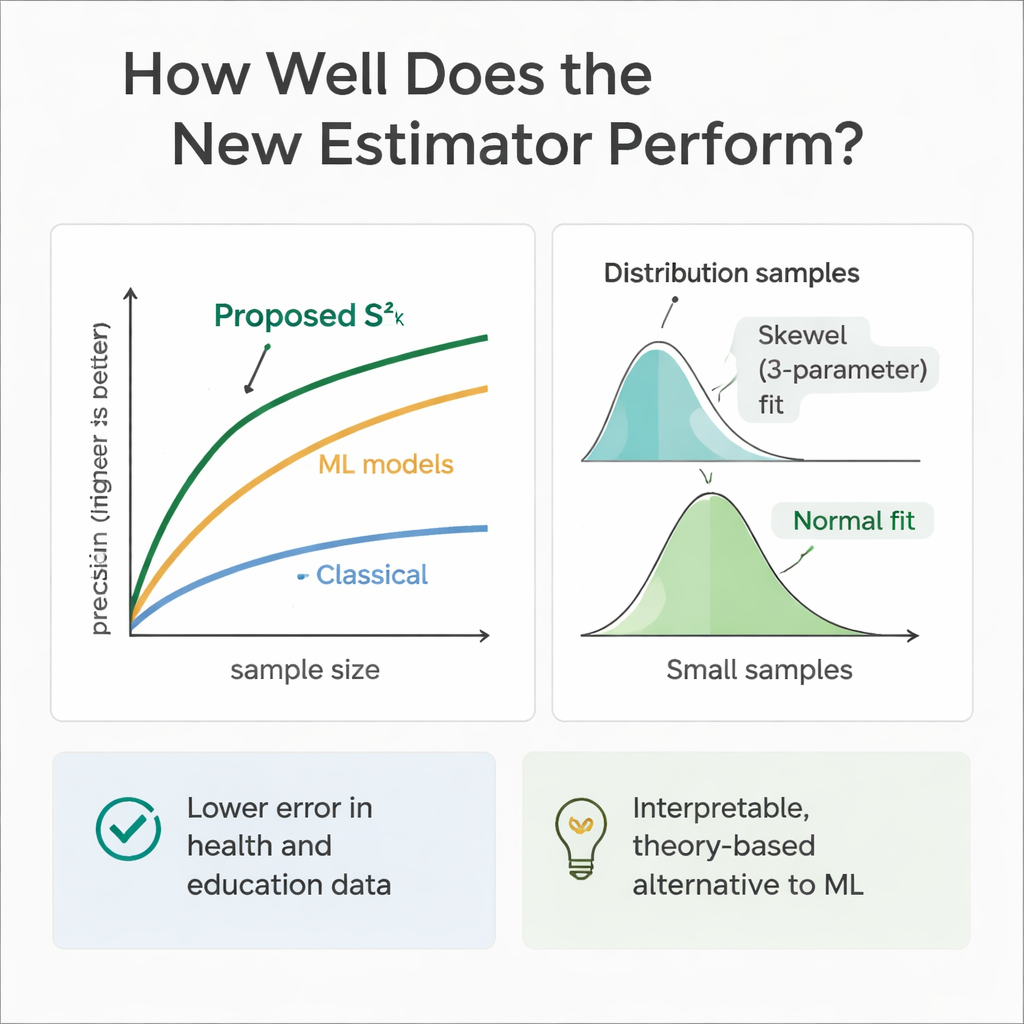
Para comprobar si la teoría concuerda con la práctica, el equipo realizó extensos experimentos por ordenador. Simularon poblaciones donde las variables auxiliares y el resultado seguían una gama de distribuciones, desde simétricas (Normal y Uniforme) hasta sesgadas (Gamma y Weibull). Usando muestreos repetidos, compararon el error del nuevo estimador con el de varios métodos establecidos en distintos tamaños muestrales. En casi todos los escenarios, y especialmente al aumentar el tamaño de muestra, el nuevo enfoque mostró una eficiencia relativa mucho mayor—frecuentemente reduciendo el error entre un 30 y un 70 por ciento en comparación con el estimador clásico de varianza. Los autores también examinaron cómo se comporta la distribución muestral del propio estimador, encontrando que una curva Weibull de tres parámetros la describe mejor para muestras moderadas, mientras que tiende hacia una forma Normal cuando el tamaño muestral es grande.
Datos reales de clínicas y aulas
El método se aplicó luego a dos estudios de caso del mundo real. En un conjunto de datos de salud, el resultado fue la presión arterial sistólica, con la edad como auxiliar numérico y el sexo como atributo binario. En un conjunto de datos educativos, el resultado fue la nota final del curso, el auxiliar fue el tiempo de estudio semanal y el atributo fue si el estudiante tenía acceso a internet. En ambos casos, el estimador propuesto produjo el menor error cuadrático medio entre todos los competidores estadísticos probados, ajustando de manera notable la variabilidad estimada alrededor de la media de la presión arterial y del rendimiento medio de los estudiantes. Esta mejora se traduce en intervalos de confianza más precisos y en comparaciones entre grupos o intervenciones más fiables.
Cómo se compara con el aprendizaje automático
Dado que los modelos de aprendizaje automático sobresalen en predicción, los autores también entrenaron árboles de regresión, bosques aleatorios y máquinas de soporte vectorial en los mismos escenarios simulados de salud y educación. Estos modelos, alimentados con las mismas variables auxiliares, a menudo igualaron o superaron ligeramente al nuevo estimador en precisión predictiva pura. Sin embargo, actúan como cajas negras: es difícil trazar exactamente cómo combinan la información y carecen de las fórmulas limpias necesarias para la inferencia tradicional en encuestas. Por el contrario, el estimador propuesto es transparente y está enraizado en la teoría del muestreo, lo que facilita su justificación en entornos regulatorios, clínicos o de política donde la explicabilidad importa tanto como el rendimiento bruto.
Qué significa esto para las encuestas en la práctica
En términos sencillos, este trabajo muestra que los investigadores pueden obtener medidas de dispersión más fiables sin aumentar dramáticamente los tamaños muestrales, simplemente haciendo un uso disciplinado incluso de la información adicional mínima que ya recogen. Al combinar un factor numérico (como la edad o el tiempo de estudio) con un rasgo binario simple (como el sexo o el acceso a internet) en un plan de muestreo en dos pasos, el nuevo estimador ofrece estimaciones de varianza más nítidas y estables que los métodos de larga data. Aunque las herramientas avanzadas de aprendizaje automático siguen siendo puntos de referencia útiles, este enfoque ofrece un término medio práctico e interpretable, ayudando a analistas de salud y educación a extraer conclusiones más sólidas a partir de datos limitados.
Cita: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
Palabras clave: muestreo por encuesta, estimación de varianza, aprendizaje automático, datos de salud, investigación educativa