Clear Sky Science · es
Modelado taxonómico y clasificación en la notificación de fallos de hardware espacial
Encontrar patrones en las fallas del vuelo espacial
Cada misión al espacio depende de innumerables piezas de hardware que deben funcionar a la perfección, desde tornillos y cables hasta los sistemas de soporte vital. Cuando algo falla, los ingenieros registran informes de discrepancias detallados, pero la NASA ya cuenta con más de 54 000 de estos registros: demasiados para que las personas los lean uno por uno. Este estudio muestra cómo las herramientas modernas de lenguaje y aprendizaje automático pueden convertir esa montaña de texto en conocimiento organizado, ayudando a los ingenieros a detectar patrones en las fallas, mejorar los diseños y proteger mejor a los astronautas.
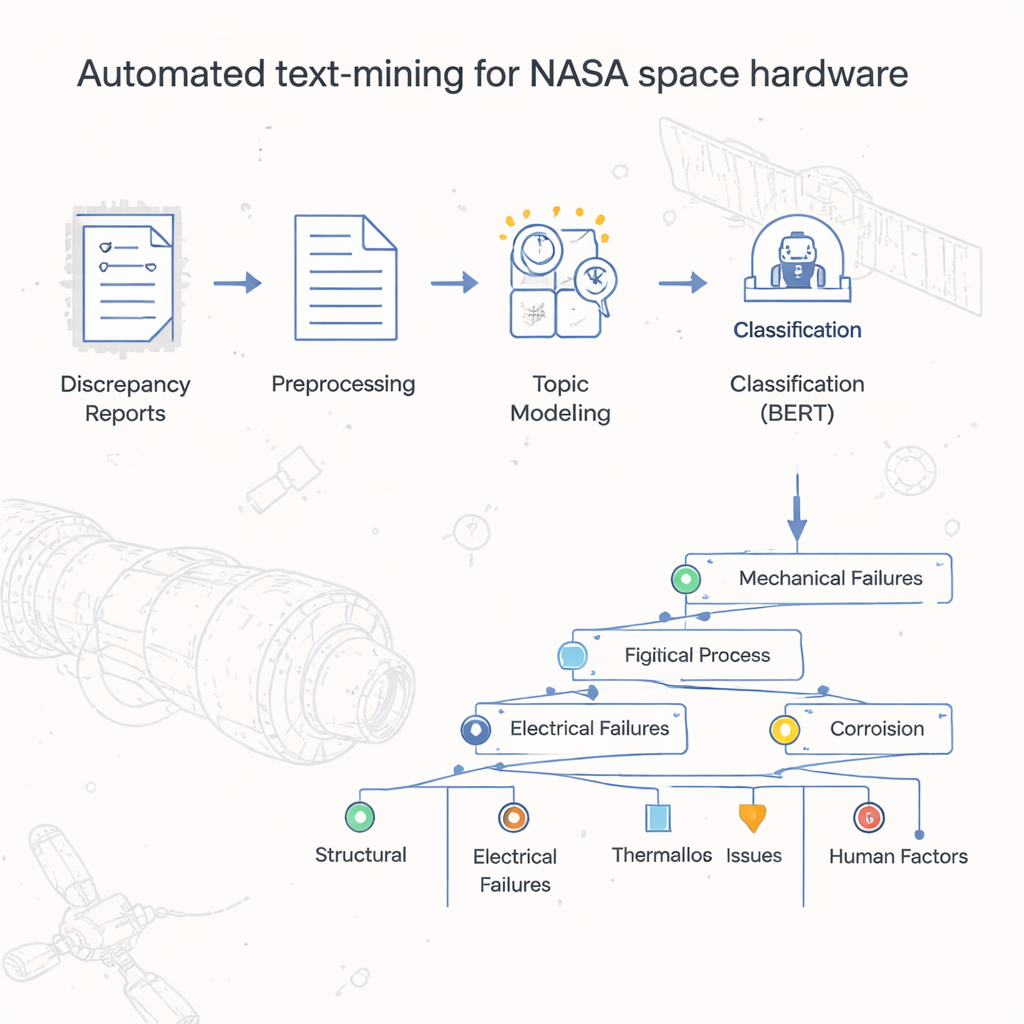
De montones de informes a una visión organizada
Durante décadas, el Johnson Space Center de la NASA almacenó los informes de fallos de hardware y discrepancias como documentos digitales, muy parecidos a versiones escaneadas de antiguos formularios en papel. Los recuentos básicos en hojas de cálculo revelaron qué códigos oficiales de defecto aparecían con más frecuencia, pero la historia real —las causas específicas, los pasos y las condiciones que llevaron a los problemas— estaba enterrada en campos de texto libre. Leer y clasificar más de 54 000 registros a mano sería prohibitivamente lento. Los autores se propusieron crear un método automatizado para clasificar y agrupar estos informes, construyendo una especie de “mapa” o taxonomía que capture cómo falla realmente el hardware espacial en la práctica diaria.
Enseñar a las máquinas a leer el lenguaje de la ingeniería
El equipo primero limpió el texto de cada informe para que los ordenadores pudieran trabajarlo de forma eficaz. Eliminó símbolos y dígitos sueltos que añadían ruido, segmentó las oraciones en palabras individuales y las convirtió a una forma base más simple (por ejemplo, transformando “leaked” y “leaking” en “leak”). Se filtraron las palabras comunes con poco significado, como “the” o “and”. Una vez estandarizado el texto, los investigadores lo convirtieron en números que los algoritmos de aprendizaje automático pueden manejar, utilizando técnicas consolidadas que capturan la frecuencia de las palabras y cuánto caracterizan a un documento. Esta base les permitió aplicar herramientas potentes, desarrolladas originalmente para tareas generales de lenguaje, al mundo altamente especializado de los informes de hardware espacial.
Construir un árbol de tipos de fallo
En el núcleo del proyecto hay un modelo en dos pasos que los autores denominan LDA-BERT. El primer paso, Latent Dirichlet Allocation (LDA), descubre automáticamente temas —denominados tópicos— buscando patrones de palabras que tienden a aparecer juntas a lo largo de miles de informes. Un único informe puede mezclar varios tópicos, reflejando la vida real donde un problema de hardware puede tener múltiples causas contribuyentes. El segundo paso usa BERT, un modelo moderno de lenguaje, para comprobar y refinar cuán bien esos tópicos separan los informes. Tratando los tópicos de LDA como etiquetas provisionales y entrenando a BERT para predecirlas, los investigadores pudieron identificar el número y la combinación de tópicos que ofrecían clasificaciones estables y precisas. A continuación, dividieron cada tópico en subtemas, usando clustering y comprobaciones estadísticas, para construir una taxonomía ramificada que organiza los informes de fallos desde códigos de defecto amplios hasta etiquetas detalladas a nivel de procesos.
Convertir taxonomías en tendencias accionables
Una vez establecida la taxonomía, el equipo la visualizó con paneles y herramientas interactivas. Cada rama y subrama del árbol podía vincularse a otra información de los informes: cuándo se detectó por primera vez un problema, cuánto tardó en cerrarse, qué organización era responsable y qué decisión final se tomó. Los gráficos temporales mostraban si ciertos tipos de problemas —como omisiones en inspecciones o cuestiones de datos de tolerancia— eran más o menos frecuentes a lo largo de los años. Los mapas de palabras ofrecían una percepción rápida del lenguaje usado en cada agrupación sin tener que leer todos los informes. Estas vistas ayudan a los responsables a centrarse en fallos de proceso con tendencias al alza y alto impacto, orientando la formación, los cambios de procedimientos o las mejoras de diseño donde más importan.
Límites de la búsqueda automática de causas raíz
Los investigadores también exploraron herramientas que intentan ir más allá del etiquetado y la detección de tendencias para inferir relaciones directas de causa y efecto a partir del texto. Probaron sistemas como INDRA-Eidos y conjuntos de reglas personalizados creados con la librería de lenguaje spaCy. Aunque estas herramientas pudieron extraer algunos pares de causa y efecto y visualizarlos como redes interactivas, muchos de los vínculos sugeridos resultaron demasiado vagos o confusos para ser útiles. En la práctica, los modelos tuvieron dificultades porque los informes originales a menudo no expresaban claramente las causas raíz; los ingenieros las daban a entender o las dejaban para investigaciones posteriores. El estudio concluye que automatizar de forma fiable el descubrimiento de causas raíz requeriría tanto una entrada de datos más rica —por ejemplo, campos explícitos para la causa probable— como un entrenamiento de modelos más costoso y altamente adaptado, algo que no se justifica para este análisis puntual.
Por qué esto importa para futuras misiones
Al convertir un archivo grande y no estructurado de informes de fallos en una taxonomía clara y escalonada, este trabajo proporciona a la NASA una forma práctica de vigilar cómo y por qué surgen los problemas de hardware a lo largo del tiempo. Aunque los métodos aún no pueden sustituir el juicio humano para un análisis profundo de causas raíz, destacan escaneando grandes volúmenes de texto para señalar dónde se concentran los problemas y qué tipos de procesos suelen estar implicados. Ese tipo de advertencia temprana e información estructurada puede ayudar a los equipos de ingeniería a priorizar su atención, perfeccionar procedimientos y diseñar sistemas más robustos: pasos concretos hacia misiones más seguras y fiables a la Luna, Marte y más allá.
Cita: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
Palabras clave: fallos de hardware espacial, procesamiento de lenguaje natural, modelado de temas, análisis de riesgo en ingeniería, informes de discrepancias de la NASA