Clear Sky Science · es
Representación colaborativa y aprendizaje semi‑supervisado impulsado por la confianza para la clasificación de imágenes hiperespectrales
Miradas más nítidas a los colores ocultos de la Tierra
Desde el seguimiento de la salud de los cultivos hasta la vigilancia de humedales, los científicos recurren cada vez más a las imágenes hiperespectrales: fotografías detalladas que capturan decenas o incluso cientos de colores que el ojo humano no aprecia. Estos datos ricos prometen mapas de uso del suelo y de vegetación más precisos, pero son notoriamente difíciles de analizar. Este estudio presenta un nuevo método, llamado GCN‑ARE, que interpreta estas imágenes complejas de forma más fiable y eficiente, abriendo la puerta a una mejor vigilancia ambiental, una agricultura más inteligente y una planificación urbana más avanzada.
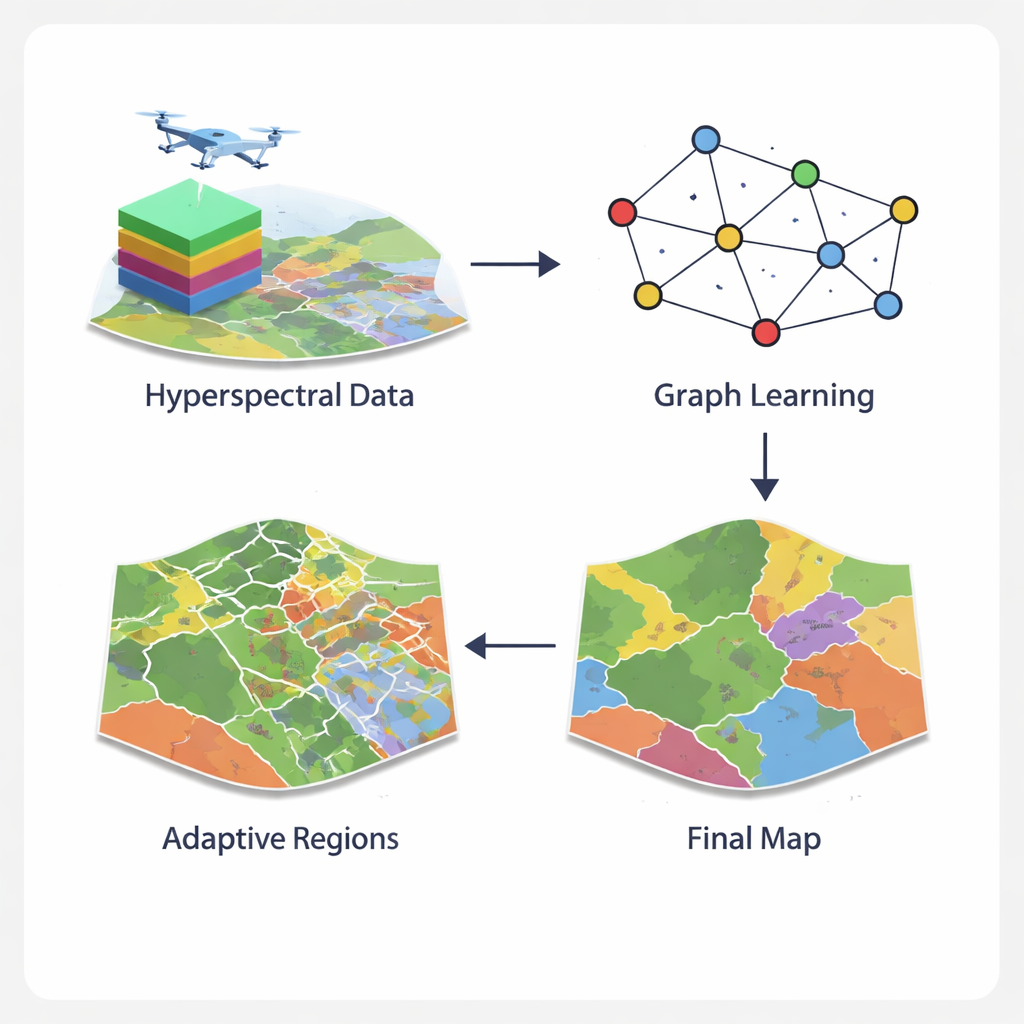
Por qué las imágenes hiperespectrales son tan complicadas
A diferencia de una foto normal, una imagen hiperespectral registra un espectro de color completo para cada píxel. Eso permite a los científicos distinguir, por ejemplo, hierba sana de hierba estresada, o distintos tipos de cultivo que en una imagen ordinaria parecen casi iguales. Pero esta riqueza crea desafíos. Las zonas contiguas pueden mezclar muchos tipos de cobertura, las clases suelen estar desequilibradas (algunas coberturas son raras) y el terreno puede ser irregular—piense en vegetación a trozos o bloques urbanos enmarañados. El aprendizaje automático tradicional depende de características diseñadas a mano y con frecuencia pasa por alto patrones sutiles, mientras que las redes profundas modernas, como las redes convolucionales y los Transformers, pueden tener dificultades con formas irregulares y requieren gran potencia de cálculo. Como resultado, modelos que funcionan bien en una escena pueden fallar en otra.
Convertir píxeles en una red inteligente
El marco GCN‑ARE aborda estos problemas replanteando cómo se representan las imágenes hiperespectrales. En lugar de tratar cada píxel de forma aislada o forzarlos en vecindarios cuadrados rígidos, el método construye un grafo: una red donde los píxeles son nodos y los píxeles próximos están conectados. Un operador gráfico especializado mantiene el flujo de información estable, evitando problemas numéricos que pueden descarrilar el entrenamiento cuando el terreno es irregular. Una red convolucional de grafos difunde y refina la información a lo largo de esta red, combinando lo que cada píxel “ve” en su espectro con lo que revelan sus vecinos. Esta visión basada en grafos captura de forma más natural distribuciones espaciales complejas, como límites de campos irregulares o vegetación urbana fragmentada, que los filtros de imagen estándar.
Reducir el tamaño de las regiones complejas
Incluso con un modelo de grafo potente, algunas partes de una imagen siguen siendo difíciles de clasificar—por ejemplo, las zonas fronterizas donde los cultivos se encuentran con carreteras o donde la vegetación se mezcla con suelo desnudo. GCN‑ARE aborda esto subdividiendo adaptativamente la escena en regiones según qué tan bien se están clasificando. Si una región rinde mal, se subdivide automáticamente en piezas más pequeñas y homogéneas mediante un paso de clustering que agrupa píxeles similares. Este proceso está guiado por reglas estadísticas, por lo que no es solo un truco visual: los autores muestran que, en teoría, estas divisiones reducen el error esperado del modelo, ayudándole a distinguir diferencias sutiles en la cobertura del suelo de forma más fiable.
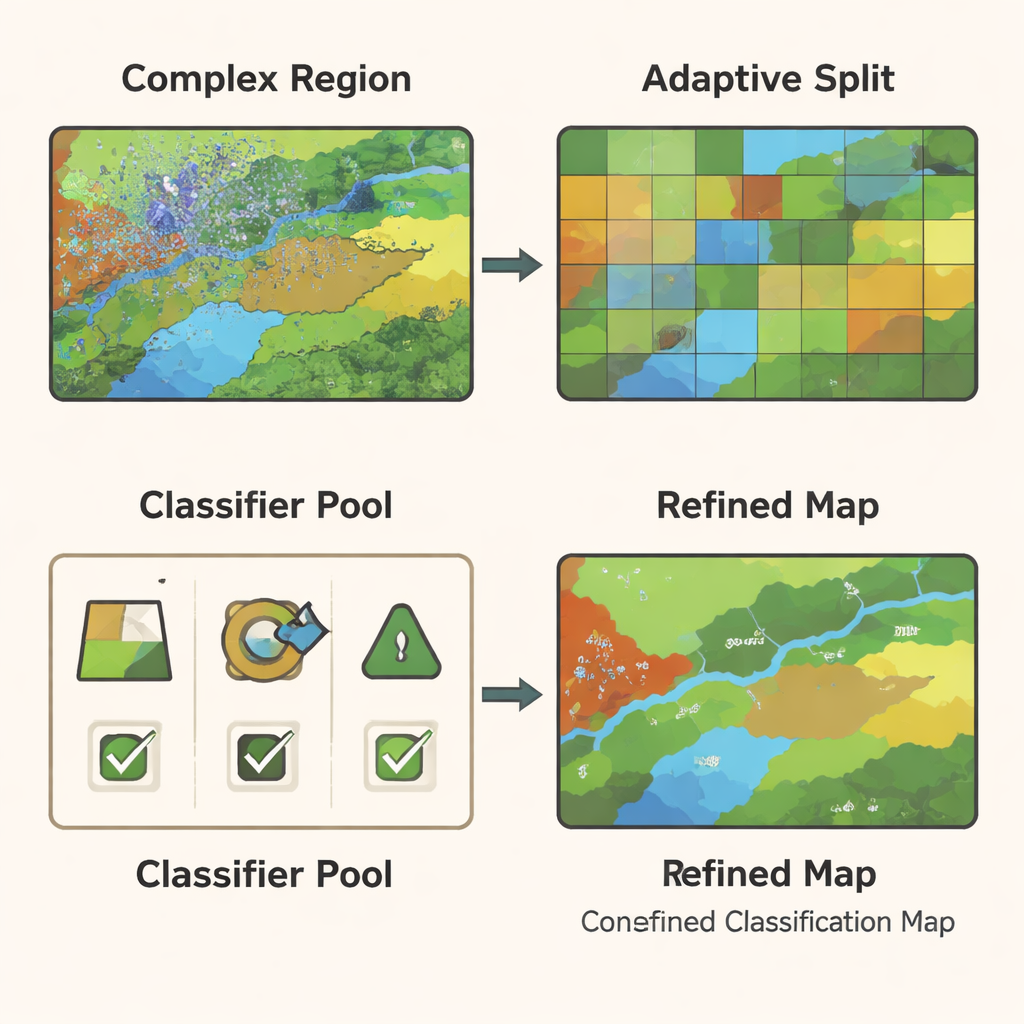
Dejar que múltiples clasificadores voten—pero con criterio
Diferentes tipos de clasificadores—como árboles de decisión, máquinas de vectores de soporte y bosques aleatorios—sobresalen en distintas condiciones. En lugar de apostar por un único modelo, GCN‑ARE entrena un pequeño conjunto de estos clasificadores sobre las características basadas en grafos y luego elige entre ellos región por región. La elección no es al azar: se emplea una herramienta matemática llamada desigualdad de Hoeffding para demostrar que, a medida que una región contiene más datos, la probabilidad de elegir el clasificador realmente mejor aumenta rápidamente. En el uso práctico, el sistema compara las predicciones de los clasificadores. Si hay consenso, acepta la decisión común; si no, activa el clasificador “mejor” seleccionado para esa región. Este conjunto adaptativo hace que el mapa final sea estable en las áreas sencillas y más preciso en las difíciles.
Demostrando su eficacia en el mundo real
Los autores probaron GCN‑ARE en cuatro conjuntos de datos bien conocidos: humedales en Botsuana, una zona urbana alrededor de Houston, tierras agrícolas en Indiana (Indian Pines) y una escena de cultivos de alta resolución en China (WHU‑Hi‑LongKou). En todos ellos, su método logró mayor exactitud global, mejor exactitud media por clase y mejores puntuaciones de acuerdo que enfoques líderes como las redes de atención sobre grafos y los Vision Transformers—mejorando típicamente la precisión global en alrededor de 1,5 a 5,7 puntos porcentuales. Fue especialmente efectivo reconociendo clases raras y fronteras complejas, y lo hizo con un consumo moderado de tiempo y memoria. Experimentos de ablación mostraron que tanto la subdivisión adaptativa de regiones como el conjunto dinámico eran esenciales: eliminar cualquiera de los dos reducía notablemente el rendimiento.
Qué significa esto para aplicaciones cotidianas
En términos prácticos, GCN‑ARE es una forma más inteligente de convertir datos hiperespectrales en mapas fiables. Al combinar una representación de grafo estable, un refinamiento dirigido de regiones y una selección de modelos con base estadística, produce mapas de cobertura del suelo más claros incluso cuando los datos etiquetados son escasos y el paisaje es complejo. Para los agricultores, esto puede significar un seguimiento de cultivos más preciso con menos mediciones de campo; para las agencias medioambientales, un seguimiento más fiable de humedales, bosques o expansión urbana. Aunque el método actual aún afronta desafíos a escalas verdaderamente masivas, los autores señalan vías para hacerlo más rápido y ligero, sugiriendo que estas herramientas de mapeo adaptativas e impulsadas por la confianza serán cada vez más importantes a medida que los sensores hiperespectrales se desplieguen desde satélites hacia aviones y drones.
Cita: Chen, Y., Lu, H. & Huang, X. Collaborative representation and confidence-driven semi-supervised learning for hyperspectral image classification. Sci Rep 16, 6180 (2026). https://doi.org/10.1038/s41598-026-36806-6
Palabras clave: imágenes hiperespectrales, cartografía de la cobertura del suelo, redes neuronales gráficas, aprendizaje en conjunto, teledetección