Clear Sky Science · es
Verificación de la autenticidad de noticias en urdu mediante aprendizaje profundo con incrustaciones concatenadas BERT y GloVe
Por qué importa detectar noticias falsas en urdu
En Pakistán y en todo el mundo, más personas obtienen ahora sus noticias de sitios web y redes sociales que de periódicos o televisión. Ese cambio ha facilitado más que nunca la rápida difusión de historias falsas, sobre todo en lenguas nacionales como el urdu, donde las herramientas digitales son limitadas. Este estudio aborda una pregunta sencilla pero urgente: ¿puede la inteligencia artificial moderna distinguir automáticamente noticias reales en urdu de las falsas, ayudando a lectores comunes, periodistas y plataformas a defenderse frente a la información engañosa?
El desafío creciente de la desinformación en línea
Los autores comienzan describiendo cómo los titulares fabricados y las historias distorsionadas pueden moldear la opinión pública, alimentar tensiones políticas e incluso perjudicar la salud y las finanzas de las personas. Mientras muchos sitios de verificación de hechos y proyectos de investigación se centran en inglés, las lenguas regionales como el urdu suelen quedarse atrás. Los recursos existentes en urdu incluyen solo unos pocos miles de noticias, muchas traducidas del inglés y centradas en temas reducidos como la política. Eso dificulta entrenar sistemas informáticos fiables para reconocer contenido sospechoso en la lengua que la mayoría de los pakistaníes realmente lee.
Construcción de una gran colección de noticias en urdu
Para cerrar esta brecha, los investigadores reunieron lo que describen como el conjunto de datos más extenso de noticias falsas en urdu hasta la fecha, con 14.178 artículos recopilados entre 2017 y 2023 de sitios de noticias pakistaníes y plataformas en línea respetadas. Las historias abarcan quince áreas de la vida cotidiana, incluida la política, la salud, la educación, los negocios, el crimen, los deportes y el medio ambiente. Usando fuentes de verificación de hechos como PolitiFact, FactCheck y APIs de noticias especializadas, cada elemento fue etiquetado como real o falso; los elementos parcialmente verdaderos se agruparon con las noticias reales para reflejar una información más matizada. El equipo limpió luego los textos eliminando duplicados, direcciones web y puntuación extra, separando las oraciones en palabras y suprimiendo palabras de relleno muy comunes.
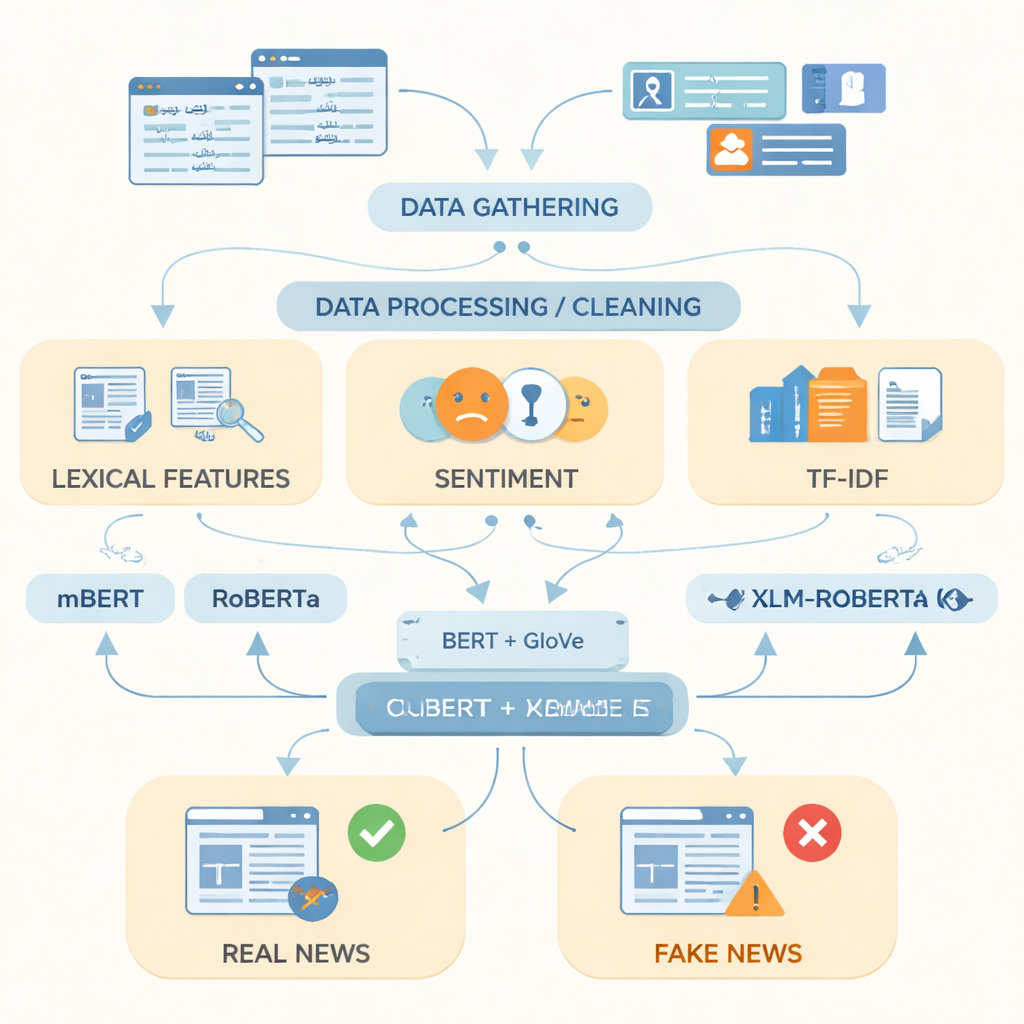
Enseñar a las máquinas cómo son las noticias falsas
Tras preparar los datos, los autores se centraron en la mejor forma de representar el texto en urdu para un ordenador. Combinaron indicadores simples como palabras de uso frecuente, el tono emocional del lenguaje y puntuaciones de frecuencia de término con dos potentes técnicas de representación de palabras. Una, llamada GloVe, trata cada palabra como un vector numérico fijo basado en la frecuencia con la que aparece junto a otras palabras en toda la colección. La otra, basada en modelos estilo BERT, analiza cada palabra en su oración y le asigna un significado sensible al contexto. Al unir estas dos perspectivas del lenguaje en una representación única y más rica, el sistema puede captar tanto patrones generales como sutiles variaciones en la redacción que a menudo distinguen historias falsas de las reales.
Poner a prueba modelos avanzados de lenguaje
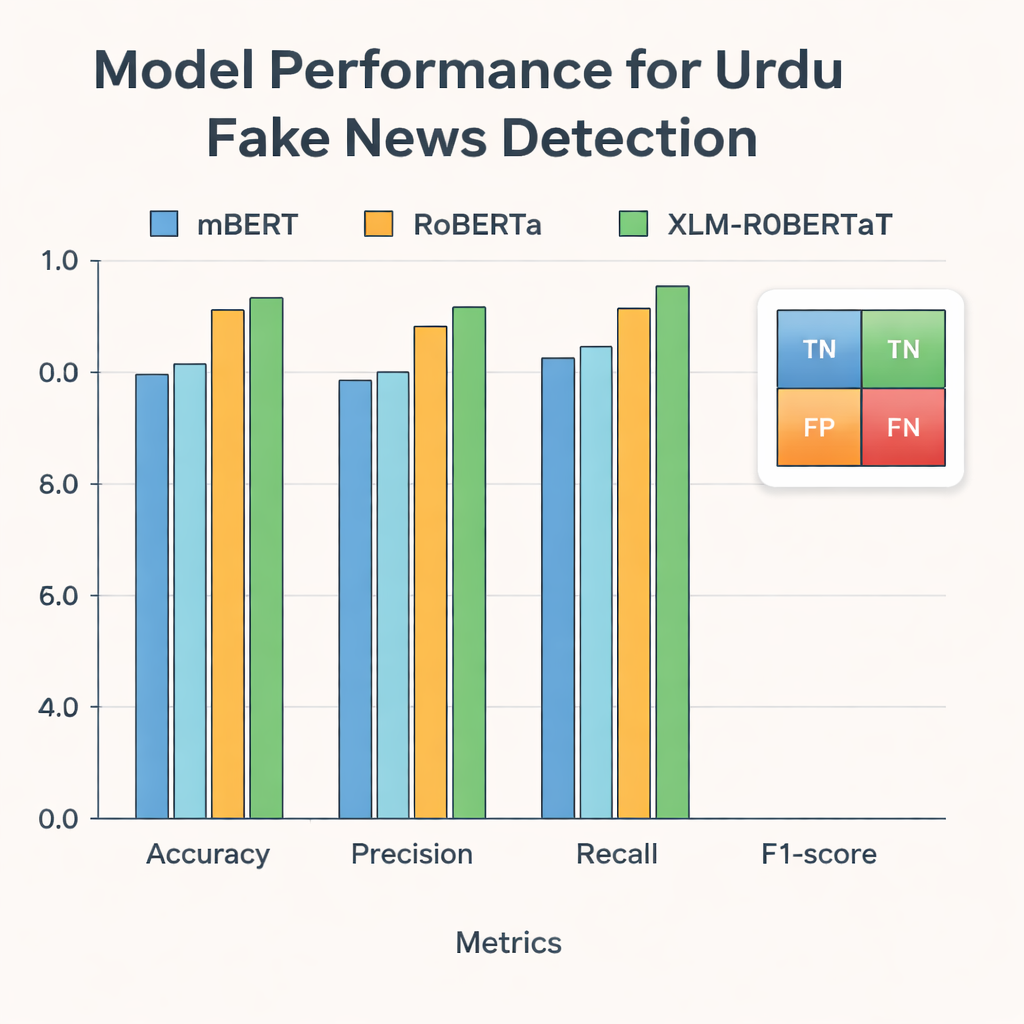
Los investigadores alimentaron luego estas representaciones a tres modelos modernos de aprendizaje profundo entrenados en textos de muchas lenguas: mBERT, RoBERTa y XLM-RoBERTa. Los tres fueron afinados con el conjunto de datos en urdu para predecir si cada artículo era real o falso. Su rendimiento se evaluó con medidas estándar: precisión (qué tan a menudo acertaban), precisión positiva (con qué frecuencia las piezas marcadas como falsas lo eran realmente), exhaustividad o recall (cuántas de todas las historias falsas detectaron) y la puntuación F1, que equilibra precisión y recall. Aunque todos los modelos mostraron un buen desempeño, XLM-RoBERTa combinado con la representación fusionada de BERT y GloVe fue el mejor, clasificando correctamente alrededor del 96% de los artículos de prueba y alcanzando una puntuación F1 de 0,956—mejor que los sistemas previos de detección de noticias falsas en urdu que usaban conjuntos de datos más pequeños o métodos más simples.
Qué significa esto para los lectores de a pie
Para los no especialistas, el mensaje es claro: con suficientes datos de noticias en urdu de alta calidad y el tipo adecuado de IA, ahora es posible construir herramientas que marquen automáticamente con gran fiabilidad las historias que probablemente sean falsas. El estudio demuestra que representaciones lingüísticas más ricas y modelos multilingües permiten a las máquinas entender mucho mejor cómo se escribe realmente el urdu en distintas regiones y temas. Aunque el trabajo actual se centra únicamente en texto y aún no analiza imágenes ni el comportamiento en redes sociales, sienta una base sólida para futuros sistemas que podrían operar a través de idiomas y tipos de medios. En términos prácticos, esta investigación acerca a Pakistán un paso más a complementos de navegador, paneles en salas de redacción o filtros en redes sociales que ayuden a la gente a separar hechos de ficción en la lengua que usan a diario.
Cita: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
Palabras clave: detección de noticias falsas, idioma urdu, aprendizaje profundo, BERT y GloVe, desinformación en línea