Clear Sky Science · es
Mejora de la estimación de profundidad a larga distancia mediante codificación heterogénea CNN-transformer y fusión semántica cross-dimensional
Ver la profundidad con un solo ojo
Los robots modernos, los coches autónomos y los drones suelen depender de sensores 3D caros para entender la distancia a los objetos. Este estudio muestra cómo las cámaras de color ordinarias, como las de los teléfonos inteligentes, pueden aprovecharse mucho más: los autores diseñan una nueva forma para que un ordenador infiera la profundidad a partir de una sola imagen, y se centran en la parte más difícil de la escena —la lejanía— donde los obstáculos son diminutos, borrosos y fáciles de juzgar mal.
Por qué es tan difícil juzgar objetos lejanos
La profundidad a partir de una sola imagen, llamada estimación monocular de profundidad, es un tipo de truco visual. Los objetos cercanos ocupan muchos píxeles y tienen texturas nítidas, por lo que las redes neuronales actuales ya funcionan bien a distancias cortas y medias. Sin embargo, a mayor distancia, los coches se reducen a unos pocos píxeles y las marcas viales se atenuan en la neblina. Las redes neuronales convolucionales estándar son buenas captando detalles locales finos pero tienen problemas para abarcar la visión global de una calle entera. Los modelos Transformer más recientes captan bien el contexto global, pero son menos sensibles a bordes y texturas minúsculos. Como resultado, ambas familias de métodos suelen fallar precisamente donde la navegación segura más necesita estimaciones fiables: a largas distancias.
Combinando dos formas de ver
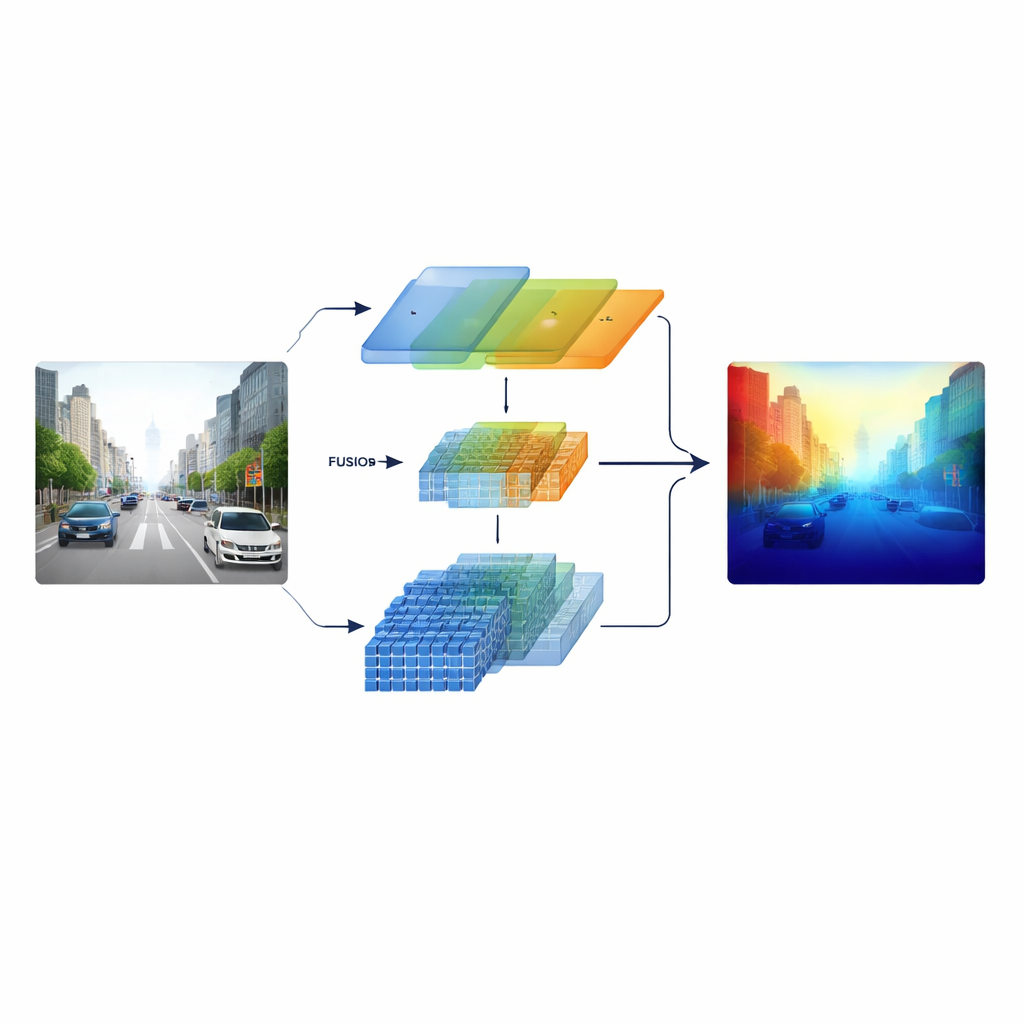
Los investigadores abordan esto construyendo un codificador “heterogéneo” que ejecuta en paralelo dos tipos distintos de procesamiento visual. Una rama se basa en una red convolucional de estilo ResNet clásica que se especializa en patrones locales nítidos como marcas de carril, postes y bordes de objetos. La otra rama utiliza un Swin Transformer, diseñado para capturar conexiones de largo alcance a través de la imagen, como la disposición de un corredor de carretera o el horizonte de edificios lejanos. En lugar de combinar estas dos perspectivas solo al final, el sistema conserva características multiescala de ambas ramas y las alimenta a una etapa de fusión cuidadosamente diseñada, de modo que la estructura fina y el contexto amplio se informen mutuamente a lo largo de todo el proceso.
Cruzando canales, espacio y escala
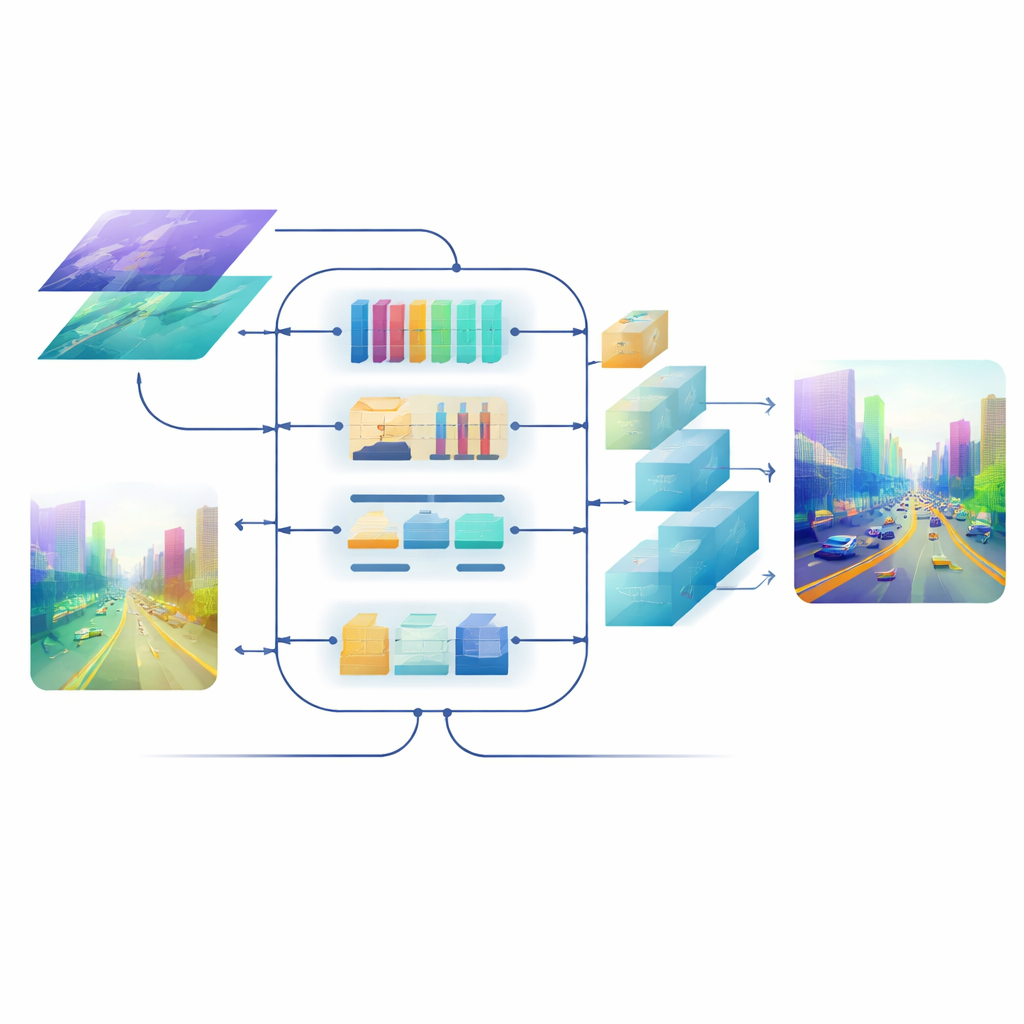
En el corazón del modelo hay un módulo de Fusión Semántica Cross-dimensional que actúa como una sala de reuniones inteligente para las dos corrientes de información. Primero, decide qué canales —diferentes tipos de patrones visuales aprendidos— merecen más atención, equilibrando señales de texturas detalladas y pistas de alto nivel de la escena. A continuación, analiza por separado en direcciones horizontal y vertical, especialmente significativas en escenas llenas de carreteras, edificios y árboles, para resaltar estructuras importantes que se extienden a lo largo de la imagen. Finalmente, mezcla características superficiales ricas en detalles con otras más profundas y abstractas a través de varias escalas. Un paso de ponderación entrenable permite a la red decidir cuánto confiar en cada rama para cada región, de modo que los objetos pequeños y lejanos no queden enmascarados por el paisaje cercano.
Afilar la imagen final
Aun con buenas características fusionadas, convertirlas de nuevo en un mapa de profundidad a resolución completa puede difuminar bordes y eliminar estructuras finas. Para evitarlo, el equipo diseña un decodificador impulsado por atención. Sus bloques de upsampling usan convoluciones depth-wise ligeras para ampliar el mapa sin perder contexto, y un mecanismo de autoatención multiescala agrupa canales de características para que la atención se calcule de forma eficiente. Este paso refina las predicciones de profundidad a cada escala manteniendo el cómputo bajo control. El resultado es un campo de profundidad suave y coherente donde los bordes de los objetos —como el contorno de un ciclista lejano o los peldaños de una litera— permanecen nítidos.
Qué tan bien funciona en el mundo real
El método se evalúa en varios conjuntos de datos estándar. En KITTI, una gran colección de escenas de conducción, el modelo alcanza una precisión de estado del arte en la mayoría de métricas comunes y, lo que es crucial, produce el error más bajo en las regiones designadas de largo alcance. También ofrece contornos de profundidad más limpios alrededor de los objetos que los sistemas competidores. En NYU Depth V2, que contiene escenas interiores, y en el benchmark SUN RGB-D, el mismo modelo generaliza con éxito, reconstruyendo muebles y distribuciones de habitaciones en nubes de puntos 3D convincentes. Los estudios de ablación —pruebas sistemáticas que eliminan o intercambian componentes— muestran que cada pieza propuesta, desde el codificador híbrido hasta el módulo de fusión y el bloque de atención del decodificador, mejora mediblemente el rendimiento, especialmente en áreas lejanas y de baja textura.
Qué significa esto para la tecnología de uso diario
En términos sencillos, este trabajo enseña a una red neuronal a usar a la vez una lupa y una lente gran angular, y a combinarlas con criterio. Al equilibrar mejor los detalles locales con la comprensión global de la escena, el marco propuesto mejora significativamente la capacidad de una sola cámara para juzgar la profundidad en la distancia o a través de una habitación. Esto hace más práctico equipar robots, vehículos y drones con sensores más baratos manteniendo una rica percepción 3D del mundo —un paso importante hacia sistemas autónomos más seguros, capaces y asequibles.
Cita: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
Palabras clave: estimación monocular de profundidad, visión por ordenador, fusión transformer y CNN, conducción autónoma, reconstrucción de escenas 3D