Clear Sky Science · es
La coincidencia de medias del kernel mejora la estimación del riesgo bajo cambios espaciales en la distribución
Por qué importa modelar el riesgo cuando los mapas cambian
Los modelos de aprendizaje automático se emplean cada vez más para prever dónde vivirán las especies, cómo se organizan los tumores en el tejido o cómo se dispersa la contaminación. Sin embargo, los datos usados para entrenar estos modelos suelen recogerse en lugares muy concretos: muestreos densos cerca de ciudades, hospitales o sitios de campo de fácil acceso, mientras que los modelos se aplican en regiones mucho más amplias y distintas. Esta discrepancia entre el origen de los datos y el ámbito de las predicciones puede hacer que los modelos parezcan más seguros y precisos de lo que realmente son. El artículo «Kernel mean matching enhances risk estimation under spatial distribution shifts» plantea una pregunta aparentemente sencilla: cuando el mundo se diferencia de tus datos de entrenamiento, ¿cuánto puede equivocarse tu modelo y cómo puedes detectarlo?
Cuando entrenamiento y prueba habitan mundos distintos
En estadística, el «riesgo» de un modelo es su error esperado sobre datos nuevos y no vistos. Los trucos habituales de evaluación, como la validación cruzada o retener un conjunto de prueba aleatorio, asumen tácitamente que los datos de entrenamiento y de prueba provienen de la misma distribución. Los datos espaciales rompen esa suposición. Gradientes ambientales, muestreos agrupados y climas cambiantes hacen que las condiciones donde entrenamos un modelo puedan diferir drásticamente de las donde lo desplegamos. Por ejemplo, las observaciones de especies suelen concentrarse cerca de carreteras, mientras que las decisiones de conservación se refieren a áreas remotas; las muestras tumorales pueden tomarse de una parte del tejido, pero se necesitan predicciones en otras zonas. En tales casos, las estimaciones convencionales de riesgo tienden a ser demasiado optimistas, ocultando cuán mal podría fallar un modelo en ubicaciones nuevas.
Las herramientas antiguas sufren con el sesgo espacial
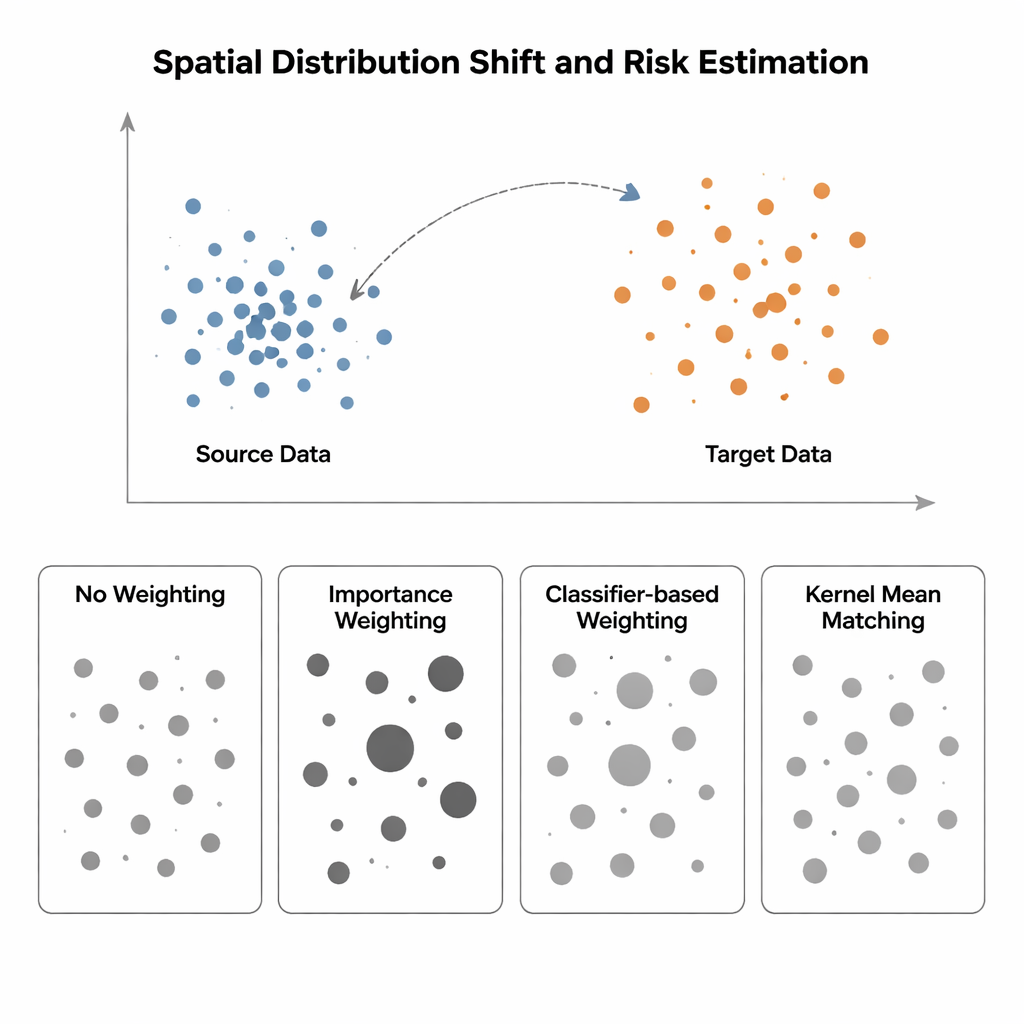
El estudio compara cuatro formas de estimar el riesgo del modelo cuando la distribución de entrada cambia desde una región «fuente» (donde las etiquetas son conocidas) a una región «objetivo» (donde las etiquetas son escasas o inexistentes). El método más simple, llamado Sin Ponderación, mide simplemente el error medio en los datos disponibles y asume que la fuente y el objetivo son similares—una suposición que falla ante el sesgo espacial. El Ponderado por Importancia intenta corregirlo escalando cada muestra de la fuente según lo frecuente que es ese tipo de punto en el objetivo respecto a la fuente. En teoría esto recupera el riesgo correcto, pero en la práctica requiere estimar densidades de probabilidad en alta dimensión. Cuando los datos de la fuente están muy agrupados y los del objetivo más dispersos—una situación típica en ecología espacial o imagen médica—estas estimaciones de densidad se vuelven poco fiables, y unas pocas muestras obtienen pesos enormes, volviendo la estimación del riesgo extremadamente inestable. Los enfoques basados en clasificadores, que entrenan un clasificador para distinguir puntos de fuente y objetivo y convierten sus probabilidades en pesos, evitan la estimación explícita de densidades pero a menudo producen riesgos mal calibrados porque optimizan la precisión de clasificación, no la alineación de distribuciones.
Una vía diferente: hacer coincidir las distribuciones directamente
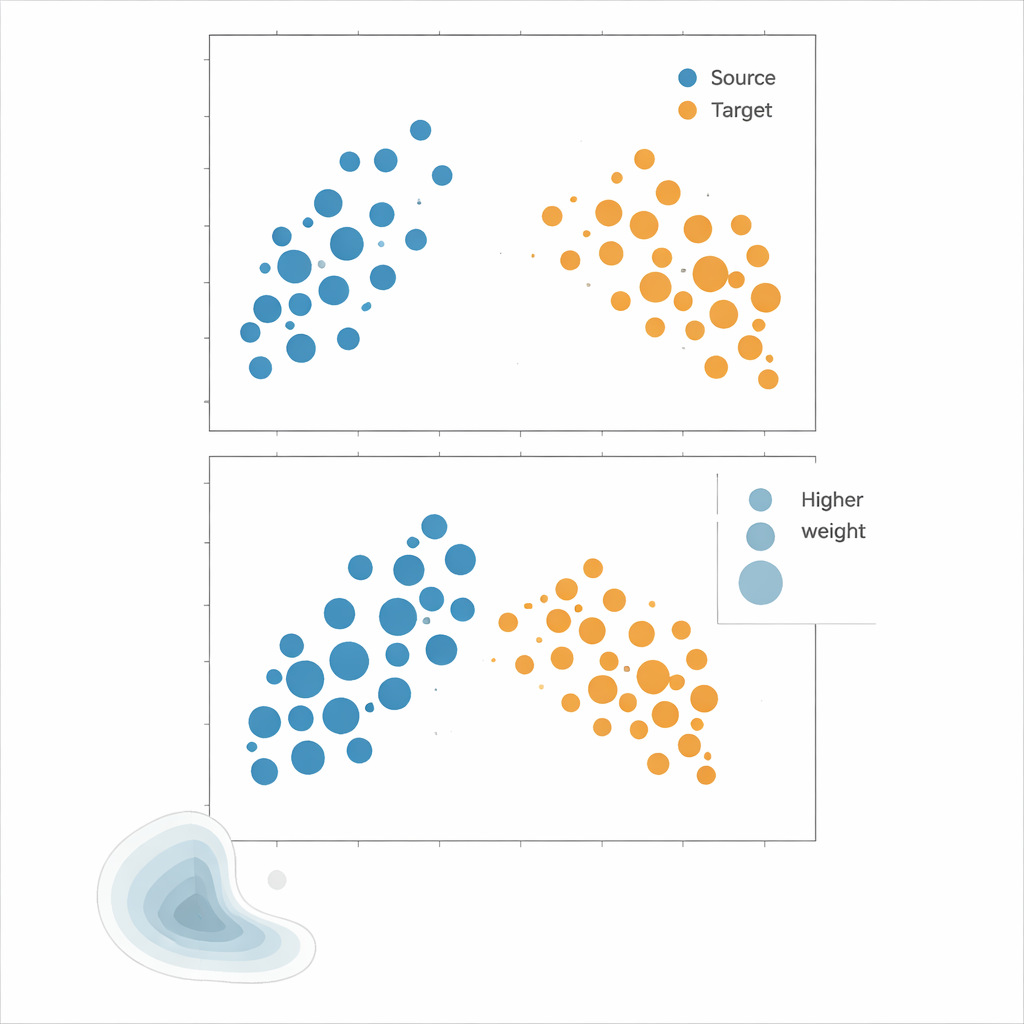
Los autores abogan por la Coincidencia de Medias del Kernel (KMM), un enfoque que evita por completo la estimación de densidades. En lugar de intentar calcular cuán probable es cada punto bajo las distribuciones de fuente y objetivo, KMM busca pesos sobre las muestras de la fuente que hagan que su «firma» media en un espacio de características flexible definido por un kernel coincida con la de las muestras objetivo. Intuitivamente, estira o reduce la influencia de cada punto de la fuente de modo que, en conjunto, la nube ponderada de la fuente se parezca a la nube del objetivo. Una vez hallados estos pesos, el riesgo se estima como un promedio ponderado de los errores en la fuente. Una herramienta complementaria, la Función de Correlación Local, cuantifica cuánto están agrupados los datos en el espacio; sirve como diagnóstico para indicar cuándo los desplazamientos de distribución son lo bastante fuertes como para que la reponderación sea útil.
Poniendo los métodos a prueba
Para ver qué estrategia funciona mejor, los autores realizan experimentos extensos tanto en datos sintéticos como en datos del mundo real. Los «paisajes» sintéticos se construyen a partir de mezclas de cúmulos gaussianos cuya extensión, forma y cobertura del dominio se pueden controlar con precisión, permitiendo pruebas estructuradas como recortar parte del dominio, cambiar patrones de correlación entre características o alternar entre patrones de puntos muy agrupados y casi uniformes. Los conjuntos reales incluyen ocurrencias de especies de plantas nórdicas, descritas por clima y ubicación, y disposiciones espaciales de células inmunitarias dentro de tumores. En todos estos escenarios, los modelos se entrenan con datos fuente agrupados y se evalúan en datos objetivo menos agrupados, imitando sesgos de muestreo comunes. El rendimiento se evalúa con varias métricas de error, centradas en cómo la estimación del riesgo de cada método sigue el error verdadero en el objetivo.
Riesgo más fiable en espacios complejos y de alta dimensión
En casi todos los montajes sintéticos y conjuntos reales, KMM proporciona las estimaciones de riesgo más precisas y estables. Reduce el error porcentual absoluto medio aproximadamente entre un 12 y un 87 por ciento en comparación con las alternativas, y, lo que es crucial, evita la «explosión de pesos» que afecta al ponderado por importancia en dimensiones altas. En configuraciones difíciles de disposición de células tumorales, por ejemplo, el ponderado por importancia puede dar lugar a errores que superan varios miles por ciento, mientras que KMM se mantiene dentro de límites manejables. La reponderación basada en clasificadores suele mejorar frente a los métodos ingenuos pero todavía queda por detrás de KMM, reflejando su énfasis en la discriminación en lugar de en una coincidencia fiel de distribuciones. Estos resultados sugieren que, para aplicaciones espaciales—donde los datos están agrupados, sesgados y son de alta dimensión—KMM ofrece una vía fundamentada para estimar cuánto confiar en las predicciones de un modelo.
Qué significa esto para decisiones del mundo real
Para quienes no son especialistas y usan aprendizaje automático en ecología, ciencias ambientales o biomedicina, el mensaje es claro: las puntuaciones de prueba estándar pueden inducir a error de forma peligrosa cuando la región de despliegue difiere de donde provienen tus datos. La Coincidencia de Medias del Kernel ofrece una manera de corregir esto reequilibrando la influencia de las muestras de entrenamiento para que se parezcan estadísticamente a los lugares o tejidos que te interesan. El estudio muestra que este enfoque produce sistemáticamente estimaciones de error de modelo más honestas, incluso bajo sesgo espacial severo y con muchas variables de entrada. En la práctica, eso se traduce en una guía más fiable al elegir entre modelos y una imagen más clara de dónde son de fiar las predicciones y dónde conviene ser cauto.
Cita: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
Palabras clave: cambio de distribución, modelado espacial, coincidencia de medias del kernel, estimación del riesgo del modelo, datos ecológicos y biomédicos