Clear Sky Science · es
Mejorando la resiliencia adversarial en el almacenamiento semántico para sistemas seguros de generación aumentada por recuperación
Por qué importa una memoria de IA más inteligente
A medida que los chatbots y asistentes de IA llegan a lugares de trabajo, aulas e incluso hospitales, dependen cada vez más de un truco llamado “recordar” preguntas anteriores para poder responder preguntas similares más rápido y a menor coste. Esta memoria, conocida como caché semántico, puede reducir drásticamente costes y latencias, pero también puede abrir una puerta trasera que permita a atacantes engañar a los sistemas para filtrar secretos o dar respuestas erróneas. Este artículo explora esos riesgos ocultos e introduce un nuevo diseño, SAFE-CACHE, que pretende mantener la memoria de la IA rápida a la vez que hace mucho más difícil su abuso.
Cómo los asistentes de IA reutilizan respuestas pasadas hoy
Los modelos de lenguaje grandes (LLM) modernos a menudo funcionan dentro de una arquitectura llamada generación aumentada por recuperación (RAG). Cuando haces una pregunta, el sistema primero busca documentos relevantes y luego el LLM redacta una respuesta usando ese material. Como muchas personas formulan prácticamente la misma pregunta con palabras distintas, las empresas añaden ahora una caché semántica: un almacén de preguntas y respuestas anteriores, además de huellas matemáticas de su significado. Cuando llega una nueva consulta, el sistema comprueba si su huella es “suficientemente cercana” a una ya presente en la caché; si es así, reutiliza la respuesta anterior en lugar de ejecutar todo el proceso de búsqueda y generación. Esta idea, desplegada por herramientas como GPTCache y plataformas en la nube de Microsoft y Google, ahorra dinero y acelera las respuestas en bots de atención al cliente, herramientas de chat empresariales y otros servicios de IA de alto tráfico. 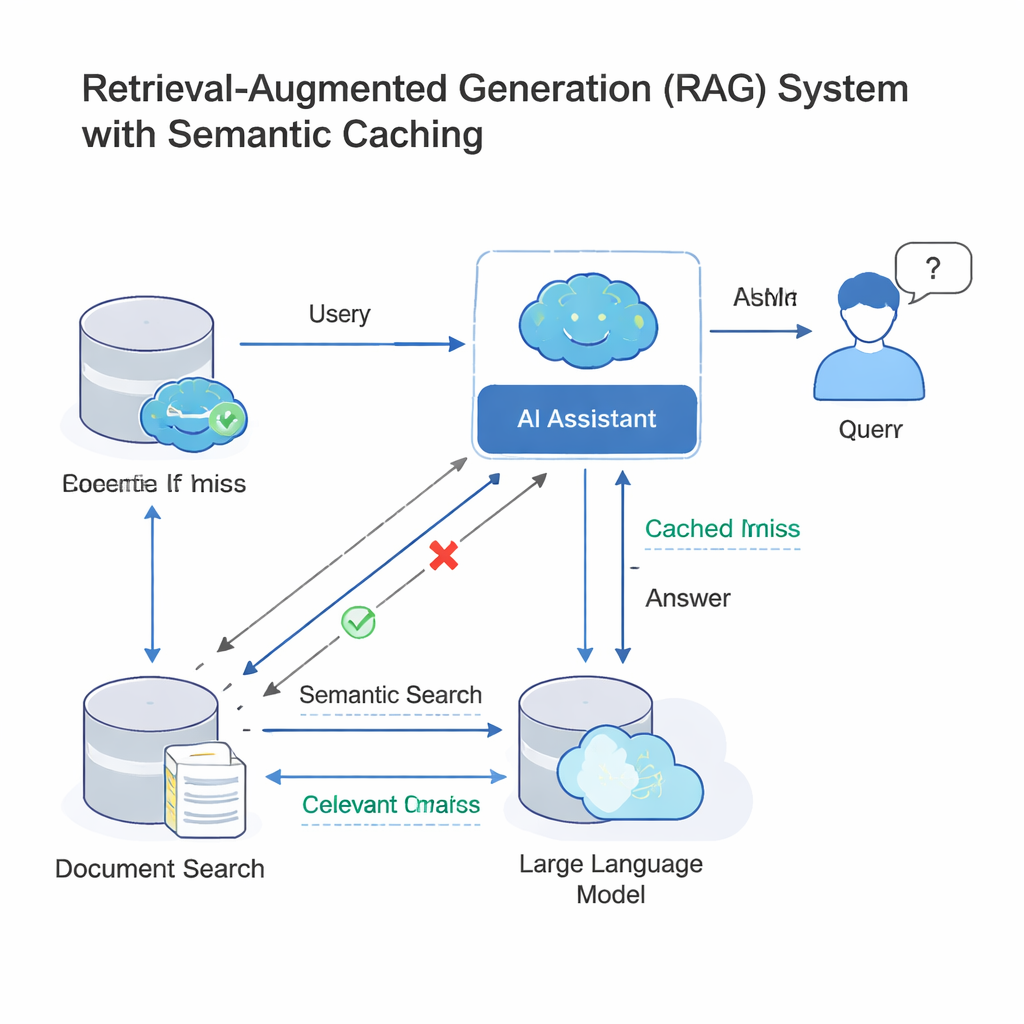
Cuando una redacción ingeniosa se convierte en un agujero de seguridad
El mismo atajo que aumenta la velocidad también puede volverse contra el sistema. Los atacantes pueden diseñar consultas que parezcan similares en estructura pero signifiquen algo distinto: cambiar una fecha, intercambiar una persona o un lugar, o invertir el sentido de una pregunta. Dado que las cachés actuales confían en gran medida en la similitud numérica de las incrustaciones (esas huellas del significado), una consulta maliciosa puede “colisionar” con una benigna en ese espacio vectorial, aun cuando la intención haya cambiado. Esa colisión puede hacer que la caché devuelva la respuesta equivocada, exponiendo potencialmente información confidencial o permitiendo que datos maliciosos se almacenen para su reutilización posterior. Trabajos previos ya han demostrado que las bases de datos vectoriales y las cachés semánticas pueden ser envenenadas de esta manera, especialmente cuando muchos usuarios comparten la misma caché subyacente en sistemas multiarrendatario.
Convertir preguntas dispersas en clústeres de intención estables
Los autores sostienen que el problema raíz es tratar cada consulta de forma aislada. Su solución, SAFE-CACHE, agrupa pares pregunta–respuesta anteriores en clústeres que representan intenciones subyacentes—como “¿quién ganó la elección al Senado de Arizona en 2022?” o “¿cuál es el precio del software Full Self-Driving de Tesla?”. En lugar de emparejar nuevas consultas directamente con entradas individuales antiguas, SAFE-CACHE las compara con el centro, o centróide, de cada clúster. Para construir estos clústeres, primero incrusta cada pregunta más su respuesta completa (no solo la pregunta) de modo que las diferencias en las respuestas—como una negativa a revelar datos sensibles—también influyan en la agrupación. Luego utiliza un algoritmo de detección de comunidades para encontrar clústeres naturales y pruebas estadísticas para marcar grupos ruidosos que puedan mezclar distintas intenciones o entradas adversariales. Estos clústeres sospechosos se limpian y dividen empleando un bi-encoder especialmente entrenado que ha aprendido a agrupar ejemplos honestos y separar los envenenados.
Enseñar a un modelo pequeño a reforzar la memoria de la IA
Algunas intenciones aparecen solo unas pocas veces en el tráfico real, lo que hace que sus clústeres sean frágiles. Para estabilizarlos, SAFE-CACHE utiliza un modelo de lenguaje ligero ajustado (una variante Gemma-3 de 1.000 millones de parámetros) para generar paráfrasis que mantienen la misma intención mientras varían la redacción. Estos ejemplos adicionales densifican los clústeres y hacen que sus centróides sean más fiables, sin necesidad de que humanos etiqueten miles de variantes. En tiempo de ejecución, cada nueva consulta se incrusta y se compara con esos centróides. Si su similitud con el centróide que mejor coincide supera un umbral cuidadosamente calibrado, se devuelve la respuesta en caché; de lo contrario, el sistema recurre al pipeline completo de RAG y luego decide cómo agrupar el nuevo par. En experimentos usando métodos de ataque potentes basados en reescritura metamórfica y GPT‑4.1, SAFE-CACHE redujo los intentos de envenenamiento exitosos aproximadamente entre dos tercios y tres cuartos en comparación con un diseño estilo GPTCache, manteniendo esencialmente sin cambios la velocidad de respuesta. 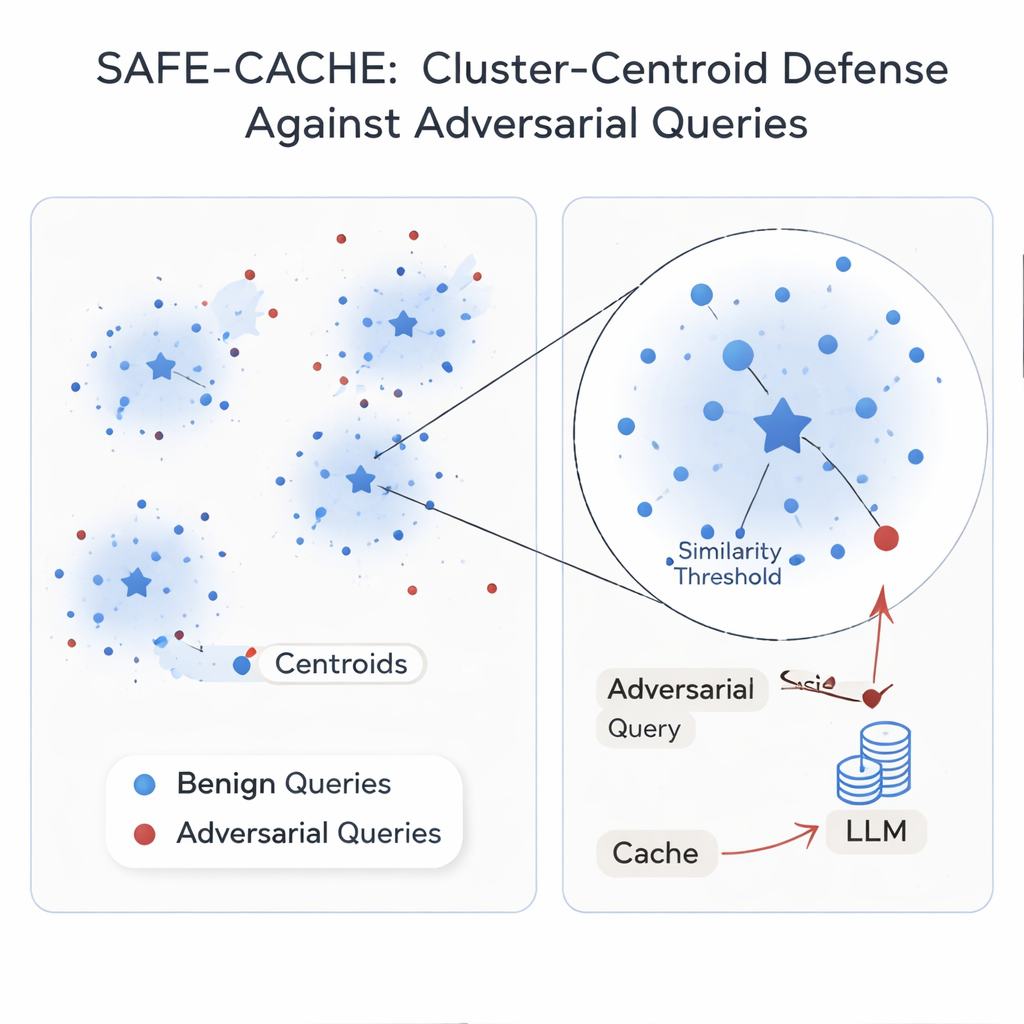
Qué significa esto para los usuarios cotidianos de IA
Para los no especialistas, la conclusión es que dar “memoria” a los sistemas de IA no es gratuito: los diseños ingenuos pueden filtrar secretos o ser engañados para propagar respuestas erróneas. SAFE-CACHE demuestra que, organizando la memoria en torno a patrones más profundos a nivel de intención y reforzando esos patrones con paráfrasis dirigidas, es posible conservar los beneficios de velocidad y coste del almacenamiento semántico mientras se reduce drásticamente el riesgo de ataque. A medida que los asistentes de IA se convierten en una puerta de entrada a datos sensibles—desde registros empresariales hasta información personal—enfoques como SAFE-CACHE serán clave para asegurar que lo que la IA recuerda no pueda volverse fácilmente en nuestra contra.
Cita: Afiffy, M., Fakhr, M.W. & Maghraby, F.A. Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems. Sci Rep 16, 5936 (2026). https://doi.org/10.1038/s41598-026-36721-w
Palabras clave: almacenamiento semántico, generación aumentada por recuperación, ataques adversariales, defensa basada en clústeres, seguridad de LLM