Clear Sky Science · es
Autoencoder guiado por importancia de características para la reducción de dimensionalidad en sistemas de detección de intrusiones
Por qué importan defensas cibernéticas más inteligentes
Cada correo que envías, vídeo que retransmites y compra que realizas viajan por redes que están constantemente bajo ataque. Los sistemas de detección de intrusiones (IDS) actúan como alarmas para esas redes, detectando comportamientos sospechosos antes de que se conviertan en una brecha. Pero los datos de red modernos son enormes y complejos, y filtrar todos esos detalles puede ralentizar los sistemas o hacer que pasen por alto ataques sutiles. Este artículo explora una nueva forma de reducir esos datos de manera inteligente para que las herramientas de IDS sean tanto más rápidas como mejores detectando incluso ciberataques raros y difíciles de identificar. 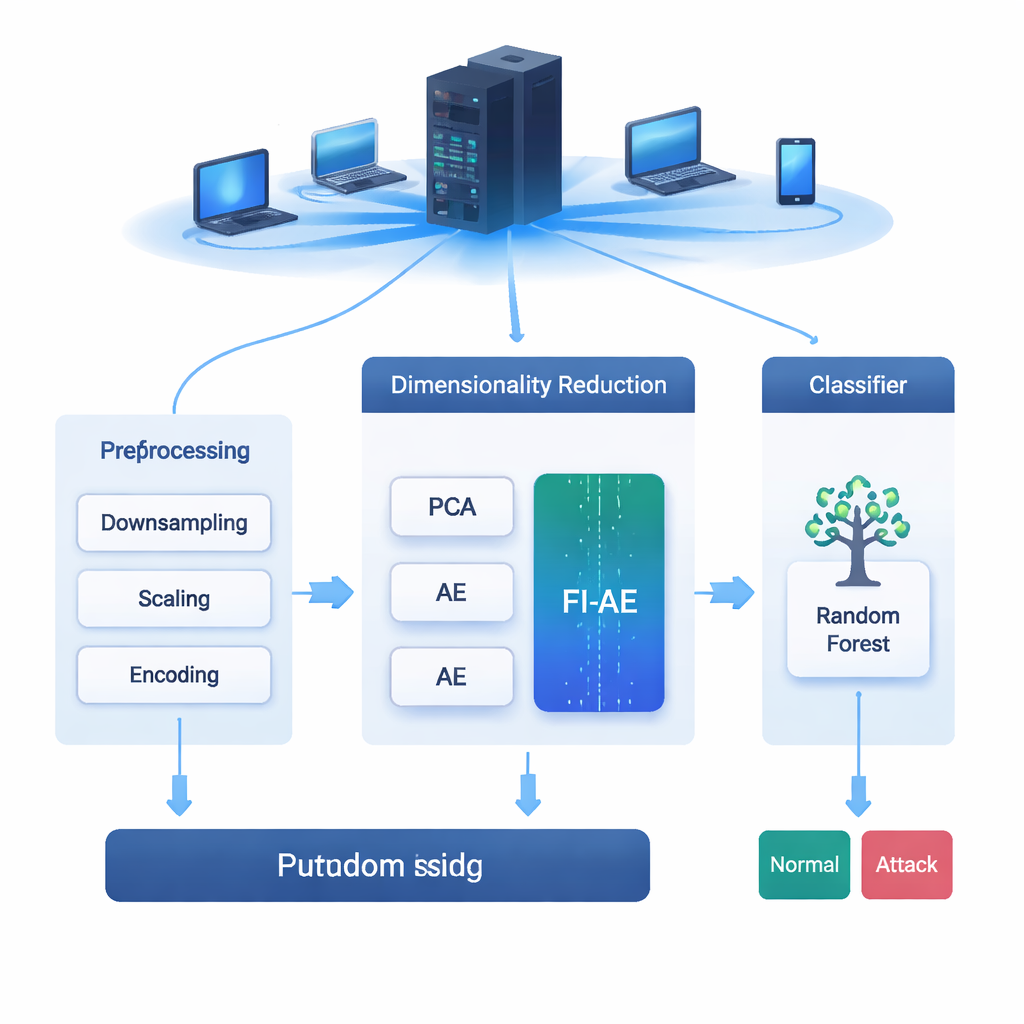
El problema de tener demasiados datos de red
Los registros de tráfico de red contienen desde decenas hasta cientos de medidas por cada conexión—como duración, número de bytes y tasas de error. Los modelos de IDS basados en aprendizaje automático se apoyan en estas medidas para decidir si el tráfico es normal o malicioso. Sin embargo, usar todas ellas puede ralentizar la detección e incluso perjudicar la precisión, sobre todo cuando algunos ataques son mucho más raros que otros. Los métodos comunes de reducción de dimensionalidad, como el análisis de componentes principales (PCA) y los autoencoders estándar, comprimen los datos pero se centran principalmente en reconstruir el tráfico en su conjunto. Eso significa que pueden prestar más atención a la mayoría de las conexiones cotidianas y pasar por alto los patrones tenues y distintivos que caracterizan a los tipos de ataque minoritarios.
Una nueva forma de clasificar lo que realmente importa
Los autores introducen un esquema de clasificación de características llamado importancia de características uno-contra-todos (OVA) para abordar este desequilibrio. En lugar de preguntar «¿Qué medidas son más útiles en general?», OVA formula esa pregunta por separado para cada tipo de ataque. Para cada clase (por ejemplo, tráfico normal, denegación de servicio o adivinación de contraseñas), se entrena un modelo de random forest para distinguir esa clase de todas las demás. Las puntuaciones de importancia incorporadas en el modelo revelan entonces qué medidas son especialmente útiles para esa clase concreta. Repitiendo este proceso clase por clase y tomando, para cada medida, la importancia máxima que alcanza en cualquier clase, el método construye un único vector de pesos que resalta características que importan para al menos un tipo de ataque—incluso si ese ataque es raro en los datos.
Enseñar a un autoencoder a centrarse en señales clave
Para aprovechar estos pesos, los investigadores diseñan un autoencoder basado en la importancia de características (FI-AE). Como un autoencoder convencional, FI-AE comprime la entrada en una representación de baja dimensionalidad («cuello de botella») y luego reconstruye los datos originales. La diferencia está en el objetivo de entrenamiento: en lugar de tratar todos los errores de reconstrucción por igual, el modelo utiliza un error cuadrático medio ponderado que multiplica el error de cada característica por su importancia basada en OVA. En términos sencillos, FI-AE es penalizado más por representar mal las medidas que son cruciales para distinguir ataques, y menos por detalles menos informativos. La arquitectura en sí es compacta, reduciendo los registros de red a solo 16 números y usando técnicas estándar como normalización por lotes, dropout y el optimizador Adam para mantener el entrenamiento estable.
Poner el método a prueba
El equipo evalúa FI-AE en tres conjuntos de datos de detección de intrusiones muy utilizados: NSL-KDD, UNSW-NB15 y CIC-IDS2017, que en conjunto cubren millones de conexiones y una amplia gama de tipos de ataque. Antes del entrenamiento, limpian los datos equilibrando distribuciones de clases extremadamente sesgadas, escalando características numéricas y codificando las categorías de forma que se preserve su relación con las etiquetas objetivo. Luego comparan tres canalizaciones que terminan con un clasificador random forest: una que usa PCA, otra que usa un autoencoder estándar y una que usa FI-AE para la reducción de dimensionalidad. En los tres conjuntos de datos, FI-AE ofrece de forma consistente mayor precisión y puntuaciones F1, con ganancias especialmente notables en ataques minoritarios y raros donde los métodos tradicionales tienden a fallar. 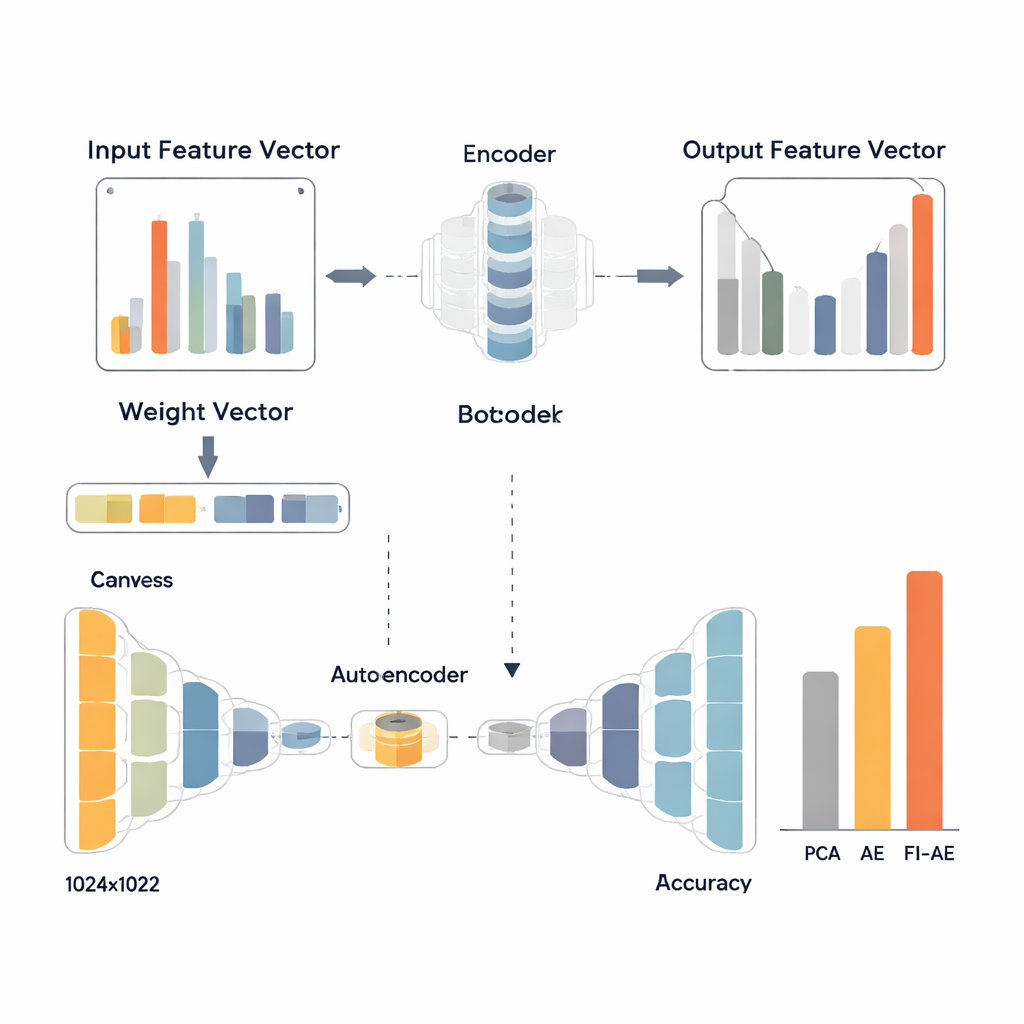
Qué significa esto para la seguridad cotidiana
Para el público general, el mensaje clave es que este trabajo ofrece una lente más selectiva para la supervisión de redes. En lugar de limitarse a comprimir datos para hacerlos más pequeños, FI-AE aprende a preservar las medidas que realmente importan para detectar distintos tipos de ataques, incluidos los raros que pueden ser los más dañinos. Con solo 16 características destiladas, los sistemas de detección de intrusiones basados en este enfoque pueden funcionar con mayor eficiencia mientras alcanzan o superan la precisión de detección del estado del arte. En la práctica, eso significa que las herramientas de seguridad pueden inspeccionar más tráfico, reaccionar más rápido y proporcionar mejor protección a los servicios digitales de los que la gente depende cada día.
Cita: Abdel-Rahman, M.A., Alluhaidan, A.S., El-Rahman, S.A. et al. Feature importance guided autoencoder for dimensionality reduction in intrusion detection systems. Sci Rep 16, 5013 (2026). https://doi.org/10.1038/s41598-026-36695-9
Palabras clave: detección de intrusiones, seguridad de redes, reducción de dimensionalidad, autoencoder, importancia de características