Clear Sky Science · es
Reconocimiento inteligente del comportamiento de los estudiantes para entornos de aprendizaje inteligentes
Por qué las aulas más inteligentes necesitan ver qué hacen los estudiantes
En muchas aulas, los docentes tienen que adivinar quién está siguiendo la clase, quién está perdido y quién está distraído en silencio. Este artículo explora cómo la inteligencia artificial puede reconocer automáticamente lo que hacen los estudiantes —como leer, escribir o levantar la mano— a partir de fotos ordinarias del aula. Al convertir imágenes crudas en medidas fiables de la actividad en clase, el sistema pretende ofrecer a los profesores retroalimentación en tiempo real sobre el compromiso, sin depender de observaciones que consumen tiempo ni de una vigilancia intrusiva.
De fotos desordenadas a instantáneas enfocadas
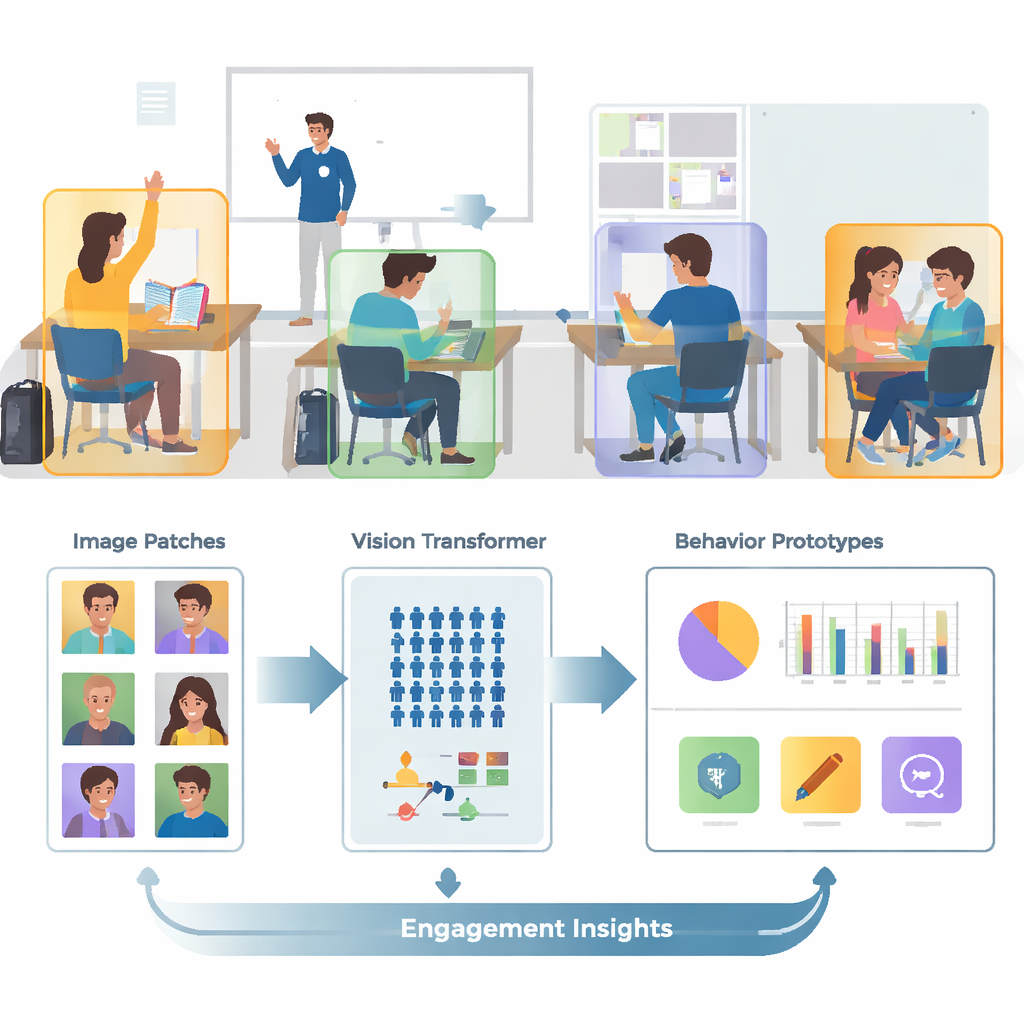
Las aulas reales están llenas de gente, son ruidosas y visualmente confusas. Una sola imagen puede contener docenas de estudiantes, cuerpos solapados y detalles de fondo que distraen, como paredes, pantallas y pósteres. Los autores se basan en una colección pública de imágenes llamada SCB‑05, que contiene miles de fotos de aula etiquetadas con comportamientos específicos —como levantar la mano, leer, escribir, estar de pie, hablar o interactuar en la pizarra—. En lugar de alimentar escenas completas al ordenador, el sistema usa primero archivos de anotación para recortar solo las regiones alrededor de cada estudiante o docente. Este paso de preprocesamiento elimina gran parte del desorden visual, de modo que el modelo pueda centrarse en la postura, la posición de las manos y otras pistas que distinguen un comportamiento de otro.
Cómo la IA aprende nuevos comportamientos a partir de muy pocos ejemplos
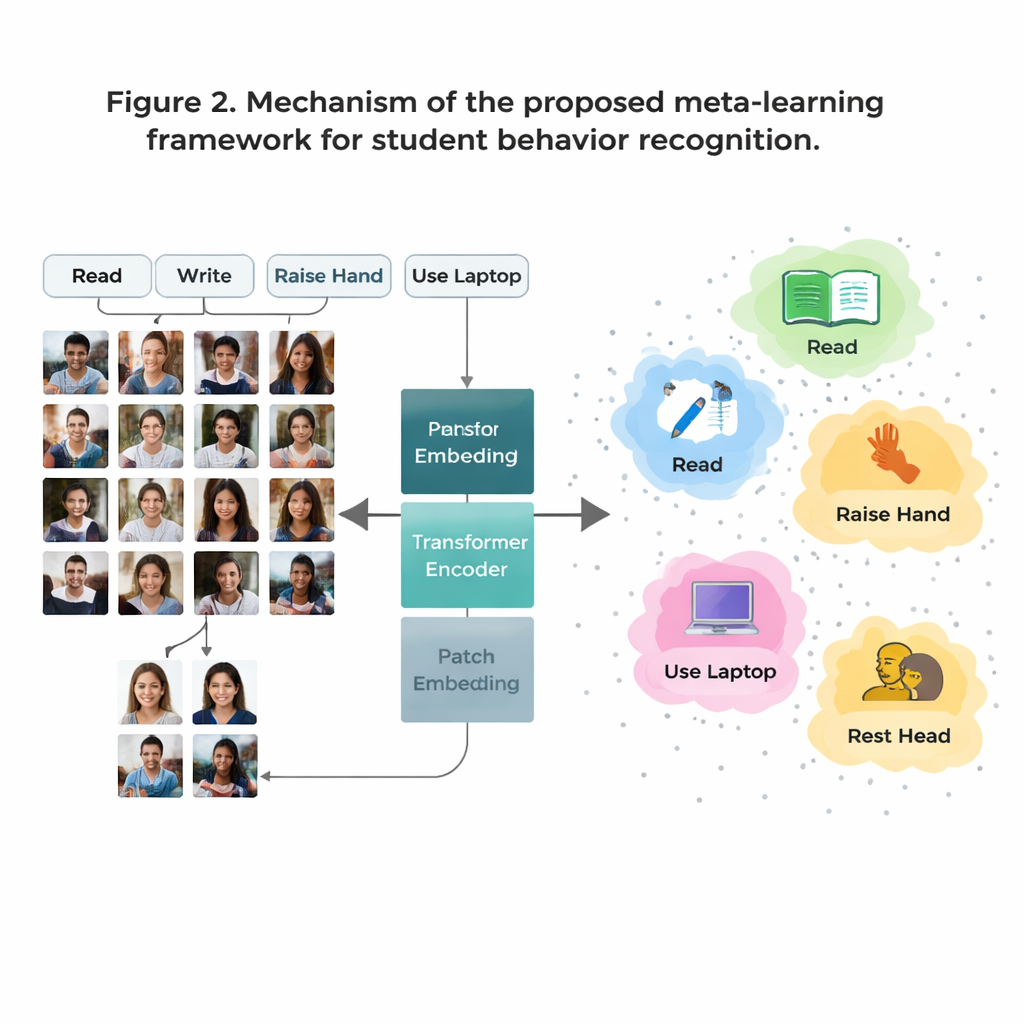
Un obstáculo importante es que algunos comportamientos en el aula son frecuentes en los datos (como leer), mientras que otros son raros (como breves interacciones sobre el escenario). Recopilar suficientes imágenes etiquetadas para cada comportamiento posible es costoso y plantea preocupaciones de privacidad. Para superar esto, los autores emplean una estrategia llamada «aprendizaje con pocos ejemplos», en la que el modelo se entrena para reconocer nuevas clases a partir de solo un puñado de ejemplos. Organizan el entrenamiento como muchas tareas pequeñas, cada una que contiene solo unos pocos comportamientos y unas pocas imágenes de muestra por comportamiento. Para cada tarea, el sistema forma un «prototipo» simple para cada comportamiento promediando su representación interna de esos ejemplos. Las imágenes nuevas se clasifican viendo a qué prototipo se parecen más, lo que permite que el modelo se adapte rápidamente incluso cuando los datos escasean.
Ver el aula completa, no solo pequeños detalles
Los sistemas de imagen tradicionales llamados redes neuronales convolucionales tienden a centrarse en patrones locales pequeños, como bordes o texturas. Eso puede ser limitante cuando dos comportamientos, como leer y escribir, se parecen mucho de cerca. Este trabajo sustituye esas redes antiguas por un Transformador de Visión, un modelo que divide cada imagen en parches y aprende cómo se relacionan todos los parches entre sí. Esta visión global ayuda al sistema a comprender diferencias sutiles en la postura y señales de largo alcance —como la relación entre una mano levantada y un docente al frente del aula. El equipo afina además el modelo entrenándolo para acercar imágenes del mismo comportamiento y separar las de comportamientos parecidos pero distintos, con énfasis adicional en los casos «difíciles» y confusos. Esto hace que el mapa interno de comportamientos sea más claro y más fácil de distinguir.
Qué tan bien funciona y por qué es importante
En el benchmark SCB‑05, el método propuesto alcanza alrededor del 91% de precisión global y puntuaciones sólidas en medidas más exigentes que contemplan datos desequilibrados. Comportamientos comunes como leer y levantar la mano se reconocen especialmente bien, mientras que los menos frecuentes, como escribir en la pizarra, siguen siendo más desafiantes pero aun así rinden mejor que con sistemas anteriores. Inspecciones visuales de los clústeres internos del modelo muestran que los distintos comportamientos forman grupos compactos y bien separados, lo que indica que la IA ha aprendido «firmas» distintas de las acciones en el aula. Al evaluarlo en otro conjunto de datos de aulas con ángulos de cámara y distribuciones diferentes, el rendimiento solo cayó ligeramente, lo que sugiere que la representación aprendida no está atada a una única sala o escuela.
Lo que esto significa para la enseñanza y el aprendizaje
En términos cotidianos, el estudio muestra que los ordenadores pueden identificar con fiabilidad muchos comportamientos clave de los estudiantes a partir de imágenes fijas, incluso cuando han visto solo unos pocos ejemplos de cada uno. En vez de sustituir a los profesores, estos sistemas podrían resumir discretamente quién está comprometido, quién busca ayuda con frecuencia o qué actividades tienden a perder la atención —todo ello sin rastrear la identidad de los alumnos. Con trabajo adicional sobre privacidad, equidad y análisis de vídeo a lo largo del tiempo, este tipo de IA consciente del comportamiento podría convertirse en un aliado potente para los educadores que diseñan entornos de aprendizaje más sensibles e inclusivos.
Cita: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
Palabras clave: aula inteligente, comportamiento del estudiante, visión por computador, aprendizaje con pocos ejemplos, transformador de visión