Clear Sky Science · es
Superresolución de imágenes de teledetección a escala continua entre dominios mediante aprendizaje de meta-pesos
Vistas más nítidas desde el espacio
Las imágenes satelitales impulsan todo, desde la planificación urbana hasta la respuesta a desastres, pero muchas fotos resultan más borrosas de lo deseable debido a limitaciones del hardware de la cámara y de la transmisión de datos. Este artículo presenta una nueva forma de convertir fotos satelitales borrosas en imágenes más nítidas a cualquier nivel de zoom elegido, usando una estrategia de aprendizaje que puede adaptarse al aspecto particular de la imagen aérea sin necesitar ser reentrenada para cada situación.
Por qué importan las imágenes satelitales más nítidas
Las imágenes de teledetección de alta resolución son cruciales para detectar objetos pequeños, seguir cambios en el terreno y cartografiar el uso del suelo en detalle. Sin embargo, los satélites del mundo real deben compensar resolución con coste, tamaño del sensor y ancho de banda, por lo que muchas imágenes llegan con una calidad inferior a la que los analistas preferirían. Las técnicas tradicionales de “superresolución” pueden mejorar la nitidez, pero suelen entrenarse para un zoom fijo, como exactamente el doble o cuádruple. Eso significa que los operadores necesitan modelos separados para cada nivel de zoom, lo cual es ineficiente e inflexible cuando se trabaja con muchos satélites y tareas variadas.
Más allá del zoom único para todos
Investigaciones recientes han desarrollado la superresolución “a escala continua”, que trata la imagen como una señal suave y puede generar salidas nítidas a cualquier factor de zoom con un solo modelo. La mayoría de estos métodos se construyeron y probaron con fotos cotidianas, no con datos satelitales. Normalmente deciden cómo mezclar la información de píxeles cercanos usando reglas geométricas fijas: esencialmente ponderando vecinos por distancia. Esto funciona razonablemente bien para escenas naturales como rostros o paisajes, pero las imágenes satelitales contienen edificios densos, texturas repetitivas y bordes bruscos que no siguen los mismos patrones. Cuando modelos entrenados con fotos naturales se aplican a vistas satelitales, sus suposiciones fallan y detalles como tejados, carreteras y vehículos no se recuperan fielmente.
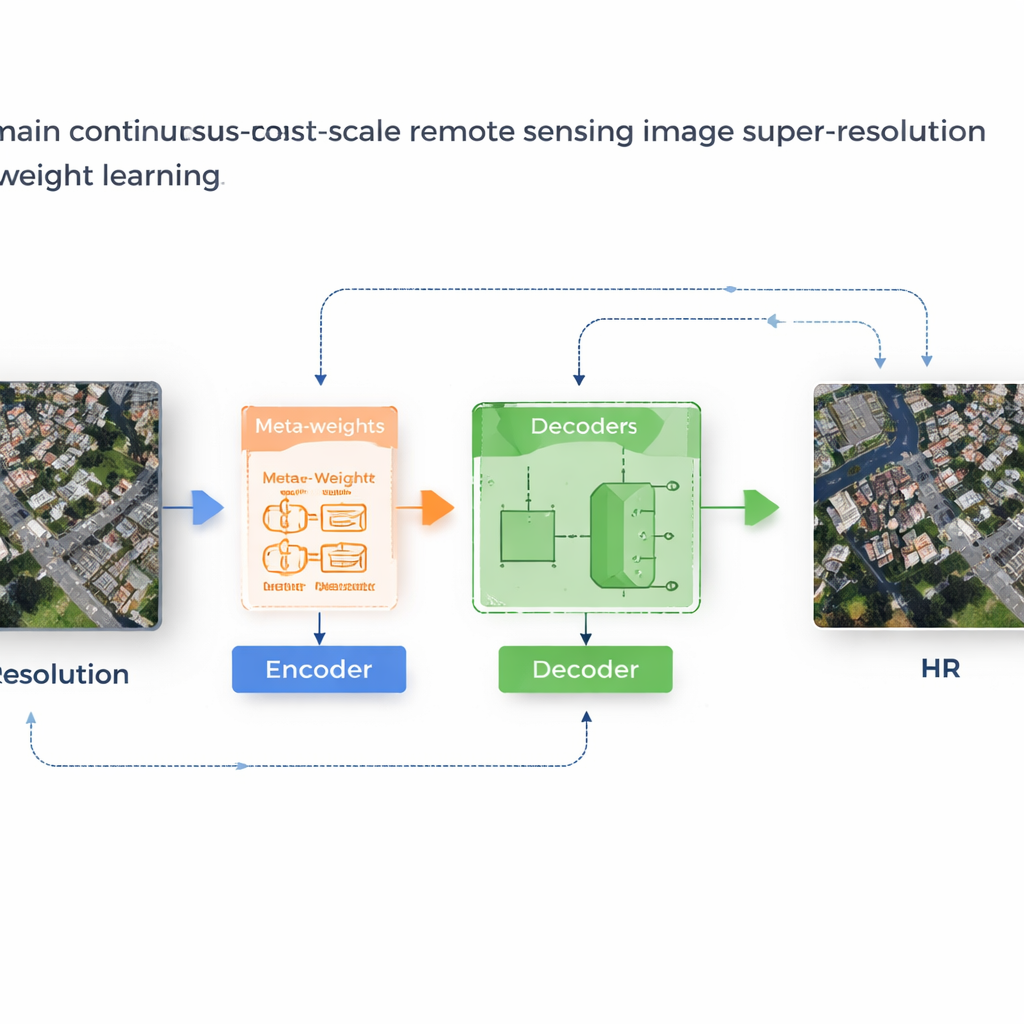
Un sistema de aprendizaje que adapta sus propias reglas
Los autores proponen un marco llamado MLIN (Implicit Neural Network basado en Meta‑Learning) para resolver este problema entre dominios. En lugar de diseñar a mano cómo deben combinarse las características de píxeles cercanos, MLIN aprende estas reglas de combinación a partir de datos. Mantiene un codificador de imágenes potente que fue entrenado originalmente con fotos naturales completamente congelado, de modo que pueda seguir extrayendo patrones visuales ricos sin verse distorsionado por los conjuntos de datos satelitales, que son más pequeños. Encima de esto, MLIN añade un nuevo “decodificador implícito” equipado con un módulo de meta‑aprendizaje. Para cada punto de la imagen de alta resolución que el modelo quiere reconstruir, este módulo observa las características circundantes y sus posiciones precisas y predice un conjunto de pesos suaves que indican al decodificador con qué intensidad debe usar cada vecino. En otras palabras, el sistema ya no asume que solo importa la distancia; permite que el contenido local —como texturas de tejados, campos o agua— modele la reconstrucción.
De bloques borrosos a estructuras nítidas
Técnicamente, el método funciona muestreando un pequeño vecindario 2×2 de características ocultas alrededor de cada ubicación objetivo en la imagen de salida. Una meta‑red combina entonces información sobre estas características, sus coordenadas relativas y el factor de zoom solicitado para elegir pesos que suman uno. El decodificador usa estos pesos para mezclar las predicciones de cada vecino y producir un valor de color final en esa ubicación. Debido a que esta ponderación se aprende, MLIN puede tratar regiones complejas —como bloques residenciales densos, puertos con barcos o aeropuertos con pistas— de forma muy distinta a áreas suaves como desiertos u océanos. Experimentos en dos conjuntos de datos satelitales ampliamente usados (WHU‑RS19 y UCMerced) muestran que MLIN ofrece de forma consistente puntuaciones numéricas de calidad más altas y detalles visiblemente más nítidos que varios métodos líderes de zoom continuo, tanto en niveles de zoom familiares como en ampliaciones extremas de hasta diez veces.
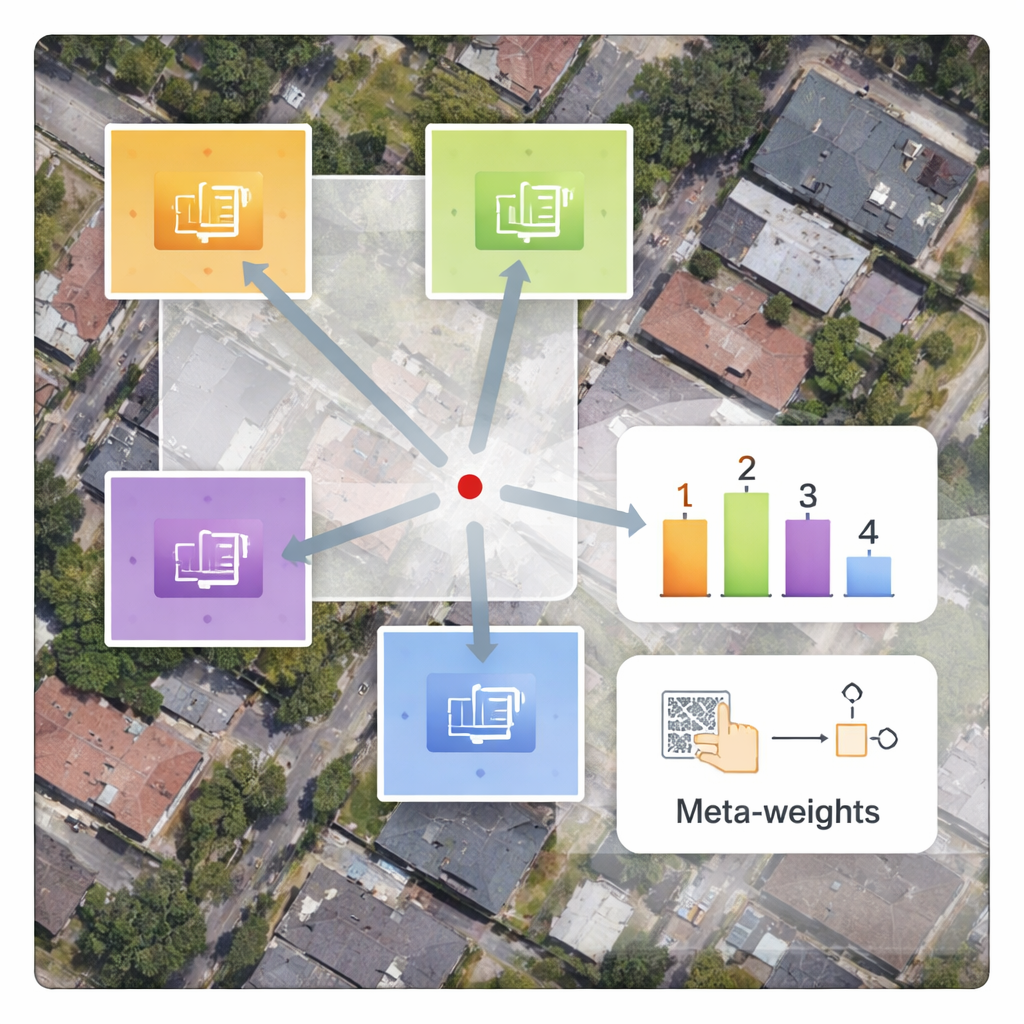
Entrenamiento más rápido sin retrasos adicionales
Una ventaja práctica del diseño es que solo el nuevo decodificador y la red de meta‑pesos necesitan entrenarse con imágenes satelitales, mientras que el gran codificador permanece fijo. Esto reduce enormemente el tiempo de entrenamiento en comparación con métodos que reentrenan todos los parámetros desde cero. Aunque la meta‑red introduce cómputo adicional, los procesadores gráficos modernos manejan estas operaciones de forma eficiente, por lo que el tiempo para procesar una sola imagen se mantiene casi igual que en enfoques existentes. Estudios de ablación —pruebas cuidadosas donde se eliminan o simplifican partes del sistema— confirman que la ponderación consciente del contenido es el ingrediente clave que mejora tanto la nitidez de los bordes como la continuidad de las texturas.
Ojos más claros sobre la Tierra
En términos sencillos, este trabajo muestra cómo reutilizar modelos potentes de imágenes entrenados con fotos cotidianas y adaptarlos de forma inteligente al mundo muy distinto de la imaginería satelital. Al permitir que el sistema aprenda a equilibrar la información de píxeles cercanos según lo que realmente hay en la escena, MLIN produce imágenes satelitales más claras y fiables a cualquier nivel de zoom con un solo modelo. Eso significa mejores herramientas para científicos, planificadores y equipos de respuesta a emergencias que dependen de vistas detalladas de nuestro planeta, todo ello manteniendo manejables las exigencias de cálculo y almacenamiento.
Cita: Zhang, Q., Ma, S., Tang, Y. et al. Cross-domain continuous-scale remote sensing image super-resolution via meta-weight learning. Sci Rep 16, 6073 (2026). https://doi.org/10.1038/s41598-026-36632-w
Palabras clave: superresolución satelital, imágenes de teledetección, meta-aprendizaje, zoom a escala arbitraria, mejora de imágenes