Clear Sky Science · es
Evaluación detallada de los grandes modelos de lenguaje en medicina usando modelado diagnóstico cognitivo no paramétrico
Por qué esto importa para las futuras visitas al médico
Los sistemas de inteligencia artificial que hablan y escriben, conocidos como grandes modelos de lenguaje, están pasando rápidamente de los laboratorios de investigación a los hospitales. Ya pueden ayudar a los médicos a interpretar historiales complejos, sugerir tratamientos y responder preguntas médicas. Pero la mayoría de las pruebas a estos sistemas ofrecen solo una puntuación global, parecido a la nota de un examen final, que puede ocultar puntos ciegos peligrosos. Este estudio presenta una forma nueva de analizar esas puntuaciones y revelar exactamente qué áreas de la medicina entienden realmente estos modelos y dónde todavía podrían poner en riesgo a los pacientes.
Mirar más allá de una única nota de examen
Hoy en día, la mayoría de la IA médica se juzga por cuántas preguntas responde correctamente en exámenes modelados según pruebas de licencia médica. Ese enfoque es sencillo pero tosco. Un modelo puede obtener una nota global alta y, sin embargo, ser débil en un campo crítico como el análisis del ritmo cardíaco o las enfermedades hepáticas. En clínicas reales, esas lagunas pueden tener consecuencias de vida o muerte. Los autores sostienen que el uso seguro de la IA en medicina exige una evaluación más profunda y detallada, capaz de mapear un perfil de habilidades concreto en lugar de entregar una única calificación que podría ser engañosa.

Una forma más inteligente de evaluar el conocimiento médico
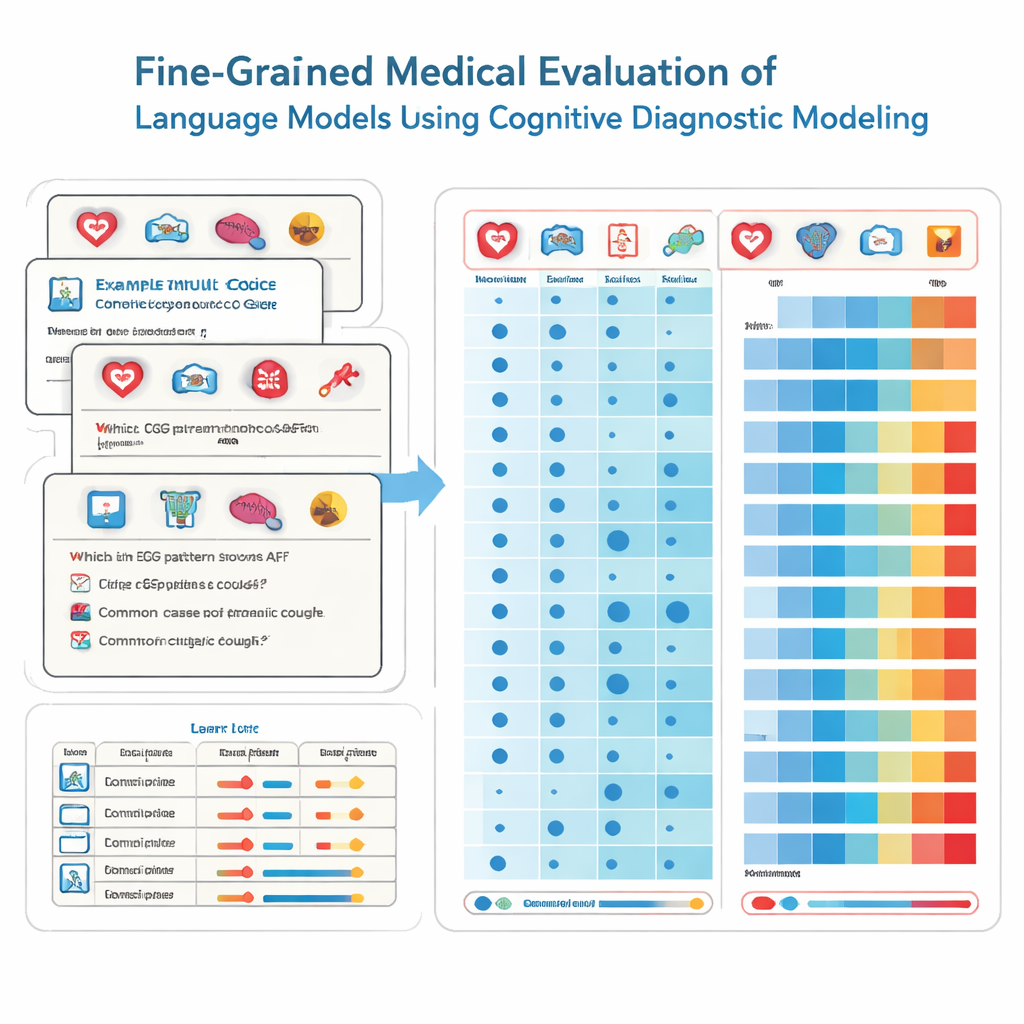
Para lograrlo, los investigadores recurren a herramientas de la psicología educativa llamadas evaluación diagnóstica cognitiva. En lugar de tratar cada pregunta del examen como si midiera la misma habilidad vaga, este método descompone el conocimiento médico en bloques específicos, como cardiología, radiología o atención de urgencias. Cada pregunta de opción múltiple se etiqueta con la combinación exacta de habilidades que requiere. Utilizando una técnica estadística no paramétrica, el equipo compara cómo responde un modelo a miles de preguntas con patrones de respuesta ideales. A partir de ello infieren si el modelo ha “dominada” cada habilidad subyacente, similar a cómo un informe detallado muestra fortalezas y debilidades por asignatura.
Sometiendo 41 modelos de IA a un examen médico
El equipo evaluó 41 modelos de lenguaje de uso general, incluidos sistemas comerciales y modelos de código abierto, en 2.809 preguntas cuidadosamente revisadas extraídas de un banco de pruebas médico nacional chino. Estas preguntas cubren 22 subdominios médicos y están diseñadas para estudiantes a punto de presentarse al examen de licencia de médico. Cada pregunta tiene una única respuesta correcta y está etiquetada por expertos para indicar qué especialidades abarca. Con su método diagnóstico, los investigadores estimaron, para cada modelo, cuántos de estos 22 atributos médicos había dominado de forma efectiva, no solo cuántas preguntas respondió correctamente por casualidad.
Buen conocimiento general, pero puntos ciegos marcados
Los resultados son impresionantes y preocupantes a la vez. Los modelos con mejor rendimiento, como varios sistemas comerciales líderes, contestaron correctamente la mayor parte de las preguntas y mostraron dominio en 20 de los 22 dominios médicos. En conjunto, el rendimiento fue excelente en muchas especialidades comunes, alcanzando dominio completo en 15 áreas, incluidas cardiología, dermatología y endocrinología. Sin embargo, el análisis detallado dejó al descubierto brechas notables en otras áreas. Radiología quedó rezagada con tasas de dominio mucho más bajas, y dos subdominios —ECG & hipertensión & lípidos y trastornos hepáticos— no fueron dominados por ningún modelo. Es importante destacar que algunos modelos más pequeños compartían las mismas habilidades dominadas que otros mucho mayores, lo que revela que el tamaño por sí solo no garantiza un conocimiento médico amplio y fiable.
Elegir la herramienta adecuada para cada tarea
Estos perfiles detallados importan porque modelos con puntuaciones globales muy similares pueden presentar patrones de fortalezas y debilidades muy distintos. Un sistema puede ser fuerte en neurología pero débil en farmacología, mientras que otro muestra el patrón contrario. Para los responsables hospitalarios, esto significa que no pueden elegir con seguridad un asistente de IA basándose solo en su nota de examen o en el número de parámetros. En su lugar, necesitan resultados diagnósticos como los de este estudio para asignar cada modelo a tareas clínicas específicas y diseñar flujos de trabajo donde especialistas humanos verifiquen las salidas de la IA en las áreas de alto riesgo donde el modelo sea débil.
Qué significa esto para pacientes y clínicos
En términos sencillos, el estudio concluye que una “notaza” alta en pruebas médicas no garantiza que un sistema de IA sea seguro en todas las áreas de la medicina. El nuevo enfoque funciona más como un chequeo médico exhaustivo para la propia IA, revelando qué “órganos” —en este caso, especialidades médicas— están sanos y cuáles necesitan atención. Al descubrir lagunas ocultas en áreas críticas como la interpretación de ECG y las enfermedades hepáticas, el método ofrece a hospitales, reguladores y desarrolladores una hoja de ruta práctica: usar modelos solo donde se haya demostrado su solidez, mantener a los humanos en la cadena de decisión donde persistan debilidades y enfocar la formación futura en los puntos ciegos más riesgosos. Este tipo de evaluación detallada, sostienen los autores, no es solo útil: es imprescindible antes de confiar en la IA para el cuidado de los pacientes.
Cita: Zheng, T., Liu, J., Feng, S. et al. Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling. Sci Rep 16, 6460 (2026). https://doi.org/10.1038/s41598-026-36627-7
Palabras clave: IA médica, grandes modelos de lenguaje, seguridad clínica, evaluación de modelos, pruebas diagnósticas