Clear Sky Science · es
Optimización multitarea y estabilidad de convergencia con aprendizaje de características jerárquico para optimización auto‑guiada
IA más inteligente que puede manejar muchas tareas a la vez
Las aplicaciones modernas dependen cada vez más de la inteligencia artificial que debe realizar varias funciones simultáneamente—por ejemplo, comprender imágenes y texto juntos, apoyar decisiones médicas o ayudar a los coches a percibir la carretera. Pero cuando un modelo de IA aprende demasiadas habilidades a la vez, su entrenamiento puede volverse inestable y las habilidades pueden interferir entre sí. Este trabajo presenta un nuevo marco de aprendizaje profundo, denominado Arquitectura Profunda Unificada Multitarea y Multivista (UMDA), diseñado para permitir que un único modelo aprenda de muchos tipos de datos y resuelva múltiples tareas sin confundirse ni volverse inestable.
Por qué la IA multi‑habilidad actual suele tener problemas
La mayoría de los sistemas actuales que aprenden varias tareas (aprendizaje multitarea) o combinan varios tipos de datos, como imágenes y texto (aprendizaje multivista), sufren tres problemas principales. Primero, distintas tareas pueden competir entre sí durante el entrenamiento: mejorar el rendimiento en una tarea puede dañar silenciosamente a otra, un problema conocido como transferencia negativa. Segundo, simplemente apilar u promediar información de distintas fuentes de datos suele perder relaciones sutiles pero importantes entre ellas. Tercero, el propio proceso de entrenamiento puede volverse inestable, con grandes oscilaciones en la dirección de actualización de los parámetros del modelo. Estos problemas son especialmente graves en entornos del mundo real como el diagnóstico médico o la inspección industrial, donde los datos son complejos y las decisiones deben ser fiables.
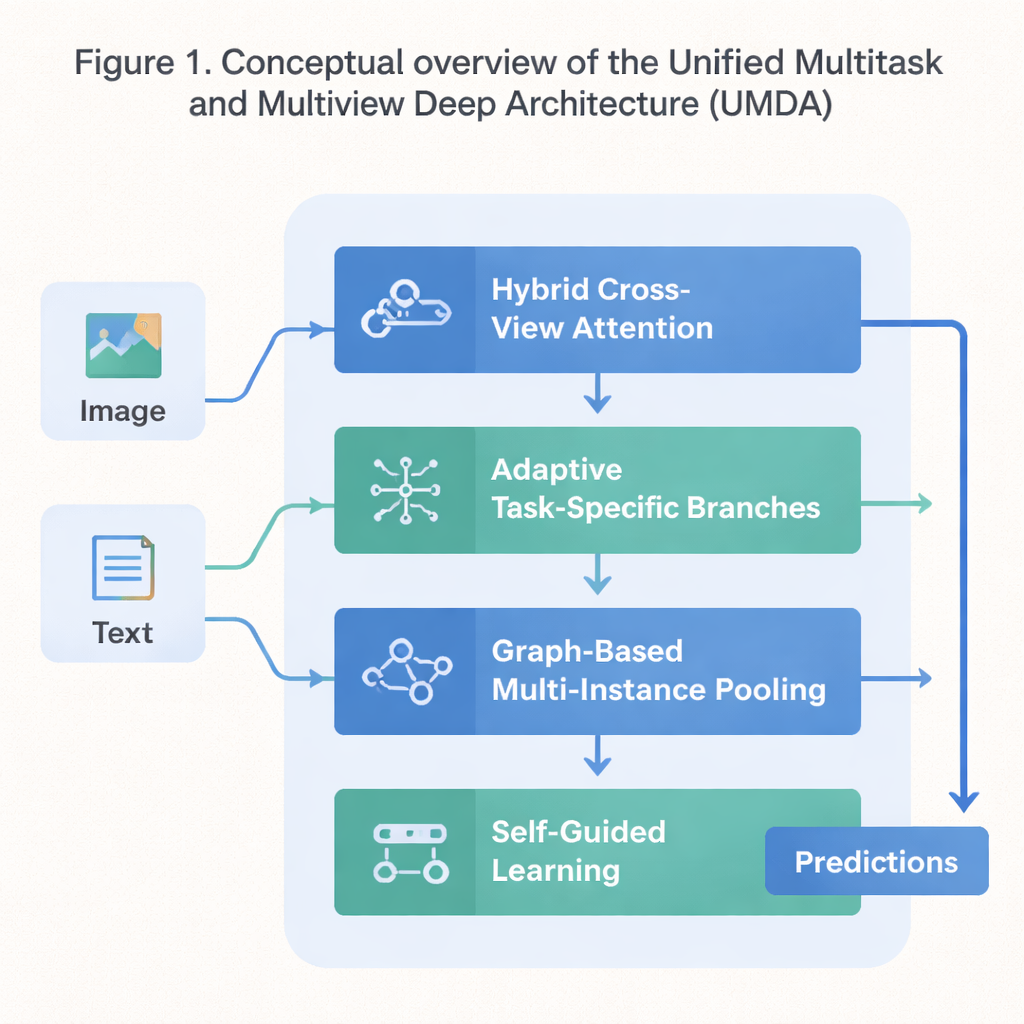
Un plan en cuatro partes para un aprendizaje cooperativo
UMDA aborda estas debilidades dividiendo el proceso de aprendizaje en cuatro partes estrechamente conectadas que comparten información de forma controlada. La primera parte, llamada Atención Cruzada Híbrida entre Vistas, examina distintas vistas del mismo dato—como texto e imágenes que describen una película—y aprende qué vista debe influir en otra en cada paso. Emplea herramientas matemáticas que fomentan que el modelo evite depender en exceso de una única vista, que mantenga cada vista distintiva y, al mismo tiempo, que las vistas mantengan una concordancia general. En términos sencillos, enseña al modelo a atender a todos sus “sentidos” sin permitir que uno ahogue a los demás.
Mantener las tareas distintas pero aún cooperativas
La segunda parte, Ramificación Adaptativa Específica por Tarea, separa el conocimiento genérico que comparten muchas tareas del conocimiento particular que cada tarea necesita de forma única. En lugar de obligar a todas las tareas a usar exactamente las mismas características, UMDA construye “ramas” separadas para cada tarea que aún pueden comunicarse entre sí mediante conexiones ponderadas cuidadosamente. Términos de penalización adicionales en el objetivo de entrenamiento empujan a que estas ramas sean lo suficientemente diferentes para especializarse, pero no tanto que se distancien y dejen de cooperar. Este equilibrio ayuda a reducir la interferencia perjudicial entre tareas sin impedir que se beneficien mutuamente de lo que aprenden.
Ver la estructura en colecciones de ejemplos
Muchos conjuntos de datos reales vienen en forma de colecciones de elementos relacionados—por ejemplo, múltiples parches de imagen de una misma lámina médica o muchos fotogramas de un vídeo. La tercera parte de UMDA, llamada Agrupación Multi‑instancia basada en Grafos, modela explícitamente las relaciones entre estos elementos tratándolos como nodos de una red. Conecta elementos similares, permite que la información fluya a lo largo de esas conexiones y luego resume toda la colección en una representación compacta. Una regularización adicional empuja a los elementos cercanos a ponerse de acuerdo entre sí sin perder la suficiente diversidad, lo que permite al modelo capturar patrones estructurales que un simple promedio pasaría por alto.
Entrenamiento autoajustable para un progreso estable
La parte final, Aprendizaje Auto‑Guiado, se centra en cómo se entrena el modelo más que en su estructura interna. Mide continuamente cuán fuertes y cuán similares son las señales de entrenamiento de cada tarea y ajusta automáticamente la velocidad de aprendizaje para cada una. También suaviza y repondera los gradientes—las señales que indican al modelo cómo cambiar—de modo que las tareas con objetivos similares se refuercen mutuamente y las tareas que tiran en direcciones muy distintas no desestabilicen el entrenamiento. Al probarse en un conjunto de datos estándar que mezcla sinopsis de películas y carteles, UMDA logró una mayor precisión media que una docena de métodos de última generación, mantuvo la relación entre vistas más consistente y redujo una medida clave de inestabilidad de entrenamiento en más de la mitad.
Qué significa esto para los sistemas de IA del mundo real
Para el público general, el mensaje clave es que UMDA ofrece una forma de construir modelos de IA únicos que pueden manejar múltiples tipos de datos y objetivos con mayor fiabilidad. Al enseñar al modelo cuándo compartir información y cuándo mantenerla separada, y permitiéndole ajustar automáticamente cómo aprende, el marco proporciona mejores predicciones, representaciones internas más coherentes y un entrenamiento más suave. Esto lo convierte en un bloque de construcción prometedor para sistemas futuros en medicina, conducción autónoma y otras aplicaciones complejas donde la IA debe interpretar muchas señales a la vez sin perder el equilibrio.
Cita: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
Palabras clave: aprendizaje multitarea, IA multimodal, estabilidad del aprendizaje profundo, redes de atención, redes neuronales de grafos